Created
August 19, 2012 23:20
-
-
Save terrancesnyder/3398489 to your computer and use it in GitHub Desktop.
hyperloglog_test.js
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| /** | |
| * Author - Shutupandcode - Terrance A. Snyder (http://www.shutupandcode.net & http://www.terranceasnyder.com) | |
| * w/ http://stackoverflow.com/users/36174/actual | |
| * | |
| * HyperLogLog implementation ripped from: | |
| * http://stackoverflow.com/questions/5990713/loglog-algorithm-for-counting-of-large-cardinalities | |
| * | |
| * However modifications made to allow for intersect, union, etc | |
| * to allow for comparing two instances together. | |
| * | |
| * Arguments: | |
| * @std_error - Standard error level acceptable for your dataset. | |
| * Defaults to 0.005 for maximum accuracy. | |
| * Depending on set size may want to increase this to ~0.015 or more. | |
| * @hashFunc - The hash function to run against the string. | |
| * Default Implementation currently uses FNV hash - use MurMurHash or other at your discretion. | |
| * @bytes - Optional - the bytes to populate this HyperLogLog with, used when doing intersect, union, etc. | |
| */ | |
| var HyperLogLog = function(std_error, hashFunc, bytes) { | |
| var pow_2_32 = 0xFFFFFFFF + 1; | |
| function fnv1a_hash(text) | |
| { | |
| var hash = 2166136261; | |
| for (var i = 0; i < text.length; ++i) | |
| { | |
| hash ^= text.charCodeAt(i); | |
| hash += (hash << 1) + (hash << 4) + (hash << 7) + | |
| (hash << 8) + (hash << 24); | |
| } | |
| return hash >>> 0; | |
| } | |
| function log2(x) | |
| { | |
| return Math.log(x) / Math.LN2; | |
| } | |
| function rank(hash, max) | |
| { | |
| var r = 1; | |
| while ((hash & 1) == 0 && r <= max) { ++r; hash >>>= 1; } | |
| return r; | |
| } | |
| // check if hash function supplied if not default to fnv hash | |
| hashFunc = hashFunc ? hashFunc : fnv1a_hash; | |
| var m = 1.04 / std_error; | |
| var k = Math.ceil(log2(m * m)); | |
| var k_comp = 32 - k; | |
| m = Math.pow(2, k); | |
| var alpha_m = m == 16 ? 0.673 | |
| : m == 32 ? 0.697 | |
| : m == 64 ? 0.709 | |
| : 0.7213 / (1 + 1.079 / m); | |
| // setup of bitset | |
| var M = []; | |
| if (!bytes) { | |
| for (var i = 0; i < m; ++i) { | |
| M[i] = 0; | |
| } | |
| } else { | |
| M = bytes; | |
| } | |
| function count(stringValue) | |
| { | |
| if (stringValue !== undefined && stringValue) | |
| { | |
| var hash = hashFunc(stringValue); | |
| var j = hash >>> k_comp; | |
| M[j] = Math.max(M[j], rank(hash, k_comp)); | |
| } | |
| else | |
| { | |
| var c = 0.0; | |
| for (var i = 0; i < m; ++i) c += 1 / Math.pow(2, M[i]); | |
| var E = alpha_m * m * m / c; | |
| // -- make corrections | |
| if (E <= 5/2 * m) | |
| { | |
| var V = 0; | |
| for (var i = 0; i < m; ++i) if (M[i] == 0) ++V; | |
| if (V > 0) E = m * Math.log(m / V); | |
| } | |
| else if (E > 1/30 * pow_2_32) | |
| E = -pow_2_32 * Math.log(1 - E / pow_2_32); | |
| // -- | |
| return E; | |
| } | |
| } | |
| return { | |
| /** | |
| * The count function to call with either the word to add to the | |
| * count, or with null to get the total count. | |
| */ | |
| count: count, | |
| /** | |
| * The matrix/set used for cloning and for the intersection, union, etc. | |
| */ | |
| M: M, | |
| /** | |
| * Returns a new HyperLogLog that represents the union | |
| * between all items. | |
| * | |
| * @param {Object} ll The other HyperLogLog to intersect with | |
| */ | |
| union: function(ll) { | |
| if (ll == null) return this; | |
| var mergedBytes = M.slice(0); // clone array | |
| for (var i=0; i<mergedBytes.length;i++) { | |
| mergedBytes[i] = Math.max(mergedBytes[i], ll.M[i]); | |
| } | |
| return HyperLogLog(std_error, hashFunc, mergedBytes); | |
| }, | |
| /** | |
| * Returns a new HyperLogLog with only those items that intersect | |
| * @param {Object} ll The other HyperLogLog to intersect with | |
| */ | |
| intersect: function(ll) { | |
| if (ll == null) return this; | |
| var mergedBytes = M.slice(0); // clone array | |
| for (var i=0; i<mergedBytes.length;i++) { | |
| mergedBytes[i] = Math.min(mergedBytes[i], ll.M[i]); | |
| } | |
| return HyperLogLog(std_error, hashFunc, mergedBytes); | |
| }, | |
| /** | |
| * A\B means the set that contains all those elements of A that are not in B | |
| * @param {Object} ll The other HyperLogLog to do without. | |
| */ | |
| without: function(ll) { | |
| if (ll == null) return this; | |
| var mergedBytes = M.slice(0); // clone array | |
| for (var i=0; i<mergedBytes.length;i++) { | |
| mergedBytes[i] = mergedBytes[i] > ll.M[i] ? mergedBytes[i] : 0; | |
| } | |
| return HyperLogLog(std_error, hashFunc, mergedBytes); | |
| } | |
| }; | |
| }; | |
| /** | |
| * JS Implementation of MurmurHash3 (r136) (as of May 20, 2011) | |
| * | |
| * @author <a href="mailto:gary.court@gmail.com">Gary Court</a> | |
| * @see http://github.com/garycourt/murmurhash-js | |
| * @author <a href="mailto:aappleby@gmail.com">Austin Appleby</a> | |
| * @see http://sites.google.com/site/murmurhash/ | |
| * | |
| * @param {string} key ASCII only | |
| * @param {number} seed Positive integer only | |
| * @return {number} 32-bit positive integer hash | |
| */ | |
| function murmurhash3_32_gc(key, seed) { | |
| var remainder, bytes, h1, h1b, c1, c1b, c2, c2b, k1, i; | |
| remainder = key.length & 3; // key.length % 4 | |
| bytes = key.length - remainder; | |
| h1 = seed ? seed : 1; | |
| c1 = 0xcc9e2d51; | |
| c2 = 0x1b873593; | |
| i = 0; | |
| while (i < bytes) { | |
| k1 = | |
| ((key.charCodeAt(i) & 0xff)) | | |
| ((key.charCodeAt(++i) & 0xff) << 8) | | |
| ((key.charCodeAt(++i) & 0xff) << 16) | | |
| ((key.charCodeAt(++i) & 0xff) << 24); | |
| ++i; | |
| k1 = ((((k1 & 0xffff) * c1) + ((((k1 >>> 16) * c1) & 0xffff) << 16))) & 0xffffffff; | |
| k1 = (k1 << 15) | (k1 >>> 17); | |
| k1 = ((((k1 & 0xffff) * c2) + ((((k1 >>> 16) * c2) & 0xffff) << 16))) & 0xffffffff; | |
| h1 ^= k1; | |
| h1 = (h1 << 13) | (h1 >>> 19); | |
| h1b = ((((h1 & 0xffff) * 5) + ((((h1 >>> 16) * 5) & 0xffff) << 16))) & 0xffffffff; | |
| h1 = (((h1b & 0xffff) + 0x6b64) + ((((h1b >>> 16) + 0xe654) & 0xffff) << 16)); | |
| } | |
| k1 = 0; | |
| switch (remainder) { | |
| case 3: k1 ^= (key.charCodeAt(i + 2) & 0xff) << 16; | |
| case 2: k1 ^= (key.charCodeAt(i + 1) & 0xff) << 8; | |
| case 1: k1 ^= (key.charCodeAt(i) & 0xff); | |
| k1 = (((k1 & 0xffff) * c1) + ((((k1 >>> 16) * c1) & 0xffff) << 16)) & 0xffffffff; | |
| k1 = (k1 << 15) | (k1 >>> 17); | |
| k1 = (((k1 & 0xffff) * c2) + ((((k1 >>> 16) * c2) & 0xffff) << 16)) & 0xffffffff; | |
| h1 ^= k1; | |
| } | |
| h1 ^= key.length; | |
| h1 ^= h1 >>> 16; | |
| h1 = (((h1 & 0xffff) * 0x85ebca6b) + ((((h1 >>> 16) * 0x85ebca6b) & 0xffff) << 16)) & 0xffffffff; | |
| h1 ^= h1 >>> 13; | |
| h1 = ((((h1 & 0xffff) * 0xc2b2ae35) + ((((h1 >>> 16) * 0xc2b2ae35) & 0xffff) << 16))) & 0xffffffff; | |
| h1 ^= h1 >>> 16; | |
| return h1 >>> 0; | |
| }; |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var setA = new HyperLogLog(0.005, murmurhash3_32_gc); | |
| var setB = new HyperLogLog(0.005, murmurhash3_32_gc); | |
| setA.count('cat'); | |
| setA.count('dog'); | |
| setA.count('fish'); | |
| setB.count('cat'); | |
| setB.count('bird'); | |
| console.log('setA: ' + setA.count()); | |
| console.log('setB: ' + setB.count()); | |
| console.log('setA ∪ setB : ' + setA.union(setB).count()); | |
| console.log('setA ∩ setB : ' + setA.intersect(setB).count()); | |
| console.log('A \\ B: ' + setA.without(setB).count()); | |
| console.log('B \\ A: ' + setB.without(setA).count()); | |
| function generateRandomWords(count,randomness) { | |
| var result = []; | |
| // randomness of a UUID is cryptographic, such that: | |
| // substring(1) = 1/16, substring(2) = 1/256, substring(3) = 1/4096, etc... | |
| while (count > 0) { | |
| result.push(UUID.randomUUID().substring(0,randomness)); | |
| count--; | |
| } | |
| return result; | |
| }; | |
| var randomness = 4; | |
| var expected = Math.pow(16,randomness); | |
| var words = generateRandomWords(500000,randomness); | |
| var hll = HyperLogLog(0.015, murmurhash3_32_gc); | |
| var watch = new StopWatch().start(); | |
| for (var i=0;i<words.length;i++) { | |
| hll.count(words[i]); | |
| } | |
| var estimate = hll.count().toFixed(0); | |
| var error_rate = (estimate - expected) / (expected / 100.0); | |
| console.log(words.length + ' words with expected uniqueness of ' + expected + ' estimated in ' + watch.stop().total() + 'ms (error rate: ' + error_rate + '%)'); |
== Performance of 1 million (1/65k random) [FireFox]
1000000 words with expected uniqueness of 65536 estimated in 5632ms (error rate: -0.0579833984375%)
== Performance of 1 million (1/65k random) [Firefox]
1000000 words with expected uniqueness of 65536 estimated in 1341ms (error rate: -0.0579833984375%)
Note that if loaded as part of DOM we get 1,000,000 words estimated for cardinality in 1.34 seconds :)
Likely we are faster than: http://assets1.pioupioum.fr/uploads/2010/07/JavaScript-Big-Arrays-Intersection-JSpeedmus-Benchmark-Suite.png
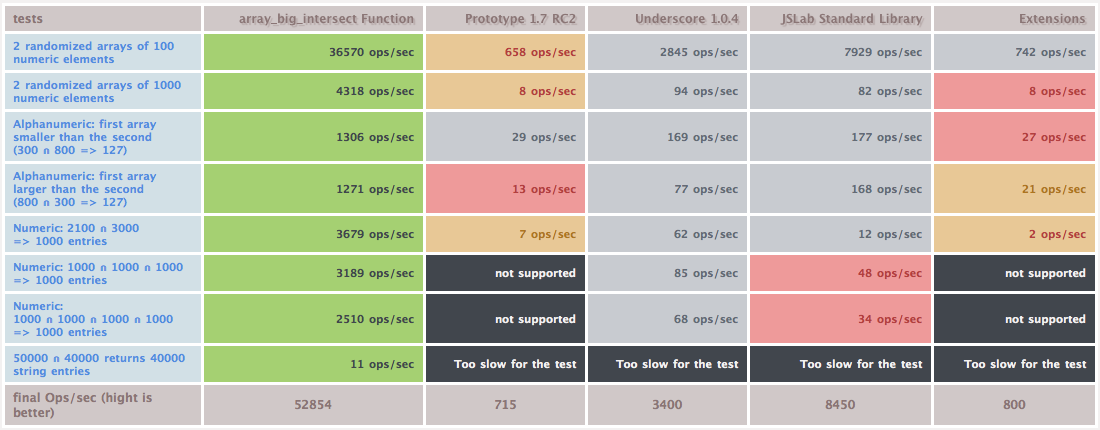{kind=link}
== Performance of 1 million (1/65k random) [Chrome]
1000000 words with expected uniqueness of 65536 estimated in 1046ms (error rate: -0.0579833984375%)
== 1.04 seconds
== Performance of 5 million (1/1,048,576 random) [Chrome]
5000000 words with expected uniqueness of 1048576 estimated in 5732ms (error rate: -0.9981155395507812%)
== Performance of 100k (1/4096 ramdom) [Chrome]
100000 words with expected uniqueness of 4096 estimated in 137ms (error rate: 0.048828125%)
== Performance of 5 million (1/1,048,576 random) [Chrome]
5000000 words with expected uniqueness of 1048576 estimated in 5732ms (error rate: -0.9981155395507812%)
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
== Performance of 500k (1/65k random) [FireFox] ==
== Performance of 500k (1/256 random) [Firefox] ==