By Susan Buck
With many programming languages, there’s a processor or compiler that runs our code and alerts us to problems such as missing syntax, mispelled properties, etc.
For simple syntax languages like HTML, however, we don't have these same automatic checks. Our processor, the browser, just makes its best guess about what we mean when it encounters an error. Sometimes this best guess is good enough that we don't realize there’s an issue.
However, just because we can't see issues, doesn’t mean we don't want to find and fix them. If the errors are left in place, it could lead to problems in ways we don’t realize - such as issues with accessibility, search engine parsing, or incompatibilities with different browser types. Furthermore, it can also cause biger problems down the road if our pages grow more complex. For more reasons on why to validate, check out Why validate?.
Given this, we need an efficient way to track down issues in our HTML, and one such tool to help us do that is W3C’s HTML validator. The W3C validator is a free service provided by the W3C, or World Wide Web Consortium, an “international community that develops open standards to ensure the long-term growth of the Web.” -w3.org.
To test drive the W3 validator, we’re going to use the following code, which has some errors sprinkled throughout:
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset='utf-8'>
</head>
<body>
<h1><img src='../images/scientist-spotlight-logo.png' width='243' alt='Scientist Spotlight Logo'></h1>
<section>
<em><h2>Suggest a Scientist</h2></em>
<p>
Do you have an idea for a famous, notable, or otherwise inspirational scientist we should spotlight?
</p>
<p>
If so, please email us at <strong>scientists@thewcc.com</strong> with a brief bio!
</p>
</section>
<footer>
Created by <a href='http://thewcc.com'>The WCC</a>
</body>
</html>Before we run this code through the validator, skim through it and see how many issues you can identify.
There are three ways to run your code through the W3C Validator:
- Validate by URI: Enter a URL to a web page that is online; the validator will read and validate the source of that page
- Validate by File Upload: Upload a
.htmlfile - Validate by Direct Input: Paste your HTML code from your clipboard
For this example, we’ll utilize method #3.
On the W3C Validator home page, choose the Validate by Direct Input option and paste in the code provided above, then click Check.
Upon validating this code, it should come back with 6 items: 5 errors, and 1 warning.
Let’s go through each one...

The first error tells us that we forgot to put the title element in the head of our page. The title element is a key part of the metadata that a page needs, so this error should definitely be fixed (ref: MDN: Document Metadata (Header) element.

The second error tells us we forgot the alt attribute on our img element. The alt attribute is an important part of non-decorative images, as it provides context for screen readers and search engines (ref: MDN: img attributes). This should be fixed by adding an alt attribute with descriptive details about the image.

The third item is a warning, telling us the h1 is empty. Looking at the code, the h1 is not actually empty - it contains a logo - it just doesn’t contain any text. There’s lots of opinions about whether placing a logo/image in a heading is good/bad practice (ref: https://wehavezeal.com/blog/web-development/2016/01/12/should-i-use-the-h1-tag-for-my-website-logo) so this warning is up for debate and something you can decide to ignore or address.
The fourth error is flagging the fact that we nested a h2 (block element), inside an em (inline element), which is a no-no. Block elements can contain inline elements, but inline elements can not contain block elements. To fix this, it makes sense to remove the em element, as the h2 heading already provides emphasis. Any additional emphasis/styling can be accomplished with CSS.
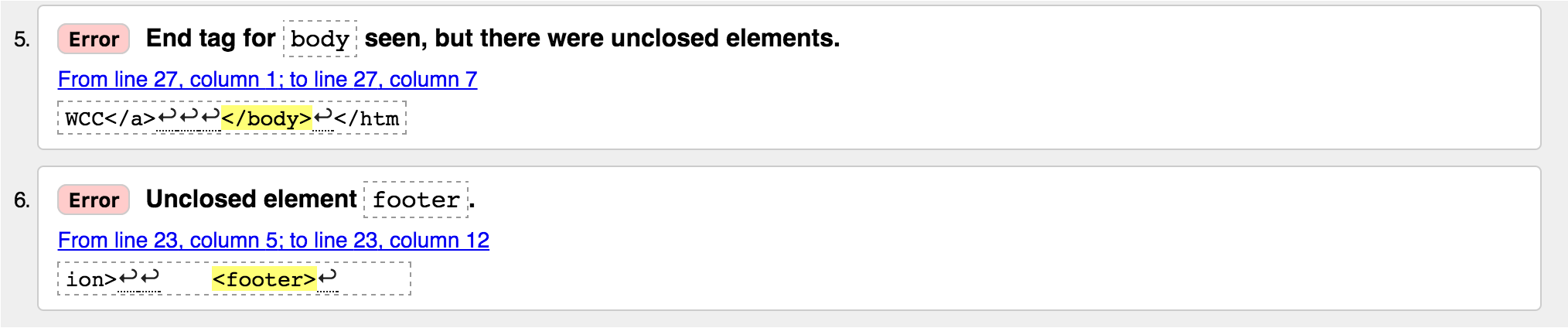
Both the fifth and sixth error are related to the same problem: we’re missing a closing footer tag on the footer element.
<footer>
Created by <a href='http://thewcc.com'>The WCC</a>- We didn’t see this in the example above, but sometimes one problem can actually propagate multiple errors throughout a page. Given this, it can be useful to fix individual errors and then revalidate to see if it resolves any other errors you might have had.
- It's a good idea to periodically validate your code as you’re building a page. It’s easier to squash problems as you go and you’re working with limited content, then to wait to the end and face a long list of errors.
- Sometimes the validator will throw errors and warnings that you don’t necessarily need/want to fix, such as the empty
h1warning we encountered above. Given this, that the validator serves as a general guide, and there may be times you wish to ignore its suggestions/flags. - The validator is only designed to check HTML code. Therefor, if you’re working with a server-side language such as PHP, you can not copy your raw source code into the validator as it will not understand the PHP syntax in your code. Instead, you must provide the validtor with the rendered HTML code. This can be done by copying the rendered HTML of your page using your browser's View Source feature (ref: How to view the HTML source code of a web page) and validating by direct input. Alternatively, if your page is online, you can use the validator’s Validate by URI option.
- Fix the errors that the w3 Validator identified in the buggy code, and then run it through the validator again. If necessary, repeat this process until validation passes with no errors or warnings.
- Using the Validate by URI option, plug in the URL of one of your favorite web site and see how their code stands up to the validator.