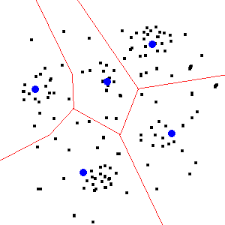
K-means is one of the most popular unsupervised learning techniques due to its simplicity and efficiency. It is an iterative and unsupervised clustering algorithm used in machine learning.
A cluster is a group of data points that are grouped together due to similarities in their features.The k-means clustering algorithm assigns data points to categories, or clusters, by finding the mean distance between data points. It then iterates through this technique in order to perform more accurate classifications over time.