MessagePack for Ruby の新版をリリースしました!
- さらなる高速化
- APIの追加
- 新しいAPIリファレンス
すべてのコードをゼロから再設計し、 シリアライズの大幅な高速化 を達成しました。 ruby-serializers を使って過去のバージョン(v4)と比較したところ、Twitter, 画像, 整数列, 地理データ, 3Dモデル のすべてのデータセットで高速化しました。
Twitter APIで返されるJSONを使ったベンチマークテストの結果です。 msgpack(old)(v4)と比べ、シリアライズが4倍以上高速化しました。
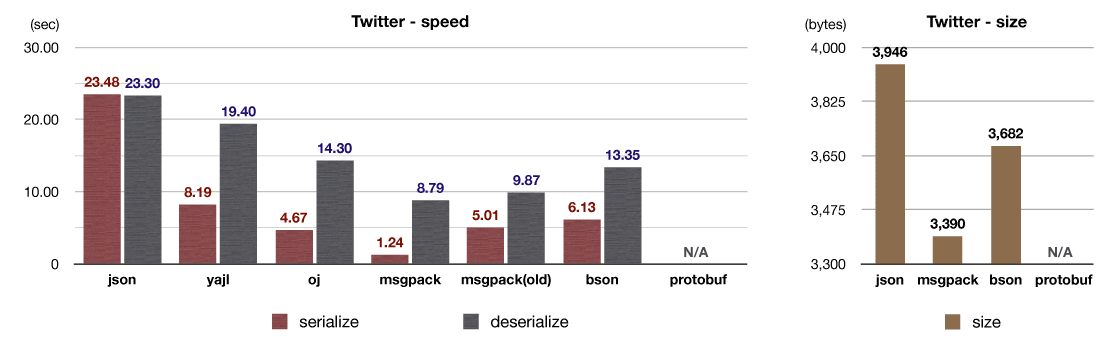
msgpack-ruby v5では、典型的な用途ではシリアライズ結果は数KB以下に収まる点に着目し、4KBの固定長メモリプールを導入しました。これによって負荷の高いmalloc(3)の呼び出しを削減できました。 このメモリプールはプログラム全体で共有されるので、インスタンスを使い回すなどの面倒なコードを実装する必要はありません。すべてのシリアライズが自動的に高速化されます。
また、メモリプールによってメモリを確保/解放する回数が減ることで、断片化が起きにくくなるメリットもあります。長時間動作し続けるサーバプログラムでは、断片化はメモリ消費量の増大に繋がり、ひどい場合には定期的に再起動してメモリを解放してやらないといけないという面倒な運用が必要になってしまうので、無視できない問題です。
ちなみに、メモリアロケータ自体を置き換えることで断片化を改善する方法もあります。例えば jemalloc を使うと、Ruby on Rails のメモリ使用量を10〜20%ほど改善できるようです。
- 'JE' GEM: INJECT JEMALLOC(3) INTO YOUR RUBY APP IN 3 MIN
- mod_mrubyのメモリ問題をvalgrindで調査の上jemallocで改善
- A Scalable Concurrent malloc(3) Implementation for FreeBSD
これは6KB程度の画像(バイナリデータ)と多少のメタデータからなるデータセットを使ったベンチマークテストの結果です。
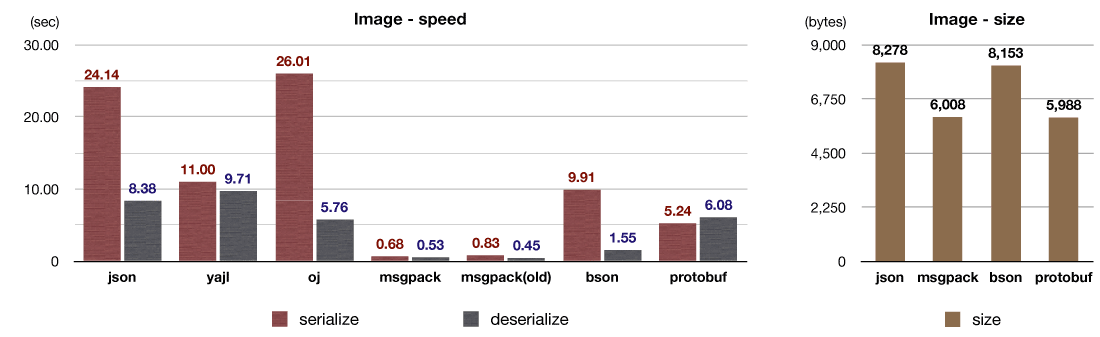
ほとんどのデータは4KB以下に収まる一方で、画像などのバイナリデータを含むデータは非常に大きくなることがあります。 そこでmsgpack-rubyでは以前から、一定以上の大きさのバイナリデータをコピーせずにデシリアライズすることができます。これにはRuby(CRuby)のStringクラスに実装されているCopy-on-Write機能を利用しています。
Copy-on-Writeはその名の通り、データを複製したタイミングでは実際にコピーを行わずに、データが(破壊的に)変更されるタイミングで初めてコピーを行うテクニックです。例えば画像データをデシリアライズする場合、デシリアライズ元のデータを破壊的に変更することも、デシリアライズされた画像データを破壊的に変更することも、まずありません。データをそのままの形で使い、使い終わればそのまま解放するのが一般的です。このためCopy-on-Writeによってコピーを抑制し、大幅に高速化することができます。
(※JSONではバイナリデータを扱うことができないので、このテストではbase64していますが、性能測定にはbase64でエンコード/デコードする時間は含まれていません)
整数の配列を使ったベンチマークテストの結果です。
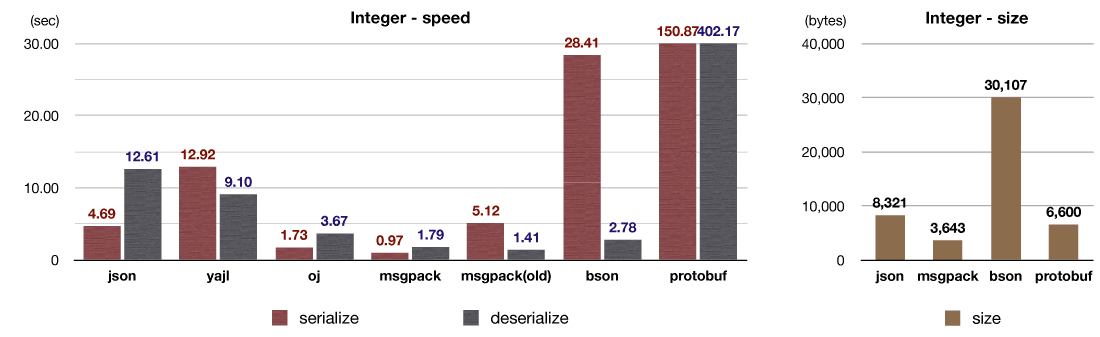
シリアライザの主なオーバーヘッドは、メモリ確保、データのコピー、そして関数呼び出し(※Cの関数からCの関数の呼び出し)です。関数呼び出しのコストは意外に大きく、関数を一つインライン展開するだけで性能が2倍,3倍になることもあります。 以前のmsgpack-rubyは、RubyのStringオブジェクト(struct RBString)にデータを追記していく実装でしたが、Stringへの追記には必ず関数呼び出しが伴います。この関数は1つのオブジェクトをシリアライズするたびに1回〜2回呼ばれるので、特に細かいオブジェクトを大量にシリアライズする場合に深刻なオーバーヘッドになります。
v5では、独自にバッファを実装してシリアライザと密結合化することにより、コンパイラが関数をインライン展開できるようにしました。これによって整数や浮動小数点数のシリアライズを大幅に高速化しています。この整数列のテストでは、実に5倍以上の高速化を達成しています。
別のデータセットとして、地理的な座標や領域を表現するデータ形式である GeoJSON を使ったベンチマークテストを用意しました。
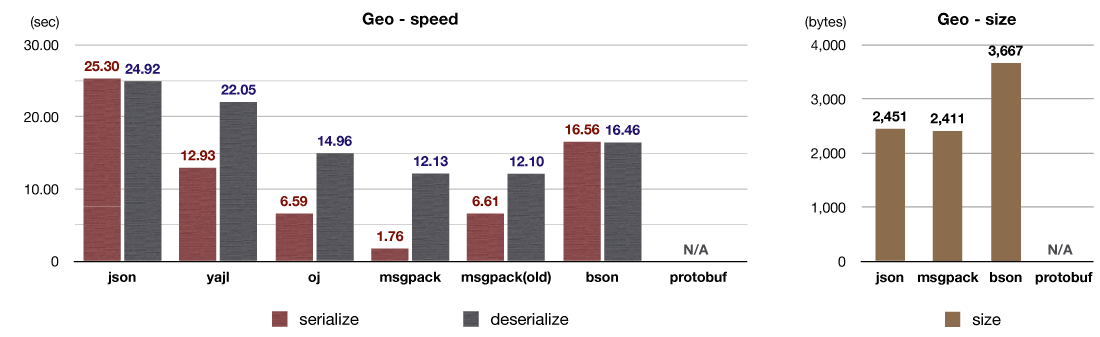
GeoJSON は、Twitterのtimelineと同じようにHashと文字列が大半のデータですが、浮動小数点数や配列も含まれています。 シリアライズ速度の高速化には、関数呼び出しのコスト削減と、メモリプールの導入が効いています。
特殊な事例として、3Dモデルを使ったベンチマークテストも用意しました。サンプルデータは、3DモデラのBlenderからWebGLへとデータを書き出すプラグインである blender-webgl-exporter からダウンロードしました。このデータセットには大量の浮動小数点数が含まれています。
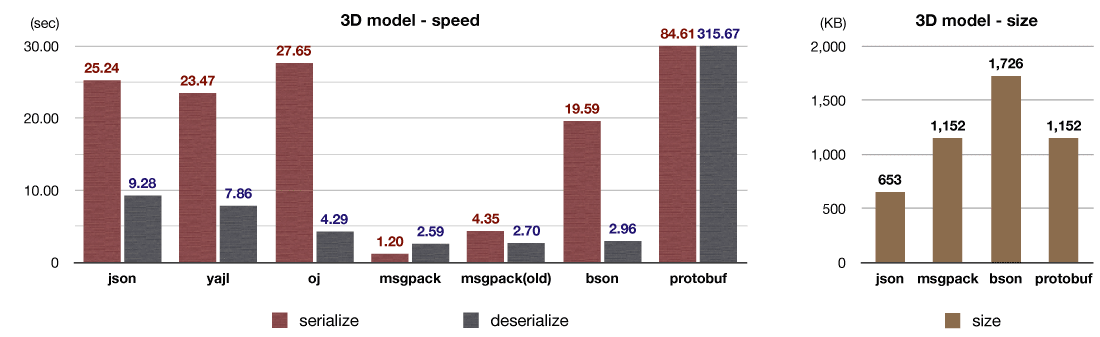
(※JSONよりもmsgpackやbsonなどのバイナリ形式の方がデータサイズが大きくなっています。これはJSONでは小数を10進数(decimal)で表現している一方、バイナリ形式では2進数(double)で表現しているためで、それぞれが表現しているデータは厳密には別物です)
MessagePack は、JSONと同じようにカジュアルな使い方ができるライブラリである一方で、"本気" なアプリケーションにも使えるバイナリシリアライザです。 例えば Treasure Data では、MessagePack をデータ表現形式に採用したカラム指向ストレージを実装しました。また、ログ収集システムの Fluentd は、イベントストリームの内部表現に MessagePack を使用しています。あの Pinterest も MessagePack + memcached を使っており、Redis にもMessagePackが含まれています。
MessagePack には「サイズが小さい」とか「バイナリを扱える」といった利点がありますが、それによってカジュアルなツールのみならず、性能が重要になるプロジェクトまで幅広く使えるようになっています。何が起こるか分からないこの世の中で、新たにソフトウェアを設計する場合、まずは動くものを作ってから拡張していくのが正解です。MessagePack を使っておけば、プロトコルやファイルフォーマットなどの他のプログラムとのインタフェースになるクリティカルな部分で互換性を維持したまま拡張し続けられます。
さて、そんな本気なアプリケーションのために役立つAPIを追加しました。
デコードはするがオブジェクトを生成しない、skip メソッドを追加しました。
デシリアライズ処理のオーバーヘッドの大半はオブジェクトの生成です。オブジェクト生成を省略すると軽く5倍くらい高速化します。
例えば、デシリアライズ処理を遅延評価し、実際にオブジェクトに対するアクセスが行われたタイミングで初めてデシリアライズするようにすると、アクセスされなかったオブジェクトはスキップできます。このようなケースで Unpacker#skip を使うと、性能向上を期待できます。
MessagePack の Array フォーマット は、まず最初に要素数が格納され、後にオブジェクトが続く構造になっています。 言い換えれば、Array のヘッダ部分を取り除けば、オブジェクトのシーケンスとして扱うことができます。オブジェクトのシーケンスは、ストリームデシリアライザを使って順々に取り出すことができます。このテクニックは、メモリに収まりきらないような(あるいはメモリを圧迫してしまうような)巨大な配列を扱いたい場合に有効です。
また逆に、オブジェクトのシーケンスにヘッダを取り付ければ、配列としてシリアライズすることが可能です。事前に要素数が分からない多数のオブジェクトを配列としてシリアライズしたい場合に有効です。
Unpacker#read_array_header と Packer#write_array_header(n) を使うことで、これらのテクニックを利用することが可能です。
MessagePack::Buffer クラスは、シリアライズ後のバイナリ列や、デシリアライズ前のバイナリを直接に操作するクラスです。MessagePackストリームの中に独自のヘッダやデータ構造が混じっていたり、あるいはMessagePackでサポートされないアプリケーション独自の型を混入させたいケースにも対応できます。
また、このBufferの内部構造はチャンクのキューになっており、末尾への追記や先頭からの切り出しを高速に実行することが可能です。前述した固定長メモリプールを使用しており、小規模なデータの読み書きが特に高速です。 さらに、できるだけデータ(Stringオブジェクト)をコピーせずにキューに組み入れる最適化を導入しているので、Rubyで数MB級のバイナリデータを結合したり操作したくなった場合にも有効です。
固定長メモリプールの導入、バッファの密結合化による関数呼び出しオーバーヘッドの削減によって、シリアライズ速度を大幅に改善しました。
また MessagePack::Buffer や Unpacker#read_array_header などのAPIを新たに追加しました。
ベンチマークに使った環境は以下の通り:
- ruby-serializers
- OS: Mac OS X 10.8.2
- CPU: Intel COre i7 2.7GHz
- Memory: 16GB 1600MHz DDR3
- ruby 1.9.3p194 (2012-04-20 revision 35410) [x86_64-darwin11.4.0]
- ruby-serializers
- gem
- json 1.7.5
- yajl-ruby 1.1.0
- oj 1.4.7
- msgpack 0.5.0
- msgpack 0.4.7 (old)
- bson_ext 1.8.0
- protobuf 2.5.3
リンク: