コンピュータサイエンス基礎を学ぶことで、情報処理全般に関する基礎知識を習得できます。 この知識はコンピュータのハードウェア、ソフトウェア、通信等の処理や仕組みの理解につながります。
コンピュータサイエンスの学習分野範囲は以下の通りです。
学習分野
- デジタル回路基礎
- 情報工学基礎
- ハードウェア工学基礎
- ソフトウェア工学基礎
- データベース基礎
- 通信ネットワーク基礎
- 情報セキュリティ基礎
- システム開発基礎
情報処理において用いられる進数としては、10進数、2進数、8進数、16進数などがあります。
| 10進数 | 2進数 | 8進数 | 16進数 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 10 | 2 | 2 |
| 3 | 11 | 3 | 3 |
| 4 | 100 | 4 | 4 |
| 5 | 101 | 5 | 5 |
| 6 | 110 | 6 | 6 |
| 7 | 111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| 10 | 1010 | 12 | 10 |
基数変換はn進数の数をm進数の数の表記に変換することです。
| 2進数 | 1 | 1 | 0 | 1 | . | 0 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| 重み | 2^3 | 2^2 | 2^1 | 1 | + | 1/(2^1) | 1/(2^2) | 1/(2^3) |
| 計算値 | 8 | 4 | 2 | 1 | + | 1/2 | 1/4 | 1/8 |
計算: 8x1+4x1+2x0+1x1+1/2x0+1/4x1+1/8x1 = 13.375
| 2進数 | 1 | 6 | 0 | . | 4 |
|---|---|---|---|---|---|
| 重み | 8^2 | 8^1 | 1 | + | 1/8 |
| 計算値 | 64 | 8 | 1 | + | 1/8 |
計算: 64x1+8x6+1x0+(1/8)x4=64+48+0+1/2=112.5
整数部分は素因数分解(割り算)、小数部分は因数結合(掛け算)で変換する。
ex)13.32の2進数への変換 13/2 = 6...1 => 6/2 = 3...0 => 3/2 = 1...1 => 1/2 = 0....1 => 1011 0.32 x 2 = 0.64 => 0.64 x 2 => 1.28 => 1.28 x 2 => 2.56 => 0.010
∴ 1011.010....
和に関しては10進数の足し算と同じように考え、 差に関しては正の数をビット反転して最下位桁に1を足したもの(2の補数)で和をとる
ex)101(2)-11(2) = 0101 + (1100+1) = 0101 + 1101 = 10010 => 10
2進数を表すビット列を左右にずらす作業をシフト演算と呼びます。
左論理シフトは2^n倍を表し、右論理シフトは1/2^nを示す。 また左論理シフトにより値域を超えた場合はオーバーフローと呼ぶ。 右論理シフトにより値域を超えた場合は余りである。
符号を考慮して行うシフト演算のことである。 積に関しては左論理シフトをして空になった桁は0で埋めて、ビット値域の最上位桁に+αで符号ビットを合わせる。 商に関しては右論理シフトをしてビット値域の不足分とビット値域の最上位桁に+αで符号ビットで埋める。 二つともはみ出した桁数は削除する。
2^nを利用した和を利用して計算。
ex) n x 7 = n x (2^2 + 2 + 1) = n x 2^2 + n x 2 + n x 1
2^nを利用した差を利用して計算。
ex) 15/3 => 1111(2)/11(2) => 1111(2) - 1100(2) => 2^2 + 2^0 =5 =>101(2)
ビット列のどの位置に小数点があるかを暗黙的に決めて扱う小数表現
指数表記を用いて小数点以下を表現する手法 コンピュータはメモリに符号と指数部と仮数部に値を分け値を保持します。 符号には+-の情報を、指数部には累乗の情報を、仮数部には値本体を保存します。
正規化を行うことで有効な桁数を多くとることができます。 そうすることで誤差分が減り、値の精度を高めることが可能です。
表記上、割り算をした場合割り切れずに永遠に続く数字ができることがある。 それは無限小数と呼ばれる。
浮動小数点数の指数部が範囲を超過して精度が保てずに生じる誤差である。 限りなく大きい数字や限りなく小さい実数で起こる
絶対値の大きい数と小さい数の加減算を行ったときに、絶対値の小さい値が計算結果に 反映されないことで生じる誤差である。
計算処理を終わるまで待たずに途中で打ち切ることで生じる誤差である。
絶対値がほぼ等しい数字の差を求めた際に、有効桁数が大きく減ることで生じる誤差である。
表現可能な桁数(値域)を超えてしまったため、最小桁より小さい数字が四捨五入や切り上げ、切り捨てなどを行 うことで生じる誤差である。
コンピュータにおいて、AND,OR,NOT等の論理演算をビットの演算に用いることで様々処理を実現している。

AND回路の真理値表は以下の通りです。
Y = A・B
| A | B | Y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
OR回路の真理値表は以下の通りです。
Y = A+B
| A | B | Y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
AND回路の真理値表は以下の通りです。
Y = /A
| A | Y |
|---|---|
| 0 | 1 |
| 1 | 0 |
AND,OR,NOTを組み合わせると様々な論理回路を作成できます。 その代表例としてNAND,NOR,XORがあります。
NAND回路はAND回路とNOT回路を直列に組み合わせた回路です。 NAND回路の真理値表は以下の通りです。
Y = /(A・B)
| A | B | Y |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
NOR回路はOR回路とNOT回路を直列に組み合わせた回路です。 NOR回路の真理値表は以下の通りです。
Y = /(A+B)
| A | B | Y |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 0 |
XOR回路はNOT回路とAND回路を接続したもののNOTがない側を並列誘引し、AND出力側をOR回路で組み合わせた回路です。 XOR回路の真理値表は以下の通りです。
Y = A⊕B
| A | B | Y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
加算器には下位の桁上がりを考慮しない半加算器とそれを考慮する全加算器があります。
半加算器はAND回路とXOR回路を並列誘引接続し組み合わせた回路で作られます。

入力値A,B、出力値C,Sとすると半加算器の真理値表は以下の通りです。
| A | B | C |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
| A | B | S |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
全加算器は半加算器とOR回路を並列接続で組み合わせた回路です。 OR回路側の出力を上位桁、2つ目以降の半加算器の出力を下位桁として扱えます。

ビットの反転にはXOR回路を用います。 反転方法は以下の通りです。
- 反転したいビット列を用意
- 反転させたい位置のみを1それ以外を0にしたビット列を用意
- 上記2つのビット列でXORをとる
ビットの取り出しにはAND回路を用います。 取り出し方法は以下の通りです。
- ビットを取り出したいビット列を用意
- ビットを取り出したい位置に1それ以外を0にしたビット列を用意
- 上記2つのビット列でANDをとる
8bitをひとまとまりにした単位をByteとしています。 記憶容量等はByteを用いて表記されます。
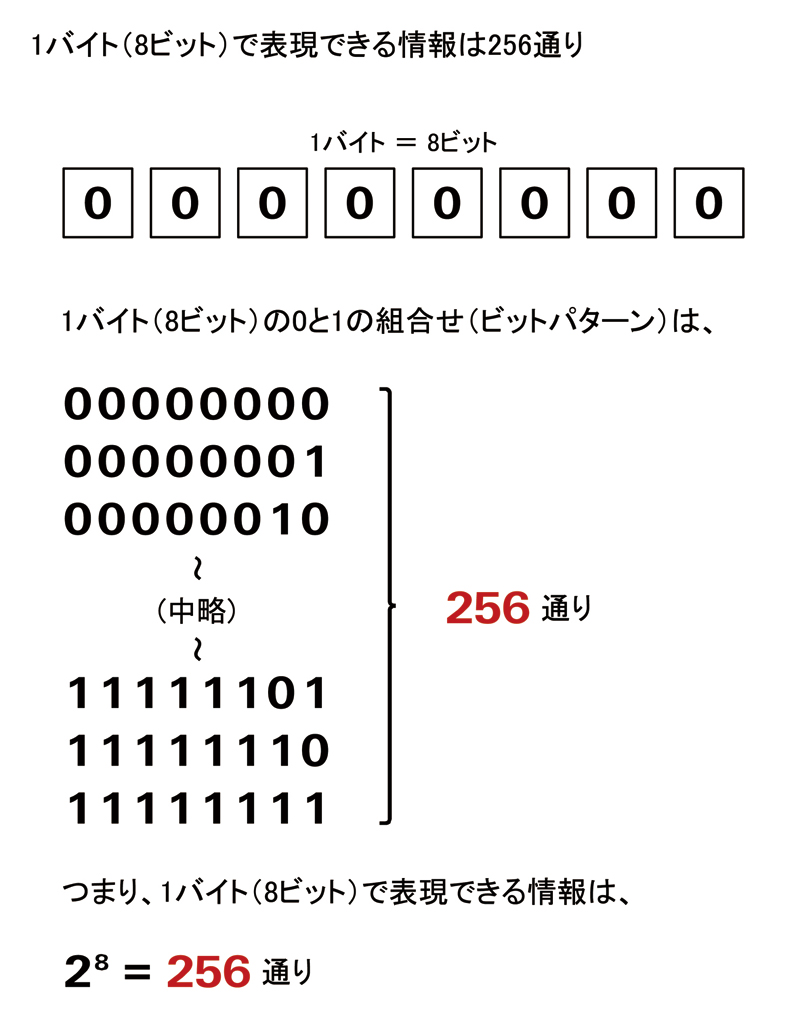
またByteの各単位系は以下の通りです。
記憶容量などの大きい数値を表す単位系
| bit | 乗数 | 単位 |
|---|---|---|
| キロ(K) | 3 | 1KB=1024B |
| メガ(M) | 6 | 1MB=1024KB |
| ギガ(G) | 8 | 1GB=1024MB |
| テラ(T) | 12 | 1TB=1024GB |
情報速度など小さい数値を表す単位系
| bit | 乗数 | 単位 |
|---|---|---|
| ミリ(m) | -3 | - |
| マイクロ(μ) | -6 | - |
| ナノ(n) | -8 | - |
| ピコ(p) | -12 | - |
コンピュータは数値を文字に割り当てることで文字を表現しています。
ASCIIの文字コード表の例です。このコードでは1文字当たり7bitです。

文字コードの種類には以下のような種類があります。
- ASCII ・・・ 米国規格会が定めた基本的な文字コード、アルファベットと数字といくつかに記号のみを表し1文字7bitです
- EBCDIC ・・・ IBMが定めた文字コードで1文字8bitで表し、大型コンピュータで用いられる
- Shift-JIS ・・・ ASCIIの文字と混在させて使える日本語文字コード表。ひらがなや漢字、カタカナが使えます。windowsで使われており、1文字2Byteです
- EUC ・・・ 拡張UNIXと呼ばれ、UNIX系のOSで使われる日本語文字コード表、1文字基本2Byte、補助漢字は3Byteで表される
- Unicode ・・・ 全世界の文字コードを1つにしようとして作成された文字コード、現在は1文字4Byteで、ISOにより標準化された
写真や音声、動画などのマルチメディアデータは連続したデータであるため、ディジタルデータへの変換する作業が必要です。
画像データは点の情を法を集めたものであり、ドットと呼ばれる単位で構成される。
1ドット当たりの情報量
| 色数 | 画像 |
|---|---|
| 2色 | 白黒画像、1ドットにつき1bit |
| 16色 | 1ドットにつき4bit |
| 256色 | 1ドットにつき8bit |
| 65535色 | 1ドットにつき16bit |
| 2^24(25ビット) | フルカラー画像、1ドット24bit |
音声データはアナログ波形のデータであり、ディジタル化して数値表現する方式はPCMである。
標本化
アナログデータを一定の単位時間で区切り、時間ごとの信号を標本として抽出する処理 サンプリング周波数はどの間隔で標本を得るか示すものである。
例:CDのサンプリング周波数が44100Hz,量子化ビット数が16ビットだとするとサンプリング周期は? Ts = 1/44100
量子化
サンプリングしたデータを段階数に当てはめ整数値に置き換える処理 このときの量子化した段階の数を量子化ビット数と呼ぶ
符号化
量子化で得たデータを2進数に直す処理
コンピュータはセンサやアクチュエータを用いて、アナログ情報の取得や機械的動作を実現しています。
- センサ ・・・ 熱、光などの自然界の情報を電気信号に変換し、A/D変換しコンピュータに伝えます
- アクチュエータ ・・・ 電気信号を物理的な動作量に変換する装置です。モータやアームなどが例です
- シーケンス制御 ・・・ 定められた順序や条件に従い、逐次処理を進めていく制御方式
- フィードバック制御 ・・・ 現在の状況を定期的に計測し、目標値とのずれを入力に戻し、出力結果を目標値と一致させようとする制御方式


ノイマン型コンピュータは以下の特徴を持つコンピュータであり、現在のほとんどのコンピュータがノイマン型である。
- プログラム内蔵方式 ・・・ プログラム実行時にプログラムを予め主記憶装置上に読み込んでおく方式
- 逐次制御方式 ・・・ 命令を1つずつ取り出し順番に実行していく方式
主記憶装置にはプログラムの他に処理中の演算結果などを含む様々なデータが記憶されている。 主記憶装置は一定の区画ごとに番号が振られており、それを指定することで任意の場所の読み書きが可能である。 この番号はアドレスと呼ばれる。
CPUが命令を実行するために取り出された情報はレジスタと呼ばれるCPU内部の記憶装置に保存される。
CPUの命令実行手順は以下の通りです。
- 命令の取り出し(フェッチ)
- 命令の解読
- オペランド呼び出し
- 命令実行 CPUはこれらの動作を繰り返します。
レジスタの種類には以下に様なものがある。

プログラムカウンタが取り出す命令のメモリアドレスを持つ。 プログラムカウンタに従ってアドレスを参照し命令を取り出し、命令レジスタにそれを記憶させる。 それが終わった後プログラムカウンタの値をインクリメントする。
命令レジスタに登録された命令は命令部とオペランド部で構成される。 命令部は命令の種類を示すコードが、オペランド部には処理対象となるデータを収めたメモリアドレスが格納される。 命令部の中身は命令デコーダへ送られます。 また、命令デコーダは命令部のコードを解読し、制御信号を必要な装置に通知します。
オペランド(処理対象データ)は読み出しデータのメモリアドレスなどが格納され、 これを参照することでデータを読み出し、汎用レジスタに記憶させる。
汎用レジスタからALUに処理データを読み出し演算し、その結果を汎用レジスタに書き戻す。
コンピュータは機械語と呼ばれる0と1で構成された命令語を理解し処理します。 命令レジスタに登録された命令のオペランド部には必ずメモリアドレスが入っているとは限らず、 基準値からの差分や、メモリアドレスが入っているメモリアドレスなど複雑なものが入っていることもあります。 このように何かしらの計算によりアドレスを求める方式はアドレス修飾(アドレス指定) と呼ばれます。
対象データそのものがオペランド部に入っている方式。
オペランド部に記載してあるアドレスがそのままのアドレスとして使える方式。
オペランド部に記載されているアドレス中に「対象となるデータが入ってる場所を示すメモリアドレス]が記載されている。
オペランド部の値にインデックス(指標)レジスタの値を加算することで実効アドレスを求める。
オペランド部の値にベースレジスタの値を加算することで実効アドレスを求める。
オペランド部の値にプログラムカウンタの値を加算することで実効アドレスを求める。
CPUの性能はクロック周波数、CPI、MIPS等の指標値を用い評価される。
CPUはクロック周波数に合わせて動作を行い、クロック周波数が大きいほど高性能であると言える。 1周期で命令を1実行できるため、クロック周波数が1GHz、CPIが1クロックである場合10^9の命令を1秒で実行できることを表す。 またクロック周波数を1で割ったものはクロックサイクル時間と呼ばれ、クロック当たりの所要時間を示す。
CPI(Clock Per Instruction)は1命令当たり何クロック必要かを表すものである。
MIPS(Million Instruction Per Second)は1秒間に実行できる命令の数を表したものである。
パイプライン処理は複数の命令を並列して実行する処理であり、全体の処理効率が高い処理です。 この処理では次々と命令を先読みしていってるため分岐命令が出た際に先読み分が無駄になることがある。 それは分岐ハザードと呼ばれる。
パイプライン処理では分岐処理(ex:if)が発生します。この結果が明確になるまで次の命令を処理できないという問題があります。 そのため分岐予測と呼ばれる、次の命令はどれかを予想して無駄な待ち時間を発生させないようにする処理があります。 この処理に基づいて分岐先の命令を実行する手法が投機実行である。
パイプライン処理による高速化をさらに進める手法としてスーパーパイプラインやスーパースカラがある。
処理のレーンのステージをさらに細かいステージに分割することでパイプライン処理の効率アップを図るものである。
パイプライン処理を行う回路を複数持たせることで全く同時に複数の命令を実行できるようにしたものである。
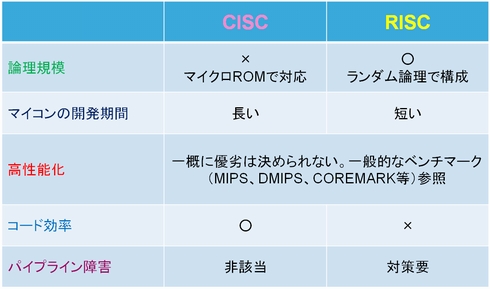
CPUのアーキテクチャには高機能な命令を持つCISCと単純な命令のみで構成されるRISCがある。
CISC
CISCはCPUに高機能な命令を持たせることで、一つの命令で複数な処理を実現するアーキテクチャである。 マイクロプログラムをCPU内部に記憶させることで高機能な命令が実現可能。
RISC
RISCはCPU内部に単純な命令しか持たない代わりに、それらをハードウェアの実で実装し、一つ一つの命令を高速に処理するアーキテクチャである。 ワイヤドロジックによりすべての命令をハードウェア的に実装される。
メモリはコンピュータの動作に必要なデータを記憶する装置である。 半導体メモリには2種類あり、それぞれRAMとROMと呼ばれる。
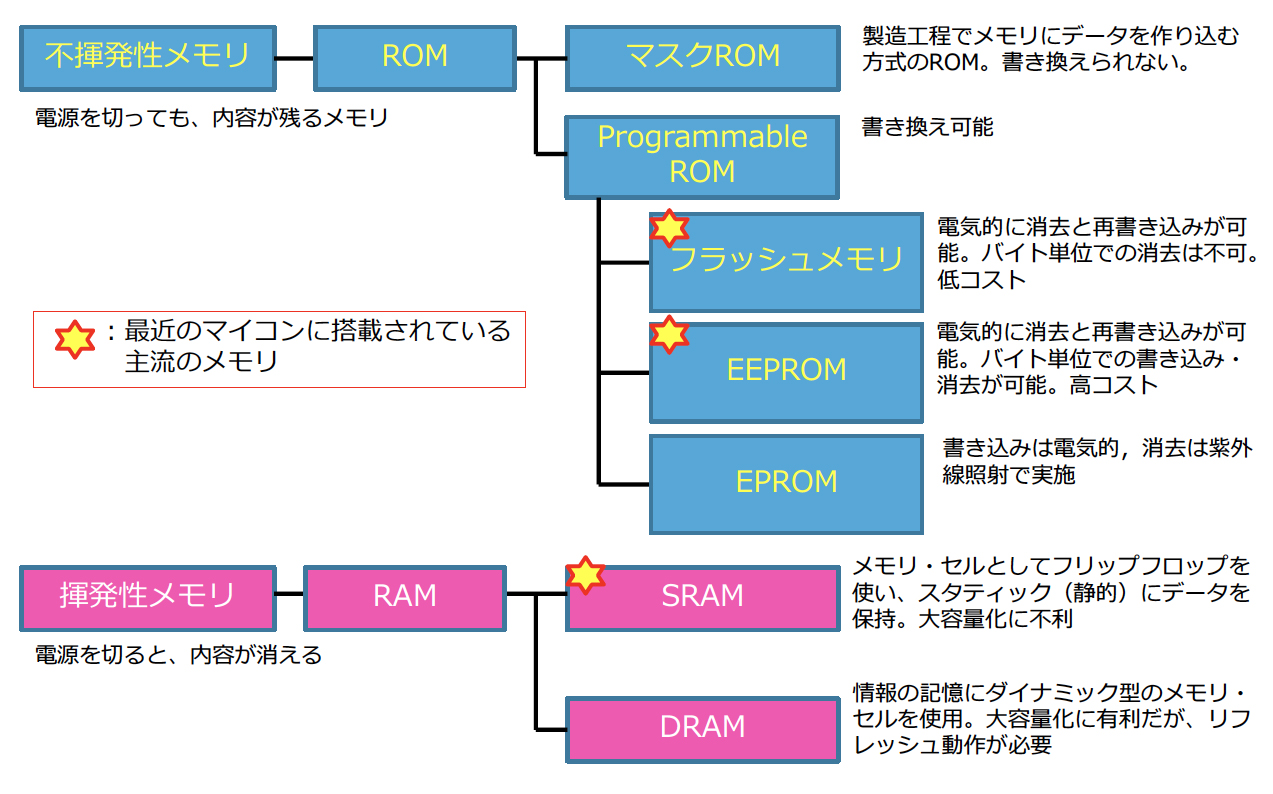
DRAM 安価で容量が大きい、主記憶装置に用いられるメモリである。読み書き速度はSRAMよりも低速であり、記憶内容の維持のためには定期的に再書き込みするリフレッシュ動作が必要である SRAM DRAMよりも非常に高速であるが高価である。小規模のキャッシュメモリとして用いられ、記憶内容の維持にリフレッシュ動作は不要である。
| 種類 | リフレッシュ動作 | 速度 | 集積度 | 価格 | 用途 |
|---|---|---|---|---|---|
| DRAM | 必要 | 低速 | 高 | 安価 | 主記憶装置 |
| SRAM | 不要 | 高速 | 低 | 高価 | キャッシュメモリ |
- マスクROM ・・・ 読み出し専用のメモリであり、製造時にデータが書き込まれている。
- PROM ・・・ ユーザの手でプログラミングし書き換えれるROMである
- EPROM ・・・ 紫外線でデータを消去し書き換えられる
- EEPROM ・・・ 電気的にデータを消去し書き換えられる
- フラッシュメモリ ・・・ ブロック単位でデータを消去し書き換えられる
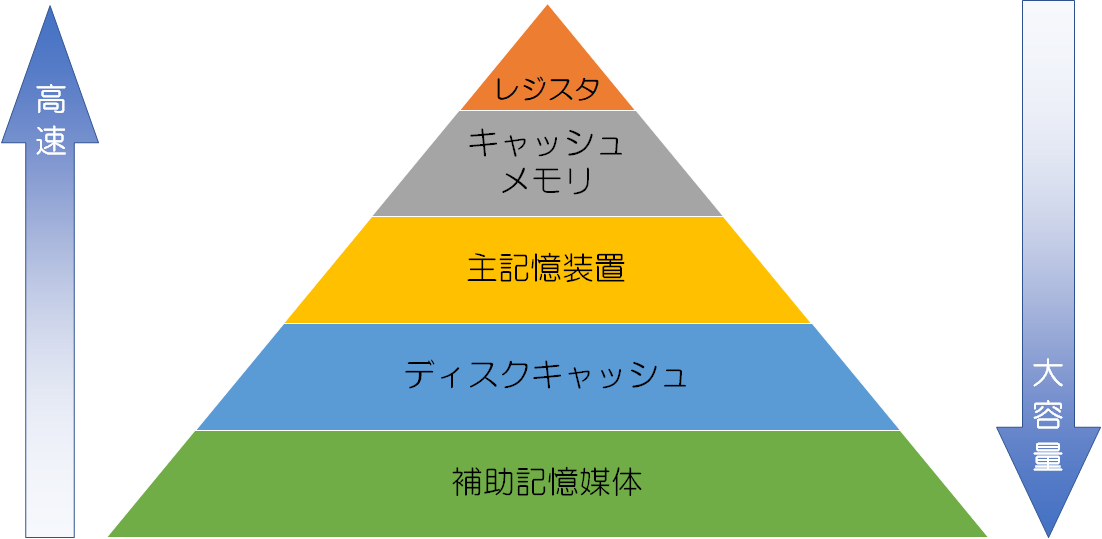
記憶装置ごとのアクセス速度は以下の通りです。
CPUのレジスタ > メモリ(主記憶装置) > ハードディスクの磁気ディスク装置
これらの速度キャップを吸収できれば全体の効率がよくなり高速化できる。 そこで各記憶装置の待ち時間によるロスを減らすためにキャッシュがある。 レジスタとメモリの間に設けるキャッシュメモリや、メモリとハードディスクの間に設けるディスクキャッシュがある。
この方式はキャッシュメモリへの書き込みと同時に主記憶装置にも書き込みます。
この方式は通常はキャッシュメモリにのみ書き込みを行い、キャッシュメモリから追い出されるデータが発生するとそれを主記憶装置に書き込み更新します。
キャッシュメモリに目的とするデータが入っている確率はヒット率で表します。 また、キャッシュメモリを使ったコンピュータの平均アクセス時間(実効アクセス時間)はヒット率で求まります。
キャッシュメモリへのアクセス時間:キャッシュメモリのアクセス時間xヒット率 主記憶装置へのアクセス時間:主記憶装置のアクセス時間x(1-ヒット率) 上記2式の和 => 実効アクセス時間
主記憶装置へのアクセスを高速化する技術にメモリインタリーブがある。 この手法では主記憶装置中を複数の区画に分け、複数の区画に同時アクセスすることで連続した番地のデータを一気に読み出します。
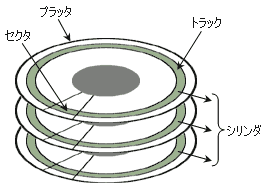
ハードディスクは高速回転するディスクに磁気ヘッドを使って情報を読み書きする。
{(512x4)x20}x1500 = 6.144x10^8 Byte
ハードディスクの最小単位はセクタである。 OSがファイルの読み書きをする場合は、複数のセクタを1ブロックとみなしたクラスタという単位で行われる。
ハードディスクへのデータの読み書きには以下3ステップで行われます。
- シーク(位置決め)
- サーチ(回転待ち)
- データ転送 シークからサーチまでかかる時間は待ち時間として扱われます。 つまりアクセス時間はシークとサーチの時間とデータ転送時間の和で表せます。
以下のパラメータを用いてアクセス時間を算出してみます。
| パラメータ | 値 |
|---|---|
| 回転速度 | 5000t/m |
| 平均シーク時間 | 20ms |
| 1トラックあたりの記憶容量 | 15000Byte |
平均サーチ時間は{60x1000)ms/5000=12ms, 12ms/2=6ms データ転送時間は15000Byte/12ms = 1250Byte/ms, 5000/1250=4ms より 20ms + 6ms + 4ms = 30ms
ハードディスク上でデータの書き込みと消去を繰り返すと、プラッタの空き容量は分散化されます。 また、その状態で新しく書き込みを行うと、書き込み箇所が離散化されます。 このようにファイルがあちこちの領域に分けられ断片化する状態フラグメンテーション(断片化) と呼ばれます。
フラグメンテーションにより1つのファイルを読み書きするのに時間がかかります。 これを解決するために行われる作業にデフラグメンテーション(デフラグ) というものがあります。 これは断片化したファイルデータを連続した領域に並べ直してフラグメンテーションを解決するものです。
複数のハードディスクを組み合わせ用いて、仮想的なハードディスクを構築運用する技術がRAIDです。 これらの用途はハードディスクの高速化や信頼性向上に用いられる。 RAIDはRAID0からRAID6までの7種類あり、求める速度や信頼性に応じて各種類を組み合わせて使用できます。
RAID0は一つのデータを2台以上のディスク分散させて書き込みます。
RAID1は2台以上のディスクに対して常に同じデータを書き込みます。
RAID5は3台以上のディスクを使って、データと同時にパリティと呼ばれる誤り訂正符号も分散させて書き込みます。
駆動装置から記憶装置を簡単に取り出せるものはリムーバブルメディアと呼ばれます。
レーザ光線によりデータの読み書きを行うのが光ディスク装置です。
- CD ・・・ 記憶容量は650MBと700MBの2種類あり安価で大容量である。種類には再生専用と追記型、書き換え可能型の3種類である
- CD-ROM ・・・ 読み込み専用である再生用CD
- CD-R ・・・ 一度だけ書き込める追記型のCD
- CD-RW ・・・ 何度でも書き換え可能なCD
- DVD ・・・ CDよりも波長の短い赤色レーザで記録し、ビットの高密度化が可能であるため大容量を実現している
- DVD-ROM ・・・ 再生専用のDVD
- DVD-R ・・・ 追記型のDVD
- DVD-RW ・・・ 書き換え可能なDVD
レーザ光線と磁気によりデータの読み書きを行うのが光磁気ディスク装置である。
磁性体が塗布されたテープ状のフィルムに磁気を使って読み書きを行うカセット型の記憶媒体が磁気テープ装置である。 ブロックごとにスタート、ストップすることをせずに連続的に読み書きを行うものはストリーマと呼ばれる。
EEPROMの一種を補助記憶媒体に転用したものがフラッシュメモリである。 これを利用したものにメモリカードやUSBメモリがある。
SSDは近年HDDの代替として注目を集めています。 SSDはフラッシュメモリを記憶媒体として内蔵する装置である。 機会的な駆動部分がなく、省電力で衝撃にも強い。また高速に読み書きが可能。 ただしSSDには書き込み回数に上限があります。
| 装置 | 説明 |
|---|---|
| キーボード | 数字や文字を入力するための装置 |
| マウス | マウスの移動情報を入力し画面上の位置を示す装置 |
| トラックパッド | 画面を触れることで移動情報を指し示す装置 |
| タッチパネル | 画面を触れることで画面の位置を指し示す装置 |
| タブレット | パネル上でペン等を動かすことで位置情報を入力する装置 |
| ジョイスティック | スティックを傾けることで位置情報を入力する装置 |
| 装置 | 説明 |
|---|---|
| イメージスキャナ | 絵や画像をデータとして読み取る装置 |
| OCR | 印字された文字や手書き文字などを読み取る装置 |
| OMR | マークシートの読み取り位置を認識する装置 |
| キャプチャカード | ビデオデッキなどの映像装置から、映像をデジタルデータとして取り込む装置 |
| デジタルカメラ | フィルムの代わりにCCDを用いて画像をデジタルデータとして記憶する装置 |
| バーコードリーダ | バーコードを読み取る装置 |
バーコードには2種類あり、商品用にはJANコード、2次元コードにはQRコードがある。
ディスプレイはコンピュータ出力を画面に表示します。 例としてブラウン管型のCRTディスプレイや液晶で薄型の液晶ディスプレイなどがあります。 またディスプレイが表示されるきめ細かさは解像度と呼ばれます。 1ドット当たりRGBの光を重ねて表現されます。
コンピュータは画面に表示される内容はVRAMと呼ばれる専用のメモリに保持する。 VRAMの容量によって扱える解像度と色数が異なります。 例えば、1024x768ドットの表示能力を持つディスプレイがある場合、16bit(65536色)を表示させたい場合のVRAMの容量は以下の通りです。 1024x768x16=12582912bit, 1byte=8bitなため、12582912bit/8 ≒1.6MByte
| 装置 | 説明 |
|---|---|
| CRTディスプレイ | ブラウン管を用いたディスプレイ、奥行きが必要であり消費電力も大きい |
| 液晶ディスプレイ | 電圧により液晶を制御しているディスプレイ、薄型で消費電力も小さい |
| 有機ELディスプレイ | 有機化合物に電圧を加えることで発光する仕組みを用いたディスプレイ、バックライトが不要である |
| プラズマディスプレイ | プラズマ放電による発行を用いたディスプレイ、高電圧が必要である |
コンピュータの処理結果を印刷する装置
| 装置 | 説明 |
|---|---|
| ドットインパクトプリンタ | 印字ヘッドに多数のピンが内蔵され、このピンでインクリボンを打ち付け印字するプリンタ、印字品質は高くない |
| インクジェットプリンタ | 印字ヘッドノズルより用紙に直接インクを吹き付け印刷するプリンタ、高速である |
| レーザプリンタ | レーザ光線を照射することで感光体に印刷イメージを作成しそこに付着したトナーを紙に転写することで印刷するプリンタ、主にビジネス用 |
プリンタの解像度 プリンタの解像度は1inchあたりのドット数を示すdpiを用いて表されます。 プリンタの印刷速度 プリンタの印字速度は一秒間に何文字印字できるかを示すcpsと一秒間に何ページ印刷できるかを示すppmの2つがある。
コンピュータの入出力インターフェスにはさまざまあり、最もポピュラーなのはUSBである。 USBでは繋ぐと自動で設定が行われるプラグアンドプレイという仕組みが使われます。

入出力インターフェスはデータの転送方式によりパラレルインターフェスとシリアルインターフェスに分かれます。

パラレルインターフェスの規格にはIDEやSCSIが上げられます。
内蔵ハードディスクを接続するために規格として使われていたインターフェスである。 元々は最大2台までのハードディスクを接続できるという規格であったが、CD-ROMなどの接続も対応したEIDEとして拡張された。 EIDEでは最大4台までの機器を接続が可能です。
ハードディスクやCD-ROM、MOドライブやイメージスキャナなどの様々な周辺機器の接続に使われていたインターフェス。 デイジーチェーンと呼ばれる数珠つなぎに機器を説ぞk数る方式をとる。また終端にはターミネータ(終端末抵抗)が必要である。 接続できるのはコンピュータ本体含め最大8台までである。また識別のために機器にID番号を割り当てる。
シリアルインターフェスの代表規格にはUSBやIEEE1394がある。 この2つは電源を入れたまま抜き差し可能なホットプラグと周辺機器につなぐと自動設定するラグアンドプレイに対応している。
パソコンと各機器を繋ぐ際のもっとも一般的なインターフェスである。 USBハブを通してツリー状に接続されます。またUSBには複数の規格があります。

i.LinkやFireWireという名前でも呼ばれ、ハードディスクレコーダなどの情報家電、ビデオカメラなどの機器に使われるインターフェス。 リピータハブを用いてツリー状の接続やディジーチェーン方式での接続が可能。
無線で通信するタイプのインターフェスにはIrDAとBlueToothがある。
赤外線を用いて無線通信を行う規格であり、携帯電話やノートPC等に使われています。 なおテレビのリモコンは同じく赤外線を用いますがIrDAではありません。 また、障害物があると通信できない特徴があります。
2.4GHz帯の電波を用いて無線通信を行う規格であり、コードレスイヤホンや携帯電話、マウスなど様々な周辺機器をワイヤレスに接続可能です。 通信距離は10mほどであり、障害物があっても関係がない。
OSはコンピュータの基本動作を実現する基本ソフトウェアである。
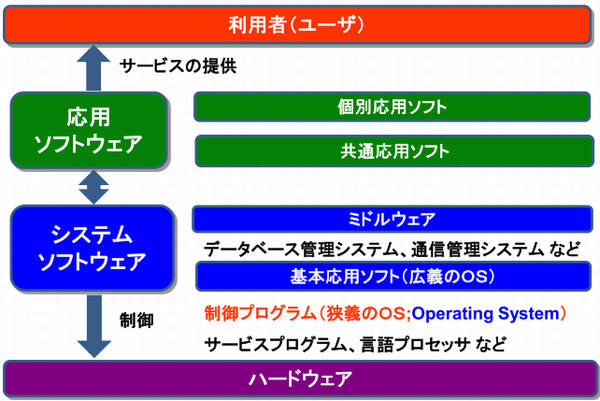
基本ソフトウェアは3つのプログラムに分けられる。
- 基本ソフトウェア
- 制御プログラム ・・・ ハードウェアを管理しコンピュータを効率管理できるように働くソフトウェア
- 言語処理プログラム ・・・ C言語、Javaなどのプログラム言語で書かれたプログラムを機械語に翻訳するプログラム
- サービスプログラム ・・・ コンピュータの機能を補う補助的なプログラムでユーティリティと呼ばれ、ファイル圧縮プログラムなどがある
| 種類 | 説明 |
|---|---|
| Windows | Microsoft社製のOS、GUIによる画面操作でコンピュータに命令を行う |
| Mac OS | Apple社製のクリエイティブな作業によく用いられるOS、GUIを先駆けで導入したことで有名 |
| MS-DOS | Windows普及前に使われていたMicrosoft社製のOSであり、CUI入力であったことで有名 |
| UNIX | サーバに使われることが多いOS、大勢のユーザが同時利用できるように考えられている |
| LINUX | UNIX互換のOSであり、オープンソースで無償で利用可能 |
コンピュータを操作するインターフェスとしてGUIとCUIがあります。 GUIは画面を視覚的に操作することで命令を伝える操作方式でCUIはコマンドで操作する方式です。
APIはOSが含み持つ各機能をアプリケーションから呼び出せる仕組みである、
ソフトウェアによる自動化にRPA(Robotic Process Automation)があります。
ユーザからみて処理させたい一連の作業のかたまり単位がジョブであり、OSはそれを効率よく処理していけるように実行スケジュールを管理します。 ジョブ管理にはバッチ処理と呼ばれる処理に時間のかかる作業をコンピュータに登録しまとめて処理する仕組みがあります。
ジョブ管理はカーネルが持つ機能の1つであり、この機能でユーザとの間に橋渡しを行うマスタスケジューラという管理プログラムがあります。
ユーザはこの管理プログラムにジョブの実行を依頼する。
また、マスタスケジューラはジョブの実行をジョブスケジューラに依頼し、マスタスケジューラは実行の監視に努め、ジョブスケジューラがジョブを実行する。
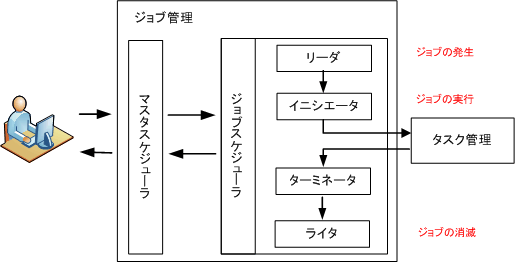
CPUと入出力装置には処理速度に大きな差が存在する。 スプーリングと呼ばれる、低速な装置とのデータやり取りを高速な磁気ディスクを介して行い処理効率を高める手法が導入されている。 スプーリングを用いるとCPUの待ち時間を削減できるため、単位時間あたりに処理できる仕事量を増やすことが可能。
コンピュータから見た仕事の単位がタスクである。
生成されたタスクの状態には3つの状態があります。
- 実行可能状態(Ready) ・・・ いつでも実行可能でCPUの使用権が回るのを待機する状態、生成直後のタスクは待ち行列になりこの状態となる
- 実行状態(Run) ・・・ CPUの使用権が与えられ実行中の状態
- 待機状態(Wait) ・・・ 入出力処理が発生したので終了を待っている状態

実行可能状態で待機するタスクにCPUの使用権を割り当てるのはディスパッチャと呼ばれる管理プログラムである。 また、このときどのタスクに使用権を割り当てるかを決めるためにタスクの実行順序を定める必要がある。これはタスクスケジューリングと呼ばれる。 タスクスケジューリングの種類には3つの方式がある。
実行可能となったタスク順にCPUの使用権を割り当てる方式。 タスクに優先順位がないため、実行途中でCPUの使用権が奪われることはない(ノンプリエンプション)
タスクに優先度を設定し、優先度が高いものから実行していく方式。 実行中のタスクよりも優先度が高いものが待ち行列に追加されると実行途中でCPUの使用権が奪われる(プリエンプション)
CPUの使用権を一定時間ごとに切り替える方式。 実行可能状態になった順番でタスクにCPU使用権が割り当てられるが、規定時間に終わらなかった場合は待ち行列の最後に回されます。
タスク管理の役割はCPUの有効活用によります。 マルチプログラミングは複数のプログラムを見かけ上同時に実行させることにより遊休時間を削減しCPuの使用効率を高めるものである。
実行中のタスクを中断し別の処理に切り替え、そちらが終了すると再び元のタスクに再帰する処理は割り込み処理と呼ばれる。 割り込み処理には下記のような種類があります。 内部割込み
| 種類 | 説明 |
|---|---|
| プログラム割込み | 記憶保護例外などの場合に生じる割り込み |
| SVC割り込み | 入出力処理の要求などのカーネル呼出し命令が生じた際に生じる割り込み |
外部割込み
| 種類 | 説明 |
|---|---|
| 入出力割込み | 入出力装置の動作完了時や中断時に生じる割り込み |
| 機械チェック割込み | 電源異常や主記憶装置障害などのハードウェアの異常時に生じる割り込み |
| コンソール割込み | ユーザによる介入が行われた際に生じる割り込み |
| タイマ割込み | 規定の時間を過ぎたときに生じる割り込み |
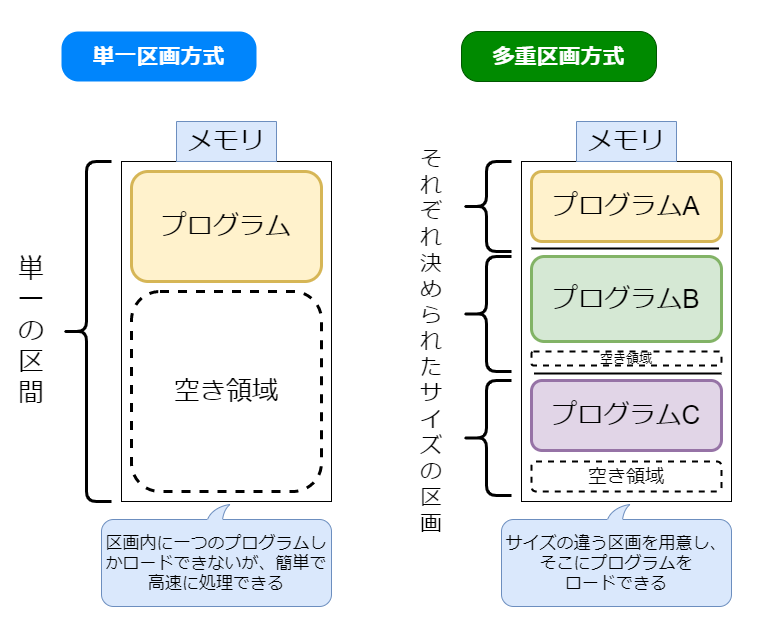
限られた主記憶空間を効率よく使われるようにプログラムに割り当てるのが実記憶管理の役割です。 ノイマン型コンピュータではプログラム内蔵方式をとります。この方式では主記憶上にプログラムをロードして実行します。 プログラムをロードしたときの割り当て方が不適切であると容量は活用できなくなる。そこで適切に書き込むための方法がいくつか存在する。
固定区画方式は主記憶に固定長の区画(パーティション)を設けて、そこにプログラムを読み込む管理方式です。 全体を単一の区画とする単一区画方式と複数の区画に分ける多重区画方式があります。
主記憶を最初に固定用で区切るのではなく、プログラムをロードするタイミングで必要なサイズに区切る管理方式が可変区画方式である。 この方式ではプログラムが必要とする大きさで区切りを作りそこのプログラムをロードする。また固定区画方式よりも主記憶の利用効率は良い。

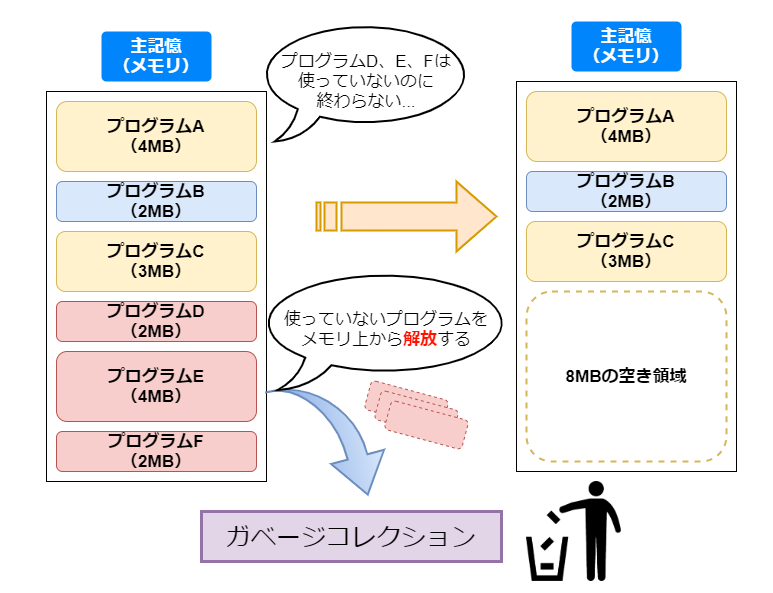
可変区画方式の場合プログラムを主記憶上に隙間なく埋め込んで実行するとができますが、必ず詰め込んだ順番にプログラムが終了するとは限らないため連続した状態で主記憶の空き容量を確保することができません。この現象はフラグメンテーション(断片化) と呼ばれます。 フラグメンテーションの解消のためにはロードされているプログラムを再配置することにより、細切れ状態の空き領域を連続したひとつの領域する必要があります。この操作はメモリコンパクションまたはガーベジコレクションと呼ばれる。
区画を効率よく配置できるようにしても実行したプログラムのサイズが主記憶の容量を超えていたらロードができません。 これを可能にするような工夫がオーバレイ方式である。 この方式ではプログラムをセグメントという単位に分割しておいて、そのときに必要なセグメントだけを主記憶上にロードして実行されます。

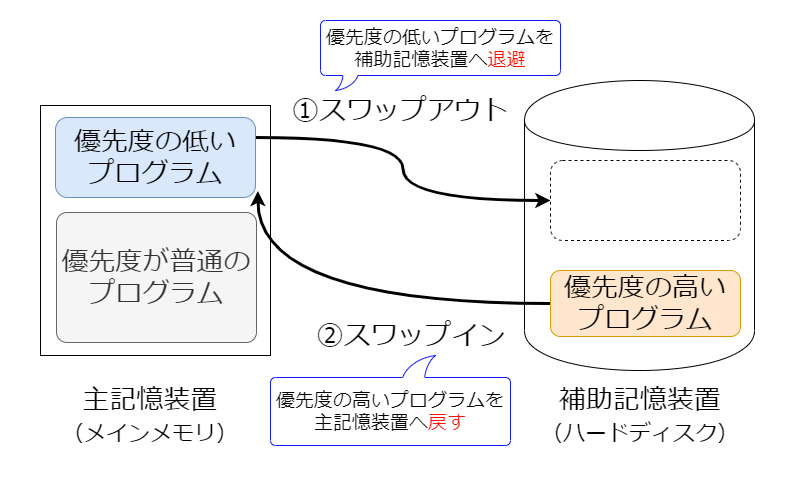
マルチプログラミングの環境では優先度の高いプログラムによる割り込みなどが発生した場合、現在実行中のものをいったん中断させ切り替えるが、このとき優先度の低いプログラムが使っていた主記憶領域の内容を補助記憶装置に丸ごと退避させて空き容量を作る。退避させたプログラムに再びCPUの使用権が与えられるとき、退避させた内容は補助記憶装置から主記憶へロードしなおして、中断箇所から処理を再開する。この2つの処理(スワップアウトとスワップイン)を合わせた処理はスワッピングと呼ばれる。この処理が発生すると処理速度が極端に低下する。
再配置可能プログラムはプログラムがどこにロードしても実行に問題ないプログラムです。
主記憶上のどこに配置しても実行できるといる性質は再配置可能(リロケータブル)と呼ばれる。
主記憶上にロードされて処理を終えたプログラムを再ロードすることなく、繰り返し実行できる性質は再使用可能(リユーザブル)と呼ばれる。
再ロードすることなく繰り返し実行できる再使用可能なプログラムにおいて、複数のタスクから呼び出しても互いに干渉することなく同時実行できるという性質は再入可能(リエントラント)と呼ばれる。
実行中に自分自身を呼び出すことができる性質は再帰的(リカーシブ)と言います。
仮想記憶は主記憶や補助記憶の存在を隠蔽し、広大なメモリ空間を自由に扱えるようにするものです。 実記憶上の配置のような物理的制約を意識する必要がないのが特徴です。 また仮想アドレスから実アドレスへ変化する処理はメモリ交換ユニット(MMU)が行う。またこの仕組みは動的アドレス変換機構(DAT) と呼ばれる。 また仮想記憶に置かれたデータは主記憶装置を超えても補助記憶装置もメモリの一部として扱うことにより主記憶装置よりも大きなサイズの記憶空間を提供できる。
仮想記憶の実装方式には仮想アドレス空間を固定長の領域に区切って管理するページング方式と可変長の領域に区切って管理するセグメント方式がある。
ページング方式ではプログラムをページと呼ばれる単位で分割管理します。現在のOSでは実行に必要なページだけを実記憶に読み込ませる方式が主流である。 またこの方式では仮想記憶と実記憶の対応付けはページテーブルという表により管理され、これにより仮想記憶上と実記憶上のどのページが結びついている確認できる。 補助記憶から実記憶へのページ読み込みはページインと呼ばれます。またページインしようとしても実記憶がいっぱいの場合いずれかのページを補助記憶に追い出して空きを作る必要があります。実記憶から補助記憶へとページを追い出すことはページアウトと呼ばれます。 実記憶の容量が少ないとページの置き換えをする頻度が高くなりシステム利用効率が極端に低下します。この現象はスラッシングと呼ばれます。
| 方式 | 説明 |
|---|---|
| FIFO | 最初にページインしたページを追い出し対象にする |
| LIFO | 最後にページインしたページを追い出し対象にする |
| LRU | 最も長い時間参照されていないページを追い出し対象にする |
| LFU | 最も参照回数の少ないページを追い出し対象にする |
スワッピング ・・・ プロセス単位で領域の出し入れを行う ページング ・・・ ページ単位で領域の出し入れを行う
ファイルはデータを一つの集まりとして記録するための単位である。
文字コードと開業やタブなど一部の制御文字のみで作られるファイル形式
テキスト形式のファイルの一種で、個々のデータである機種やOSの種類のよらず文字や数字をカンマで区切り行と列を改行で区切ることで表形式のデータを保持することに特化したファイル形式。
画像が埋め込まれた書類をコンピュータの機種やOSの種類によらず、元の通りに再現して表示することができる電子文書のファイル形式。
| 種類 | 説明 |
|---|---|
| BMP | 画像を圧縮せずにそのまま保存するファイル形式 |
| JPEG | 画像圧縮保存形式、フルカラーが扱え圧縮率が高く、不可逆圧縮なため画質が劣化します |
| GIF | 画像圧縮保存形式、可逆圧縮であり、扱える色数が256色という制限がある |
| PNG | 画像圧縮保存形式、フルカラーが扱え可逆圧縮であり画像の劣化もない、圧縮率はJPEGが良い |
| 種類 | 説明 |
|---|---|
| MP3 | 音声を圧縮し保存する形式、人に聞こえないレベルの音を削減するなどをして不可逆の圧縮を行う |
| WAV | 録音したそのままの状態と同じ音質を保ったファイル形式、非圧縮 |
| MIDI | デジタル楽器の演奏データを保存できるファイル形式 |
| 種類 | 説明 |
|---|---|
| MPEG | 不可逆圧縮で動画を保存するファイル形式、ビデオCDにはMPEG-1、DVDにはMPEG-2、コンテンツ配信にはMPEG-4が用いられる |
| MP4 | MP4はMPEG4と音声のMP3を結合して格納しているファイルである |
画像や音声、動画等のマルチメディアデータはそのままであると膨大なデータ量となる。そのため通常は圧縮技術を用いてデータサイズを小さくし保存されるのが一般的である。 非可逆圧縮はデータを間引く形で圧縮したものであり、伸張しても元の同じデータになりません。逆に可逆圧縮は伸張したら元のデータに戻すことができます。
ディレクトリはファイルをグループ化して整理するものであり、補助記憶装置中はディレクトリで管理される。
ディレクトリ中にはファイルだけではなく他のディレクトリも入れられる。 補助記憶装置全体に階層構造を持たせて管理することが可能である。
- ルートディレクトリ ・・・ 階層の一番上位に位置するディレクトリ
- サブディレクトリ ・・・ 他のディレクトリに含まれるディレクトリ
コンピュータが現在開いて作業しているディレクトリはカレントディレクトリと呼ばれます。 また、カレントディレクトリの1階層上のディレクトリは親ディレクトリと呼ばれます。
ファイルの場所はファイルパスを用いて示します。このファイルまでの場所を示す経路はパスと呼ばれます。 パスにはルートディレクトリからの経路を示す絶対パスとカレントディレクトリからの経路を示す相対パスが存在します。
- ルートディレクトリは「/」or「\」で表す
- ディレクトリの次の階層は「/」or「\」で区分する
- ディレクトリの次の階層は「/」or「\」で区分する
- カレントディレクトリは「.」で表す
- 親ディレクトリは「..」で表す
汎用コンピュータにとってのファイルは一連のデータをまとめたものであり、レコードの集合がファイルである。 汎用コンピュータのOSがどのようにレコードを格納するかを定義づけたファイル構成法をいくつか用意しています。
先頭レコードから順番にアクセスする方法であり、シーケンシャルアクセスと呼ばれる。
任意のレコードに直接アクセスする方法であり、ランダムアクセスと呼ばれる。
順次アクセスと直接アクセスを組み合わせた方法で、任意のレコードに直接アクセスした後以降、順次アクセスで順番に処理する。
先頭から順番にレコードを記録していくのが順編成ファイル。もっとも単純な編成法で順次アクセスのみが可能である。
レコード中のキーとなる値を利用することで任意のレコードを指定した直接アクセスを可能となる編成法。 直接アクセス方式と間接アクセス方式があり、キー値から格納アドレスを求める方法が異なる。
キー値の内容をそのまま格納アドレスとして用いる方式。
ハッシュ関数という計算式によりキー値から格納アドレスを算出して用いる方式。 またハッシュ関数での計算値が一致し異なるレコードが同じアドレスで衝突する現象はシノニムと呼ばれそれが起こるレコードはシノニムレコードと呼ばれます。
索引を格納する索引域とレコードを格納する基本データ域、そこからあふれたレコードを格納する溢れ域の3つの領域から構成される。 索引による直接アクセスと先頭からの順次アクセスに対応した編成法である。
メンバと呼ばれる順編成ファイルを複数持ち、それらを格納するメンバ域と各メンバのアドレスを管理するディレクトリ域で構成される編成法 これはプログラムやライブラリを保存する用途によく使われます。
DBMSはデータベース管理システムのことであり、データベースの定義や操作制御などの機能を持つミドルウェアである。 データベースには関係型、階層型、ネットワーク型の3州類があり、関係型が現在の主流である。
関係データベースは表の形でデータを管理するデータベースであり、表で構成されます。 また関係データベースはリレーショナルデータベース(RDB) と呼ばれます。
| 種類 | 説明 |
|---|---|
| 表(テーブル) | 複数のデータを収容する場所 |
| 行(レコード) | 1件分のデータを表す |
| 列(フィールド) | データを構成する項目を表す |
関係データベースにおいて蓄積データの重複や矛盾が発生しないように最適化するのが一般的です。 同じ内容を表のあちらこちらに書かないように表を分割するなどすることは正規化と呼ばれます。
関係演算は表の中から特定の行や列を取り出したり、表と表をくっつけ新しい表を作り出したりする演算のことである。 選択、射影、結合などがある。
- 選択 ・・・ 行を取り出す演算
- 射影 ・・・ 列を取り出す演算
- 結合 ・・・ 表同士を結合する演算
このような演算を行い仮想的に作る一時的な表はビュー表と呼ばれる。
スキーマは「概念、要旨」という意味を持ち、データベース構造や使用の定義をするものである。 標準使用されているスキーマにはANSI/X3/SPARC規格は3層スキーマ構造をとり、外部スキーマ、概念スキーマ、内部スキーマという3層に定義を分けることでデータの独立性を高める。

データベースの表には行を識別できるようにキーとなる情報が含まれており、それは主キーと呼ばれます。また表同士を関連付けするときの主キーは外部キーと呼ばれます。 また複数列を組み合わせて主キーにしたものは複合キーと呼ばれます。
非正規形(正規化を行っていない元の形の表)を何回か正規化を行い最適化行います。
| 正規化 | 説明 |
|---|---|
| 非正規形 | 正規化されていない繰り返し部分を持つ表 |
| 第1正規形 | 繰り返し部分を分離させ独立したレコードを持つ表 |
| 第2正規形 | 部分関数従属しているところを切り出した表 |
| 第3正規形 | 主キー以外の列に関数従属している列を切り出した表 |
非正規型の表は繰り返し部分を持ち、関係データベースで扱えない表の形である。
非正規形の表から繰り返し部分を取り除いたものは第1正規形となる。 また表の形は2次元の表となる。
- 関数従属 ・・・ 主キーが決まったとき列が一意に定まる関係
- 部分関数従属 ・・・ 複合キー日舞の項目のみで列の値が一意に定まる関係

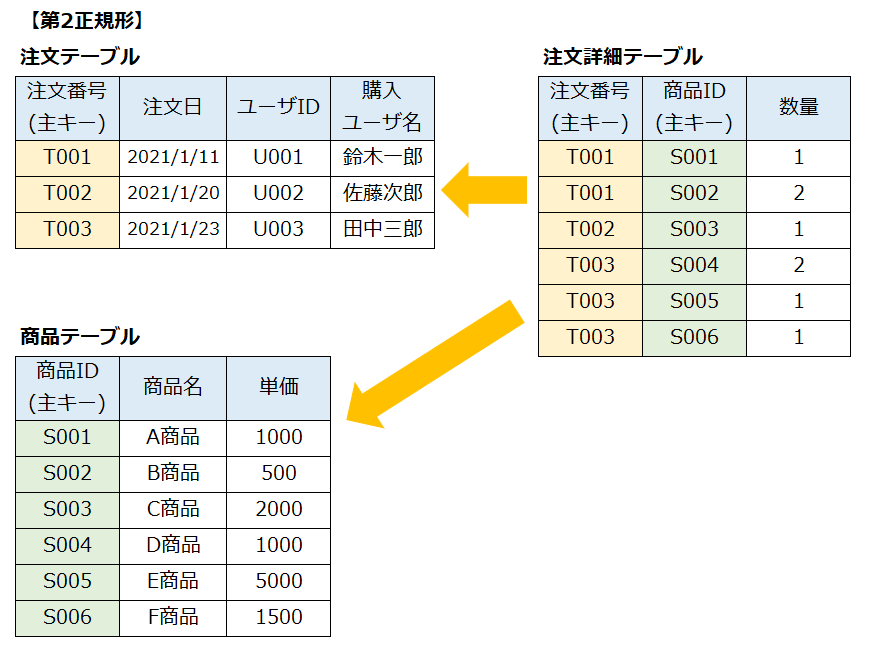
第1正規形の表から部分関数従属している列を分離した表が第2正規形の表である。
第2正規形の表から主キー以外の列に関数従属している列を分離した表が第3正規形の表である。
SQL(Structured Query Language)はDBMSへ支持を伝えるために用いる言語である。 SQLには表の定義(CREATE)やレコードの挿入(INSERT)、削除(DELETE)、レコードの一部を更新(UPDATE)する命令がある。 これらの命令はスキーマ定義や表の作成を担当するデータ定義言語(DDL) とデータの抽出や挿入、更新、削除といった操作を担当するデータ操作言語(DML) に区別できます。
SELECT文の基本書式は以下の通りです。 SELECT 列名 FROM 表名 WHERE 条件
SELECT 列名 FROM 表名
SELECT * FROM 表名 WHERE 条件式 なお条件式には比較演算子や論理演算子を用いる。
SELECT * FROM 表名1, 表名2 WHERE 表名1.ID = 表名2.ID
ORDER文は抽出結果を整列させておきたい場合に用います。 ORDER BY 列名 ASC(or DESC) ASC:昇順、DESC:降順
例)商品表の価格順に商品表を並べる場合 SELECT * FROM 商品表 ORDER BY 単価
SQLにはデータを取り出す際に集計を行う様々な関数が用意されている。
| 関数 | 説明 |
|---|---|
| MAX(列名) | 列の最大値を求める |
| MIN(列名) | 列の最小値を求める |
| AVG(列名) | 列の平均値を求める |
| SUM(列名) | 列の合計を求める |
| COUNT(*) | 行数を求める |
| COUNT(列名) | 列の値が入っている行の数を求める |
例)扱う商品の数を取り出す場合 SELECT COUNT(*) FROM 表
グループ化は特定の列が一致する項目をまとめて1つにすることを指す。 グループ化には以下文を用いる。 GROUP BY 列名
グループ化なおかつそこから条件を絞り込む場合はHAVINGを用います。 GROUP BY 列名 HAVING 絞り込み条件
トランザクション管理と排他処理は複数人がデータベースにアクセスし同時変更などをした際にデータ内容に不整合が生じる問題からデータベースを守る処理です。
データベースにおいて、一連の処理をひとまとめにしたものはトランザクションと呼ばれます。
排他制御は処理中のデータをロックし、他の人が読み書きできないようにする機能である。 ロックする方法には共有ロックと専有ロックがある。
- 共有ロック ・・・ 各ユーザはデータを読むことはできるが、書き込みができない状態
- 専有ロック ・・・ 他ユーザはデータを読み書きすることができない
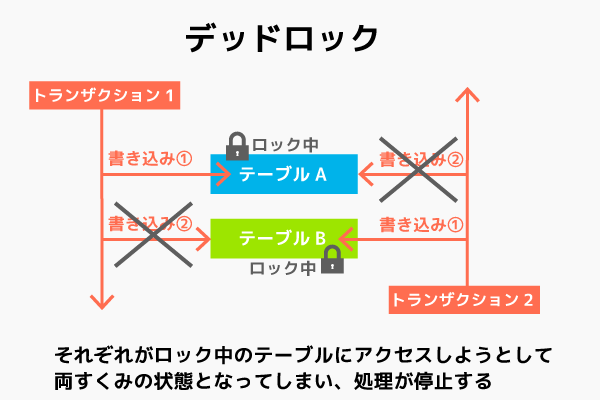
また、デットロックと呼ばれる現象がロック機能を使いすぎると起こる場合があります。
DBMSではトランザクション処理に対して4つの特性(ACID特性)が必要とされる。
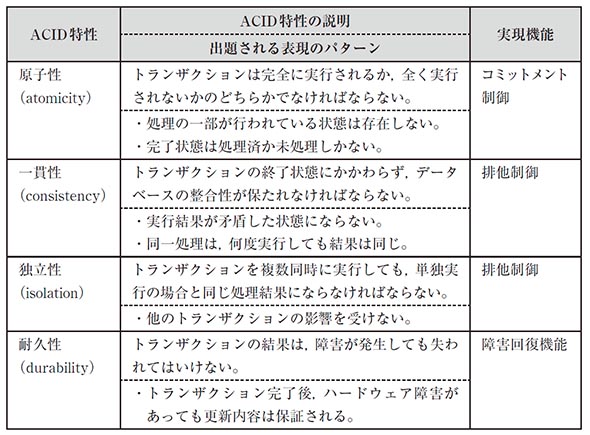
DBMSにSQL文を1つのプログラムにまとめ保存しておくことはストアドプロシージャと呼ばれます。 一連の処理が実行される。 また、メリットは以下の通りです。
- ネットワークの負荷削減
- 処理速度の向上
データベースは定期的にバックアップを作ったり、更新前後の状態をジャーナルファイルに記録したりし障害の発生に備えます。 バックアップ後の更新はジャーナルと呼ばれるログファイルに更新前の状態と更新後の状態を逐一記録しデータベースの更新履歴を管理するようにする。 障害が発生した際にはこれらのファイルを用いてロールバックやロールフォワードなどの障害回復朱里を行い、元の状態に復旧する。
データベースでは更新処理をトランザクション単位で管理します。 トランザクションは一連の処理が問題なく完了できたときに、最後にその更新を確定することでデータベースへ更新内容を反映させる。これはコミットと呼ばれる。 また、トランザクション処理中に障害が発生し更新に失敗した場合、データベース更新前の状態を更新前ジャーナルから取得し、データベースをトランザクション処理直前の状態に戻します。この処理はロールバックと呼ばれます。
物理的に分かれている複数のデータベースを見かけ上1つのデータベースとして扱えるようにしたシステムは分散データベースシステムと呼ばれます。 これはトランザクション処理が各サイトにわたり行われるので、全体の同期をとりコミット、ロールバックを取らないと、データの整合性が取れなくなる恐れがある。そのため全サイトに問い合わせを行い、その結果を見てコミット、ロールバックを行う。この処理は2相コミットと呼ばれる。
データベース自体が突然障害に見舞われた場合、バックアップ以降の更新ジャーナルから更新情報を取得し、データベースを障害発生直前の状態に復旧させる一連の処理があります。この処理はロールフォワードと呼ばれます。
局所的な狭い範囲のネットワークはLAN、LAN同士をつなぐ広域ネットワークはWANと呼ばれます。
通信路を互いの1本の回線で結ぶ方式は専用回線方式と呼ばれます。 また交換機により必要に応じた通信路が確立される方式は交換方式と呼ばれます。 交換方式には以下の2種があり現在はパケット交換方式が主流です。
- 回線交換方式 ・・・ 回線自体を交換機が繋ぎ通信路が固定されます
- パケット交換方式 ・・・ パケットという単位分割された通信データを交換機が回線へ送り出すことで通信路を形成する
WANを除いて現在のコンピュータネットワークで用いられるのはほぼパケット交換方式である。 またWANは以下の方式でつながれることが多い。
| 種類 | 説明 |
|---|---|
| 専用線 | 拠点間を専用線で結ぶもの、高セキュリティだが高価 |
| フレームリレ方式 | パケット交換方式をもとに伝送中の誤り制御を簡素化し高速化したもの。データ伝送単位は可変長フレームである |
| ATM交換方式 | パケット交換方式をもとにデータ転送単位を固定長のセル(53バイト)にすることで高速化を目指したもの、伝送遅延は小さい |
| 広域イーサネット | LANで使われるイーサネット技術を用いて接続するもの。高速かつコスト面のメリット大。近年主流の方式 |
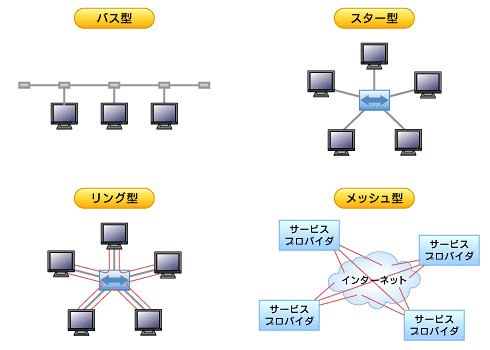
LANの規格として、最も普及しているのがイーサネット(Ethernet)である。 IEEEにより標準化されいくつかの規格に分かれている。伝送速度の単位であるBPSは1秒間に送ることのできるデータ量を表す。

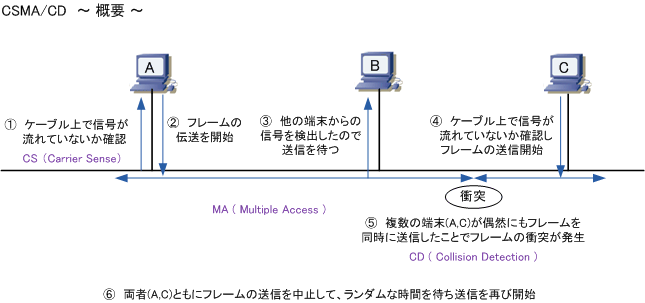
イーサネットはCSMA/CD方式でアクセス制御を監視しています。
リング型のLANの代表であるトークンリングはアクセス制御方式にトークンパッシングが採用されている。

物理的なケーブルを用いず、電波を用いて無線で通信を行うLANは無線LANであり、IEEE802.11として規格化されている。 電波が届く範囲であればどこでも繋げられますが、電波は盗聴される恐れがあるため暗号化などのセキュリティ対策が重要である。
ネットワークによって複数のコンピュータが組み合わせて動く処理の形態には主に2つの種類があります。
- 集中制御型 ・・・ ホストコンピュータが手中的に処理を行い、他のコンピュータにツリー状などでぶら下がる構成となる
- 分散処理型 ・・・ 複数のコンピュータに負荷を分散させ、それぞれで処理を行うようにした構成となる
集中管理した方がよい資源やサービスを提供するサーバと必要に応じリクエストを行うクライアントという2種類のコンピュータで処理を行うシステムである。現在の主流である。
コンピュータ同士がやり取りするための規定プロコトルと呼ばれます。 またプロコトルはたくさんの種類があり、7階層に分けたものはOSI基本参照モデルと呼ばれます。

インターネットではTCP/IPというプロコトルが利用されています。
ネットワークの伝送にかかる時間は下記式で求まる。 伝送時間 = データ量 / 回線速度

NICはコンピュータをネットワークに接続するための拡張カードでありLANボードとも呼ばれます。 役割としてはデータを電気信号に変換しケーブル上に流すことと受け取ることである。 また、IEEEにより規格化されたMACアドレスをが振られており、世界中で自由重複しない番号で保障される。 MACアドレスは16進数表記で48バイトあり、先頭の24ビットが製造メーカ番号で、後ろの24ビットが製造番号を表す。
リピータは第1層(物理層)の中継機能を実現する装置である。 ケーブル中を流れる電気信号を増幅し、LANの延長距離を延ばす。 また、ネットワーク中につながっていてデータの流される範囲はセグメントであり、1つのセグメントに大量のコンピュータが繋がっている場合、パケット衝突が多発するようになり回線利用効率が低下する。
ブリッジは第2層(データリンク層)の中継機能を実現する装置である。 セグメントの中継役として、流れてきたパケットのMACアドレス情報の確認と他方へのセグメントへパケットを伝送します。 ブリッジから転送される中継パケットはCSMA/CD方式であるため、衝突の発生が抑制されネットワーク使用効率が向上します。
ハブはLANケーブルのポートを複数持つ集線装置である。
- リピータハブ ・・・ リピータを複数束ねたものであり、パケットは無条件でポートへ流される
- スイッチングハブ ・・・ ブリッジを複数束ねたものであり、パケットは宛先MACアドレスに該当するCPが繋がるポートのみに流される
ルータは第3層(ネットワーク層)の中継機能を実現する装置である。 異なるネットワーク同士の中継役として、流れてきたパケットのIPアドレスを確認した後最適経路へパケットを転送する。 ルータは経路表(ルーティングテーブル)に基づいて、最適な転送先を選択する。これはルーティングと呼ばれる。
ゲートウェイは第4層(トランスポート層))以上で異なるネットワーク間においてプロコトル変換による中継機能を提供する装置である。 ネットワーク間で使われるプロコトルの差異をこの装置が変換することで互いの接続を可能とする。
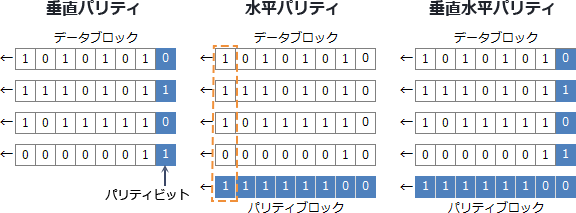
データ誤りはビットがノイズや歪により異なる値となることである。 データや誤りを確実に防ぐ方法はなく、パリティチェックやCRC(巡回冗長検査) などの手法により誤りを検出し訂正します。
パリティチェックでは送信するビット列に対しパリティビットと呼ばれる検査用のビットを付加することでデータや誤りを検出します。 特徴として1ビットの誤りを検出することができるだけである。誤り訂正ができないという問題もある。
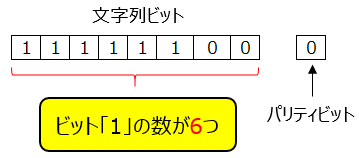
- 偶数パリティ ・・・ ビット列中の1の数が偶数になるようにパリティビットをセットする
- 奇数パリティ ・・・ ビット列中の1の数が奇数になるようにパリティビットをセットする
パリティビットはどの方向に付加するかにより、水平パリティと垂直パリティに分かれる。 垂直水平パリティチェックであればどのビット位置が誤りであるか検出することができます。
CRCはビット列を特定の式(生成多項式)で割り、余りをチェック用のデータとして付加する手法。 この方式ではデータ誤り訂正はできないが、連続したビット誤りなどを検出することが可能である。
TCP/IPは第4層(トランスポート層)のTCPと第3層(ネットワーク層)のIPというプロトコルを組み合わせたものである。インターネットのデフォルトスタンダードとなっている。
IPは経路制御を行い、ネットワーク間のパケット転送を行います。 なおコネクションレス(接続確認をとらない)型の通信であるため、通信品質は第4層プロトコルであるTCPやUDPに依存します。
TCPは通信相手とのコネクションを確立してデータを送受信するコネクション型のプロトコルである。 パケット順序や送信エラー時の再送などを制御し、送受信のデータの信頼性を保証する
UDPは通信相手と事前に接続確認を取らずに一方的にパケットを送り付けるコネクションレス型の通信プロトコルである。信頼性は欠けますが高速であり、映像配信サービスなどのリアルタイム性を重視する用途に適している。
IPアドレスは32ビットで表されるネットワーク上の住所であり、グローバルIPとプライベートIP(ローカルIP)があります。この2つの関係は電話の外線と内線に似ています。
グローバルIPアドレスはインターネットで用いるIPアドレスであり、NIC(Network Information Center)により管理される。
プライベートIPアドレスはLAN内で用いれるIPアドレスであり、LAN内での重複が発生しなければシステム管理者が自由に割り当て可能です。
IPアドレスの内容はネットワークアドレス部とホストアドレス部に分けられ、それぞれの関係は住所と名前に似ています。
- ネットワークアドレス ・・・ どのネットワーク化を示す
- ホストアドレス ・・・ どのコンピュータか示す
IPアドレスはクラスA、クラスB、クラスCの3クラスに分かれており、それぞれ32ビットの内何ビットをネットワークアドレス部に振るかの規定となっている。
| 区分 | 説明 |
|---|---|
| クラスA | 0.0.0.0 ~ 127.255.255.255: 大規模ネットワーク用 |
| クラスB | 128.0.0.0 ~ 191.255.255.255: 中規模ネットワーク用 |
| クラスC | 192.0.0.0 ~ 223.255.255.255: 小規模ネットワーク用 |
同一ネットワーク内の全てのホストに一斉に同じデータを送信することはブロードキャストと呼ばれる。 また特定の一台に送信することはユニキャスト、複数でなお且つ決められた範囲の複数ホストに送信する場合はマルチキャストと呼ばれる。
小規模ネットワークのクラスCにおいては最大254台のホストを扱えます。そこまでホストがいらず、部門ごとにネットワークを分割するにはサブネットマスクを用います。
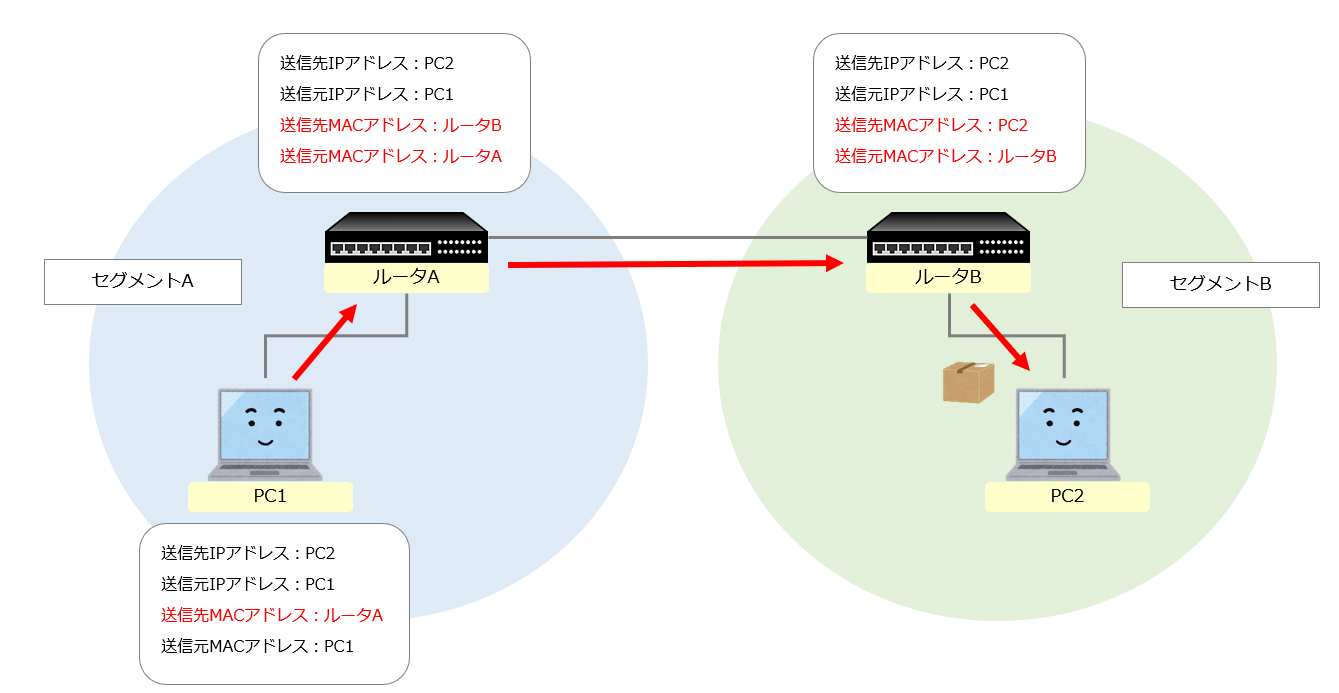
データの配送はイーサネットが行い、近距離を繋ぐのに用いられるのがMACアドレス、中継はIPアドレスが行います。
DHCP(Dynamic Host Configuration Protocol) を用いるとIPアドレスの割り当てと言ったネットワークの設定作業を自動化することができる。
NATやIPマスカレードはプライベートIPをグローバルIPに変換する技術であり、ルータに実装されています。
グローバルIPとプライベートIPを対で結び付けて相互に変換を行う。また同時にインターネット接続できるのはグローバルIPの数分のみである。
グローバルIPに複数のプライベートIPを結び付け、一対複数の変換を行う。IPアドレス変換時にポート番号を合わせ書き換えることで、1つのグローバルIPアドレスで複数のコンピュータが同時にインターネットに接続可能。
ドメイン名はIPアドレスを文字で別名を付けたものである。 「www.yahoo.co.jp」などと記載されます。 ドメイン名とIPアドレスを関連付け管理しているのがDNSサーバであり、ブラウザなどではドメイン名やIPアドレスをDNSサーバに尋ねると、それに応じたIPアドレスやドメイン名が返ります。
ネットワークの様々なサービスは第5層以降のプロコトルが提供します。 またそれらはプロコトルを処理するサーバにより提供されます。
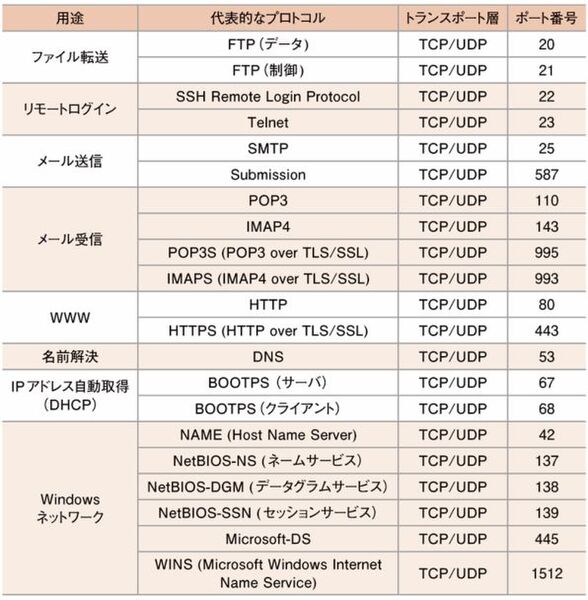
IPアドレスではコンピュータの識別はできても、そのサーバプログラムに宛てたものかまでは特定できない。 そこでその接続口としてポート番号という0~65535までの接続口をプログラム上で用意されます。
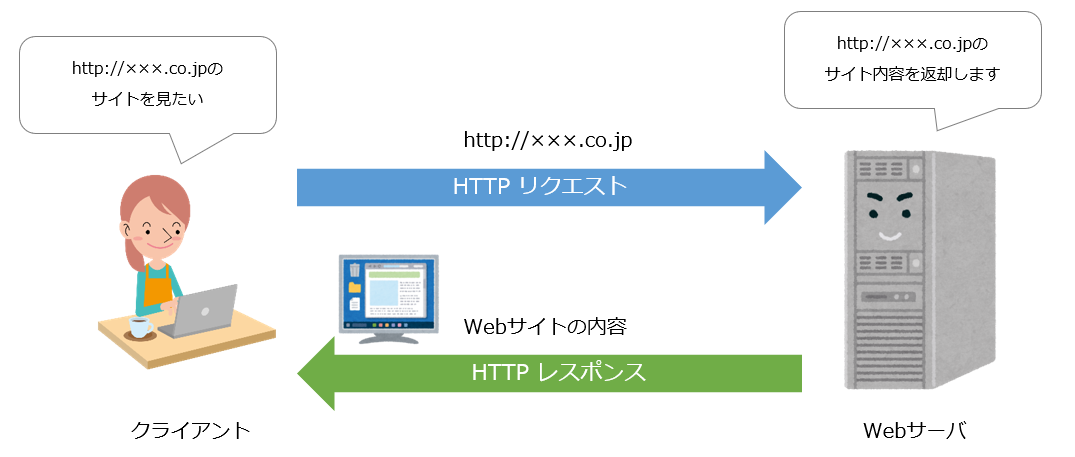
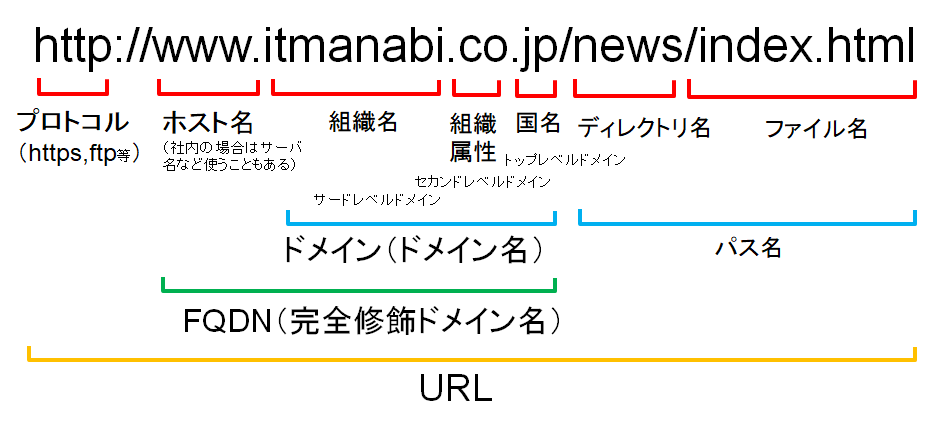
WWWは多くの人が用いるサービスであり、「http://~」とアドレスを打ち込んだりして見るサービスです。 このサービスはWEBブラウザを用いて世界中にあるWEBサーバから文字や画像、音声、動画などを得ることができます。
WebページはHTML(HyperText Markup Language)により記述されている。
URL(Uniform Resource Locator)という表記を用います。
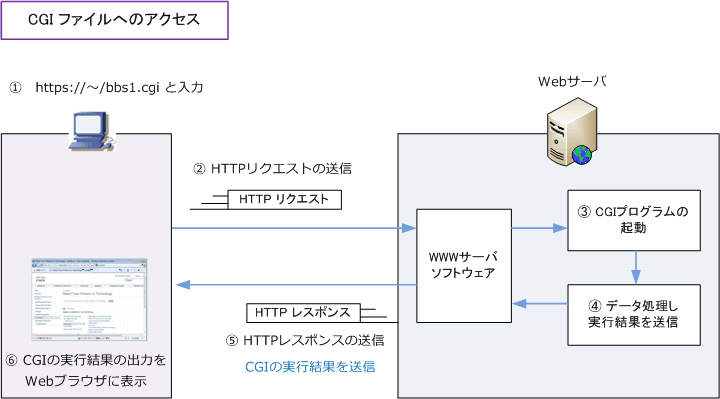
CGI(Common Gateway Interface)はWebブラウザからの要求に応じ、Webサーバで外部プログラムを実行するために用いる仕組みです。
電子メールはネットワーク上のメールサーバをポスト兼私書箱に見立て、テキストやファイルをやりとりする。 MIME(Multipurpose Internet Mail Extentions)という規格により、メールに様々なファイルを添付できるようになりました。
メールアドレスはユーザ名とドメイン名で構成されます。ユーザ名とドメイン名は@で区切られます。 例:kitakami@gmail.com
- ドメイン名 ・・・ 住所にあたる情報
- ユーザ名 ・・・ 名前にあたる情報
電子メールは目的に応じて3種類の宛先を使い分けできます。
| 種類 | 説明 |
|---|---|
| TO | 宛先である相手のメールアドレスを記載します |
| CC | 一応見てほしい(返信不要)な相手のメールアドレスを記載します |
| BCC | 他者にわからない状態で一応見てほしい相手のメールアドレスを記載します |
SMTPは電子メールを送信するプロコトルです。 SMTPに対応したサーバはSMTPサーバと呼ばれ、郵便ポストとメールの送信の役割を持ちます。
POPは電子メールをユーザが受信する際に使われるプロコトルです。 POPに対応したサーバはPOPサーバと呼ばれ、現在はPOP3がよく使われています。
IMAPはPOPと同じく電子メールをユーザが受信する際に使われるプロコトルです。 POPと異なるのは送受信データはサーバで管理されるため、どのコンピュータからでも同じデータを参照できます。
MIMEは日本語などの2バイト文字や画像データなどのファイルの添付を行えるように、電子メールの機能を拡張したものです。 MIMEには暗号化や電子署名の機能を加えたS/MIMEという規格があります。
特定のコンピュータでしか表示できない文字は機種依存文字と呼ばれます。 メールなどでは機種依存文字の使用は避けられます。
ビッグデータはインターネット上に蓄積されていく膨大なディジタルデータである。 このビッグデータは3特性を持ちます。
- Variety(多様性)
- Velocity(頻度)
- Volume(量)
これらの分析は統計的な手段を用いて行われます。
人工知能は、人に明確的な定義やプログラミングされた指示がなくても、判断材料をもとに分析・学習することで様々な判断を行えます。 AIの実現するための技術には機械学習があります。 また機械学習を発展させたものにはディープラーニングがあります。
機械学習の学習方法には3つの方法があります。
データに正解や誤りを定義する手法
データのみ与える手法
行動に対する良しあしを得点として与えることで得点が最も多く得られる方策を学習する手法
情報セキュリティでは3つの要素を管理してうまくバランスさせることが必要とされる。
- 機密性 ・・・ 情報が漏洩しないようにする
- 完全性 ・・・ 情報が書き換えられず完全な状態を保つようにする
- 可用性 ・・・ 利用者が必要なときに必要な情報を使用できるようにする
組織としてセキュリティに関してどう取り組むかを周知するものはセキュリティポリシです。
- 基本方針 ・・・ 情報セキュリティに対して組織での基本方針を定める
- 対策基準 ・・・ 基本方針を実現するために行う対策や基準を定める
- 実行手順 ・・・ 日々の業務でどのように実施するか具体的な手順を定める
個人情報保護法は個人情報が事業者が適切に扱うためのルールを定めたものです。 個人情報に関する認定制度としてプライバシマーク制度があります。これはJIS Q 15001に適合して個人情報の適切な保護体制が整備できている事業者を認定するものである。
コンピュータシステムの利用にあたりユーザ認証を行うことでセキュリティを保ちます。 ユーザ認証をパスしてシステムを利用可能な状態にすることはログイン、システムの利用を終了しログイン状態を打ち切ることはログアウトと呼ばれます。
ユーザIDとパスワードの組み合わせを用いて個人を識別する認識方法である。
指紋や声帯や虹彩などの身体的特徴を使って個人を認証する方法であり、生体認証とも呼ばれます。
一度限り有効な使い捨てのパスワードを用いる認証方法です。
サーバに接続する場合、いったんアクセスした後に回線を切り、逆にサーバからコールバックさせることでアクセス権を確認する認証方法です。
アクセス権は許可され人が操作できる権利です。操作には「読み取り」「修正」「追加」「削除」などがあります。これをユーザごとに指定します。
ソーシャルエンジニアリングはコンピュータを介さず、人の心理的不注意を用いて情報資産を盗み出すことです。 パスワードの書かれた紙の閲覧や画面の盗み見(ショルダーハッキング)、ゴミ箱から情報を抜き取る(スキャッピング)などがこれにあたります。
| 種類 | 説明 |
|---|---|
| パスワードリスト攻撃 | どこかから入手したIDとパスワードのリストを用いて他のサイトへのログインを試みる手法 |
| ブルートフォース攻撃 | 特定のIDに対し、パスワードとして使える文字の組み合わせを片っ端から試す手法で、総当たり攻撃と言われます |
| リバースブルートフォースト攻撃 | ブルートフォース攻撃の逆でパスワードが固定でIDを片っ端から試す手法です |
| レインボー攻撃 | ハッシュ値から元のパスワード文字列を解析する手法 |
| SQLインジェクション | ユーザの入力をデータベースに問い合わせ処理を行うWebサイトで悪意あのある問い合わせや操作を行うSQL文を埋め込みデータベースのデータの改ざんや不正取得を行う手法 |
| DNSキャッシュポイズニング | DNSのキャッシュ機能を悪用し偽のドメインを覚えさせることで、偽装サイトへ誘導する手法 |
rootkit(ルートキット) は攻撃者が不正アクセスに成功したコンピュータを制御できるようにするソフトウェアの集合です。 rootkitには侵入の痕跡を隠蔽するログ改ざんツールや、リモートからの侵入を簡単にするバックドアツール、改ざんされたシステムツール群などが含まれる。
コンピュータウィルスは以下の3つの基準のうち1つを満たすとコンピュータウィルスと定義づけられます。(経産省基準)
- 自己伝染機能
- 潜伏機能
- 発病機能
| 種類 | 説明 |
|---|---|
| 狭義のウィルス | 他のプログラムに寄生し、その機能を利用する際に発病するもの |
| マクロウィルス | アプリケーションのもつマクロ機能を悪用したものでデータファイルに寄生し感染を広げる |
| ワーム | 事故単身で複製を生成し、ネットワークを介し感染を広めるものであり作成が容易である |
| トロイの木馬 | 有用なプログラムであるように見せかけて、実行をユーザに促しその裏で不正な処理を行うもの |
マルウェアと呼ばれる悪意のあるソフトウェアがあります。これらの種類は以下の通りです
| 種類 | 説明 |
|---|---|
| スパイウェア | 情報収集を目的としたプログラムで、個人情報を収集し外部に送信する |
| ボット | 感染したコンピュータをボット制作者の指示通りに動かすものである |
ウィルス対策ソフトはコンピュータに入ったデータをスキャンし、データに問題がないかをチエックします。 ウィルス対策ソフトがウィルスを検出するためには既知のウィルス情報を記したウィルス定義ファイルが必要であり、これを常に最新状態に保つことが重要である。
ビヘイビア法は実行中のプログラムの挙動を監視して、不審な処理が行われていないか検査する方法であり、未知のウィルスを検出できます。 方法としては監視下で直接実行させて不審な動きがあるプログラムは即座に停止させ、仮想環境でも実行させて危険な行動か監視します。
LANの中と外を仕切る役割をするのがファイヤーウォールであり、機能のことを指すため定まったせっえち方法はない。 実現方法にはパケットフィルタリングやアプリケーションゲートウェイがあります。
パケットフィルタリングではパケットのヘッダ情報を見て、通過の可否を判定します。 通常アプリケーションが提供するサービスはプロコトルとポート番号で区別されるため、通過させるサービスを選択することとなる。
アプリケーションゲートウェイはプロキシサーバとも呼ばれ外部とのやり取りを代行して行う機能である。 通信する側から見るとプロキシサーバしか見えないため、LAN内のコンピュータにが不正アクセスの標的になることを防ぐことができます。 アプリケーションゲートウェイ型のファイヤーウォールにはWAF(Web Application Firewall) があり、Webアプリケーションに対する外部アクセスを監視するもので、パケットフィルタリングと異なり、通信データの中身までチェックすることで悪意を持った攻撃を検知する。
ペネトレーションテストは既存手法を用いて実際に攻撃を行い、これによりシステムのセキュリティホールや設定ミスと言った脆弱性の有無を確認するテストです。
暗号化とディジタル署名はパケットに鍵をかけるようなものです。 ネットワーク上に潜む危険は以下の3種類があります。
- 盗聴 ・・・ 送信したデータ内容を第3者に盗み読まれる危険性
- 改ざん ・・・ データやり取りは正常に見えるが途中で第3者に書き換えられる危険性
- なりすまし ・・・ 第3者になりすまし、データを送受信できてしまう危険性
送り手と受け手が同じ鍵を用いる暗号化方式は共通暗号化方式または秘密鍵暗号方式と呼ばれます。
公開鍵暗号方式は公開鍵という公用の鍵を持ち、公用鍵は公開して暗号化し、複合には秘密鍵を用いる方式です。 共通鍵暗号方式よりも暗号化や復号に大変時間がかかります。
暗号化にはデータ全体を暗号化するのではなく、ハッシュ化という手法で短い要約データ(メッセージダイジェスト)を作成しそれを暗号化することでディジタル署名とする。 元データが同じ場合、ハッシュ関数は必ず同じメッセージダイジェストを生成するため、復号結果と受信したデータから新たに取得したメッセージダイジェストを比較して一緒であれば改ざんしていないと言える。
認証局(CA)は公開鍵がその本人のものであるか証明する機関です。 認証局に公開鍵を登録し、登録した鍵によりその身分を保証するという仕組みです。 この認証機関と公開鍵暗号技術を用いて通信の安全性を保証する仕組みは公開鍵基盤(PKI) と呼ばれます。
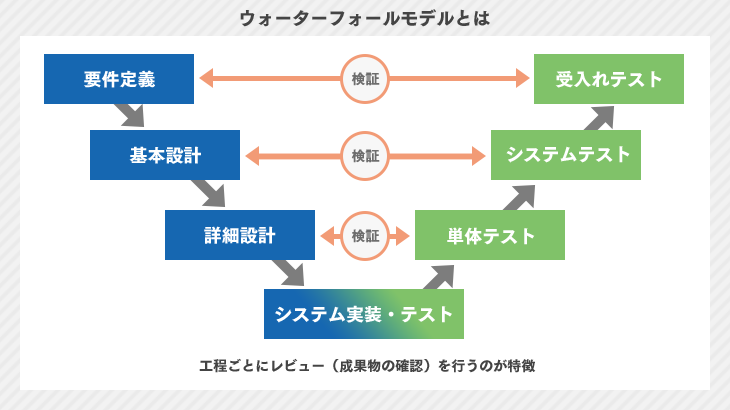
システムは企画→要件定義→開発→運用→保守というフェーズでシステムの一生は表せられソフトウェアライフサイクルと呼ばれます。
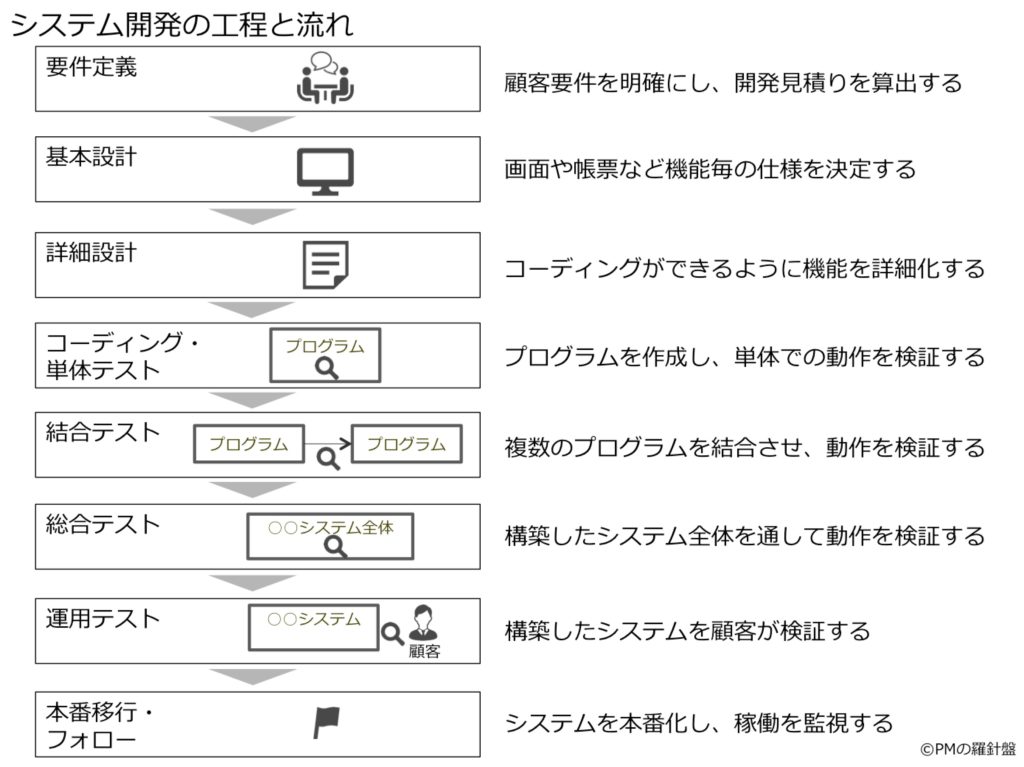
この工程は作成するシステムにどんな機能が求められているか明らかにします。 要件を取りまとめた結果について要件定義書という形で文書に残します。
要件定義の内容を具体的なシステムの仕様に落とし込む作業です。 システム設計は主に3つの段階に分かれます。
「利用者から見た」設計を行います。ユーザインターフェスなどの利用者が直接手を触れる部分の設計を行う。
「開発者から見た」設計を行います。外部設計を実現s塗るための実装方法やデータ設計などを行います。
プログラムをどう作るかという視点で設計を行います。プログラムの構造化設計やモジュール同士のインターフェス仕様がこれにあたります
モジュールレベルの動作確認を行います。
モジュールを結合させた状態で動作確認や入出力の検査を行います。
システム全体を稼働させて動作確認や負荷試験などを行います。
実際の運用と同じ条件下で動作確認を行います。
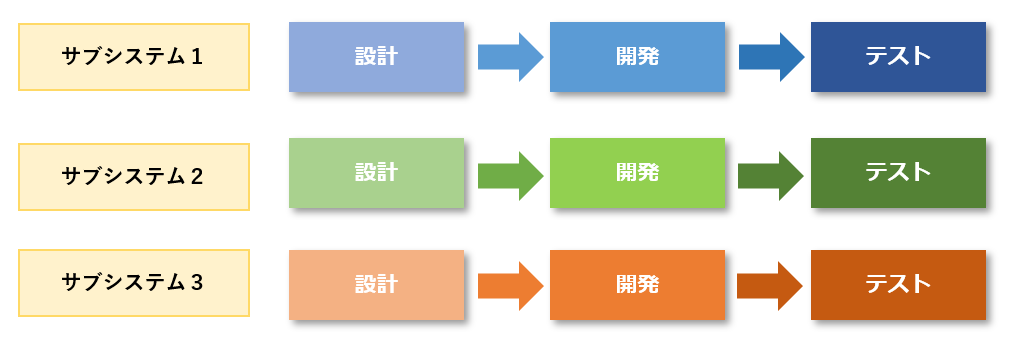
CASEはコンピュータ支援ソフトウェア工学という意味です。CASEツールはシステム開発を支援するツールです。 開発に関する情報はリポジトリというデータベースで管理します。
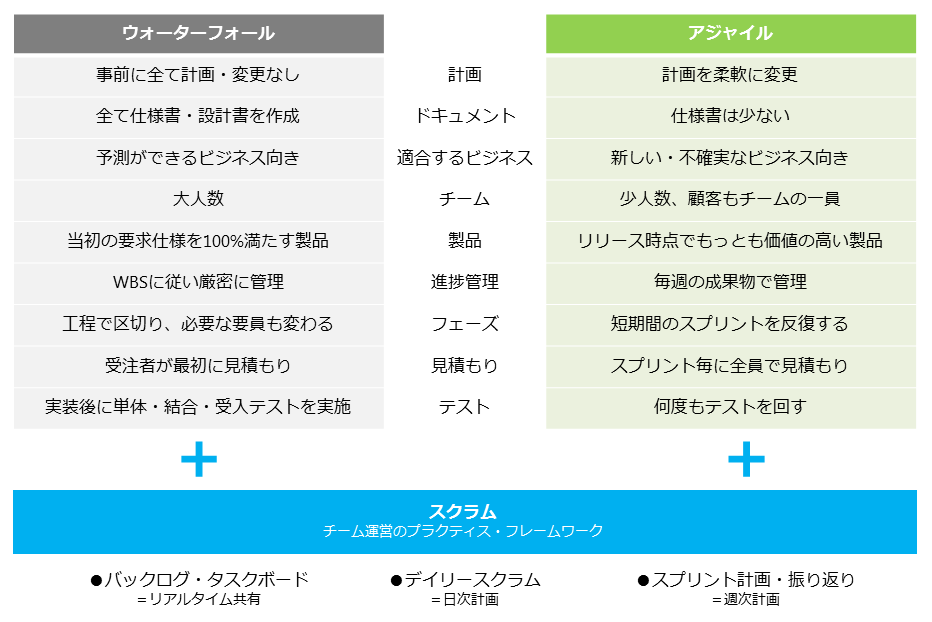
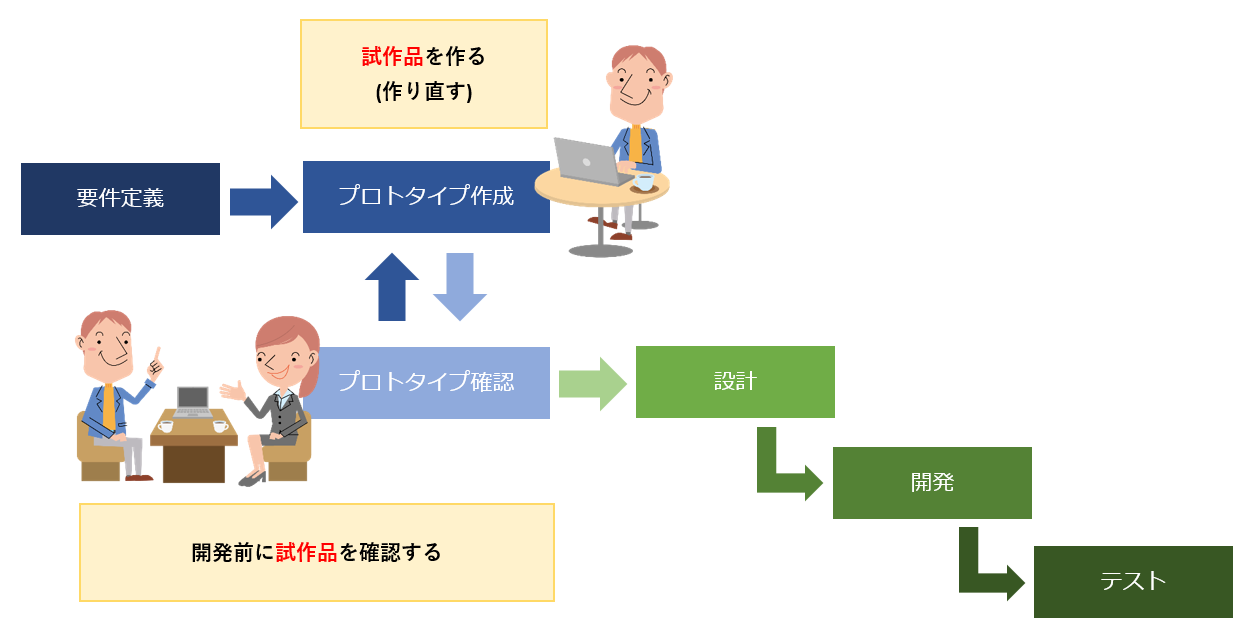
RADは迅速なアプリケーション開発という意味であり、エンドユーザと開発者による少数構成のチームを組み、開発支援ツールを活用するなどして、とにかく短期間で開発することを重要視した開発手法です。 RADツールとして有名なのはVIsual Basicのビジュアル開発環境などが該当します。 RADではプロトタイプを作成しそれを評価するサイクルを繰り返すことで完成度を高めます。このフェーズが無限に繰り返されないように開発の期限を設けます。これはタイムボックスと呼ばれます。
アジャイル開発はスパイラルモデルの派生型であり、より短い反復単位を用いて迅速に開発を行う手法である。この開発手法では1つの反復で1つの機能を開発し、反復を終えた時点で機能追加されたソフトウェアをリリースします。 アジャイル開発の一種であるXPは少人数の開発に適用しやすいとされ、既存の開発手法が仕様を固めて行う方式であったのに対し、XPは変更を許容する柔軟性を実現します。 XPでは5つの価値と19のプラクティスが定義されており、そのうち開発プラクティスとして定められているのは以下6つである。
| プラクティス | 説明 |
|---|---|
| テスト駆動開発 | 実装前にテストを定め、テストをパスするように実装を行う。テストは自動テストであることが望まれる |
| ペアプログラミング | 2人1組でプログラミングを行う。1人がコードを書きもう1人がコードの検証役になり、互いの役割を入れ替えながら作業を進める |
| リファクタリング | 完成したプログラムでも内部のコードを随時改造する。冗長コードを改めるに留める。 |
| ソースコードの共有所有 | コードの制作者に断りなく、チーム内の誰もが修正を行うことができる。チーム全員がコードの責任を負う |
| 継続的インテグレーション | 単体テストを終えたプログラムはすぐに結合し結合テストを行う |
| YAGNI | 今必要とされるシンプル機能だけの実装に留める |
リバースエンジニアリングは既存のソフトウェアの動作を解析することで、プログラムの仕様やソースコードを導き出す手法。 目的は既にあるソフトウェアを再利用することで、新規開発を手助けすることである。 これによって得られた仕様をもとに新しいソフトウェアを開発する手法はフォワードエンジニアリングと言う。 フォワードエンジニアリングはオブジェクトコードを逆コンパイルしてソースコードを取り出したりします。 これを元となるソフトウェア権利者の許諾なく行うと知的財産権の侵害にあたるため注意が必要である。
公開されている複数のサービスを組み合わせることにより新しいサービスを作り出す手法はマッシュアップと呼ばれます。
モデル化は現状のプロセスを抽象化し視覚的に表すことであり、システムが実現すべき機能の洗い出しのために行われます。 代表的なものにDEFとER図があります。
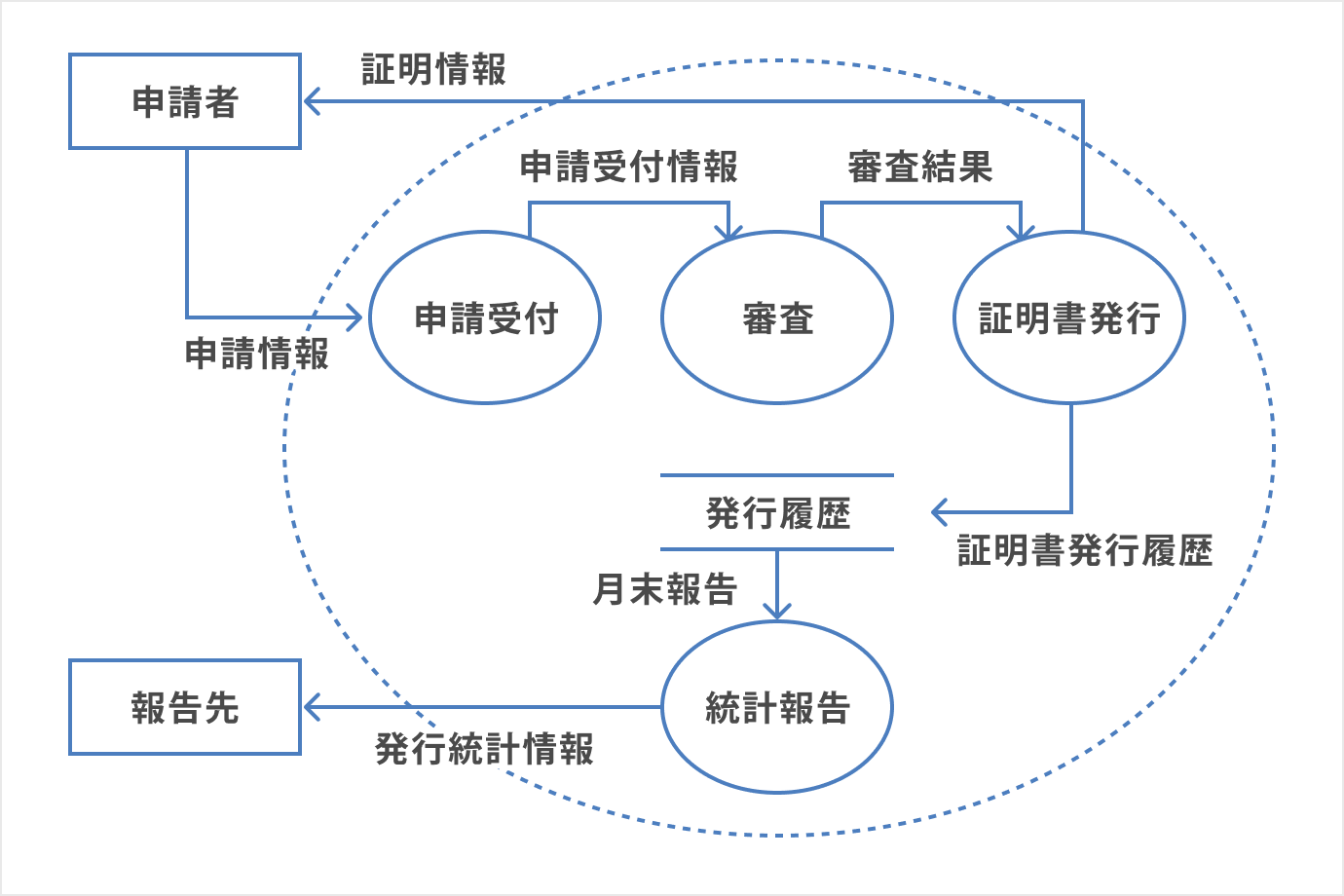
DEFはデータの流れを図として表したものです。
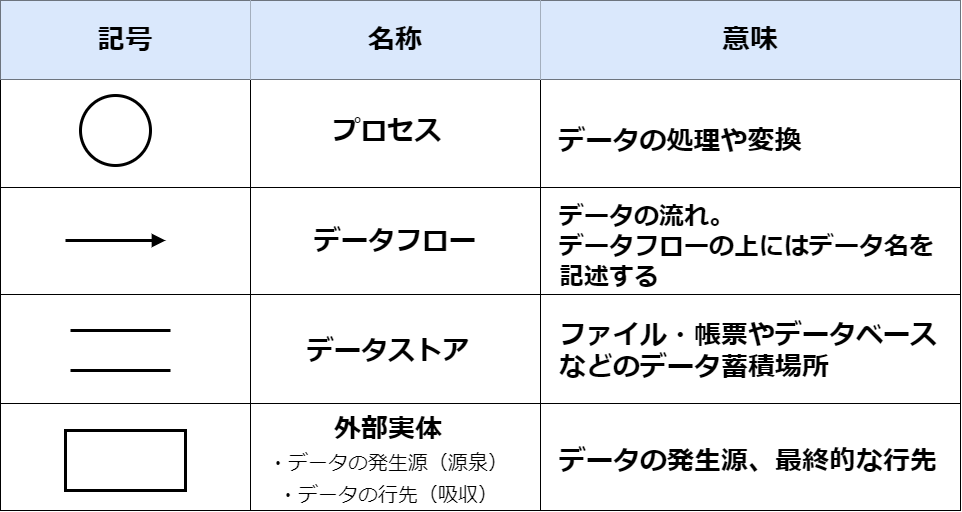
DFDの例
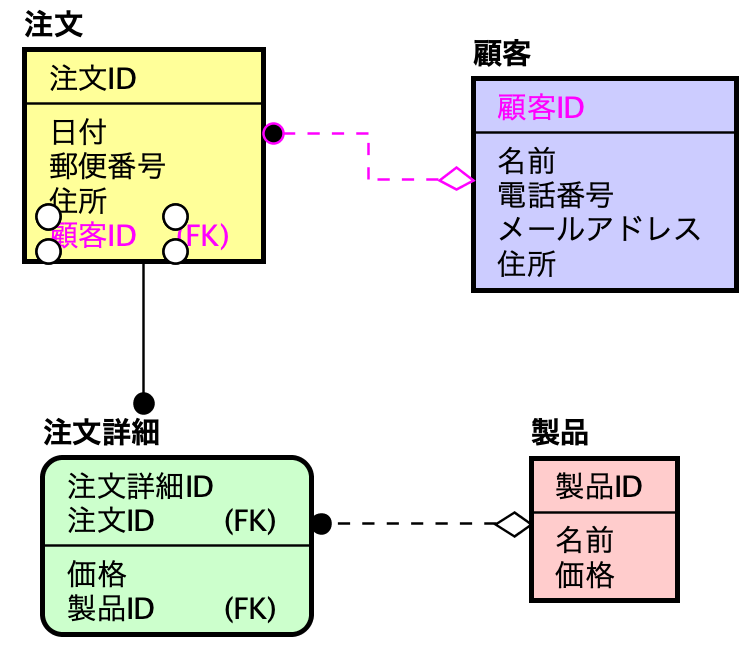
ER図は実体と関係という概念を用いてデータ構造を図に表したものである。
CUIは文字を打ち込むことでコンピュータに命令を伝えて処理させる方式です。マウスなどは一切用いません。 GUIは画面にアイコンやボタンを表示してそれをマウスなどのデバイスで操作し命令を伝えるグラフィカルな操作方式であり現在の主流である。
| 部品 | 説明 |
|---|---|
| メニューバ | アプリケーションの基本領域であり、ここに各コンポーネントが配置されます |
| ウィンドウ | アプリケーションを操作するための項目が並んだメニュー |
| プルダウンメニュ | クリックすると垂れ下がり表示されるメニュー |
| テキストボックス | 文字入力用の短形領域である |
| チェックボックス | 選択肢を複数選択したり特定の項目をON/OFFさせる用途に用いられる |
| ラジオボタン | 複数ある選択肢から1つだけを選ばせるのに用いる |
コード設計で定めたルールは運用開始後に変更することが難しくなります。そのため将来的に扱うデータ量や将来予測を行い、適切な桁数や割り当て規則を定める必要がある。 入力ミスや読み取りミスを検出する方法にチェックディジットを使用する方法があります。
チェックディジットは誤入力を判定するためにコードへ付加された数字のことである。

| チェック方法 | 説明 |
|---|---|
| ニューメリックチェック | 数値として扱う必要のあるデータに文字など数値として扱えないものが含まれていないかチェックします |
| シーケンスチェック | 対象とするデータが一定の順序で並んでいるかをチェックする |
| リミットチェック | データが適切な範囲内にあるかチェックします |
| フォーマットチェック | データの形式が正しいかチェックします |
| 照合チェック | 入力されたコードが表中に登録されているかチェックします |
| 論理チェック | 販売数と在庫数と仕入れ数関係なく対となる項目の値に矛盾がないかチェックします |
| 重複チェック | 一意であるべきコードなどが重複して複数個登録されていないかチェックします |
各プログラムをモジュール単位に分解・階層化させることはプログラムの構造化設計と言います。 シンプルで保守性に優れたプログラムを作るための構造化設計のためのモジュール分割法には「データの流れに注目した技法」と「データの構造に注目した技法」があります。
モジュール分けのメリットとして以下のような点があげられます。
- 作業の分担が可能
- 再利用が簡単
- 修正が一部で済む
モジュール分けした後の作業は3つの制御構造を用いてプログラミングする構造化プログラミングへと移ります。
「データの流れ」に着目した技法は以下の3種類です。
入力処理、変換処理、出力処理という3つのモジュール構造に分割する手法
プログラムを一連の処理(トランザクション)単位に分割する方法
プログラム中の共通機能をモジュール分割する方法
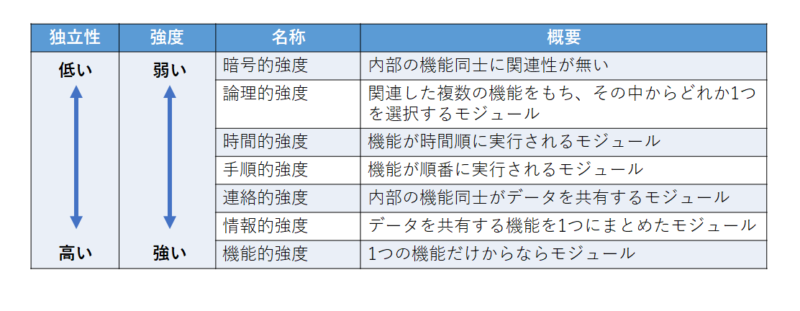
モジュールの独立性を測る尺度として用いられるのはモジュール強度とモジュール結合度です。

単体テストでは各モジュールごとにテストを個なって誤りがないかを検証します。この手法ではブラックボックステストやホワイトボックステストという手法を用いて検証を行います。
結合テストでは複数のモジュールを繋ぎ合わせて検証を行い、モジュール間のインターフェスが正常に機能しているかを確認します。
システムテストはさらに検証の範囲を広げてシステム全体のテストを行う。
- 機能テスト ・・・ 要求された機能がちゃんと動くのか確認する
- 性能テスト ・・・ 処理能力は十分か確認する
- 負荷テスト ・・・ 高い負荷の下でも問題ないかを確認する
テストの流れは以下の通りです。 単体テスト→結合テスト→システムテスト
モジュールの内部構造は意識せず入力に対して適切な出力が仕様通りに得られるかを確認します。
モジュール内部構造が正しく作られているかを検証します。入出力は構造をテストするためだけに過ぎない。
ブラックボックステストを行うさいに入力値をしっかり定義づけることが大切です。その入力テストデータを作成する基準として用いらるのは同値分割と限界値分析である。
データ範囲を種類ごとのグループに分け、それぞれから代表的な値を抜き出してテストデータとして用います。
限界値分析では上記グループの境目部分を重点的にチェックします。境界前後の値をテストデータに用い、境界値分析と言います。
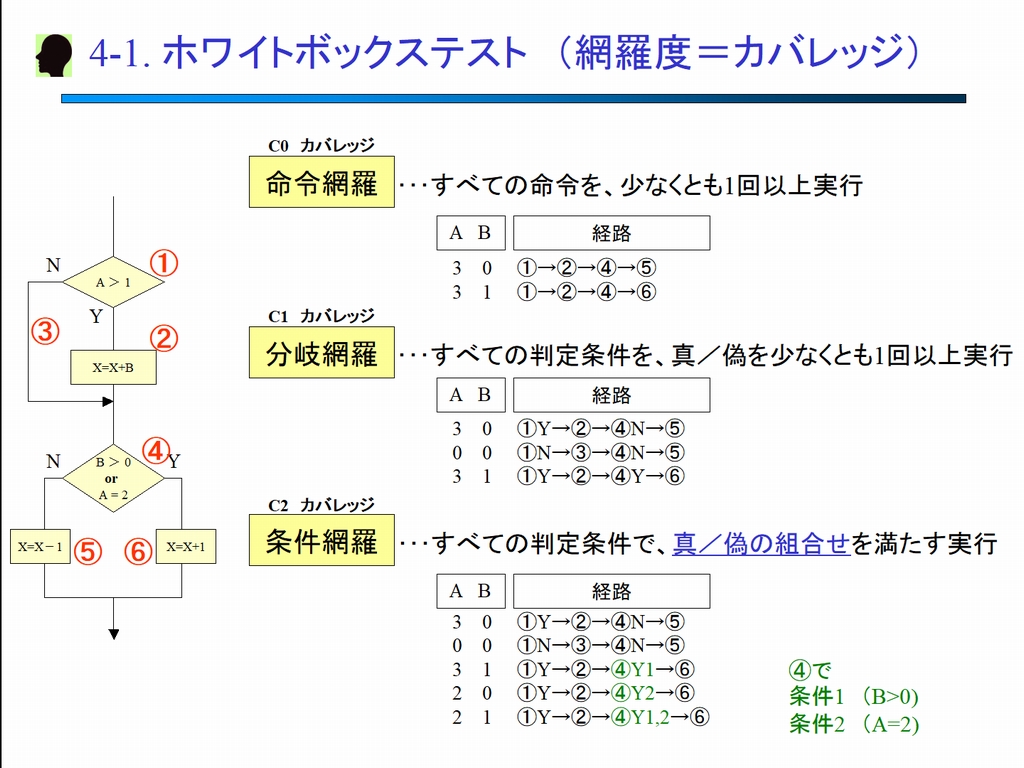
ホワイトボックステストを行うにあたって、どこまでのテストパターンを網羅するか定めた上でテストケースを設計します。
上位モジュールから先にテストを済ませていく方式。 未テストの下位モジュールはスタブと呼ばれ仮のインターフェスとつなげ確認します。
下位モジュールからテストを行う方式。 ドライバと呼ばれる仮のモジュールをくっつけインターフェスの確認を行います。
トップダウンテストとボトムアップテストを組み合わせて行う折衷テストやすべてのモジュールを一気につなげるビッグバンテストがある。
リグレッションテスト(退行テスト) はプログラムを修正した時にその修正内容が正常に動作していた部分まで悪影響を与えていないかを確認するテストです。
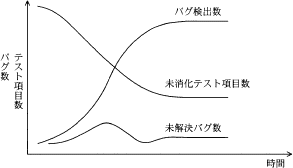
テスト終了、品質向上の十分性を判断する指標としてバグ管理図があります。
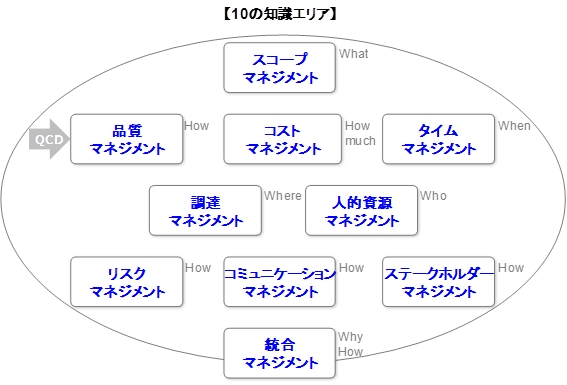
開発プロジェクトの技法を体系的にまとめたものにPMBOK(Project Management Body of System) があります。PMBOKは米国のプロジェクトマネージメント協会が規格化した知識体系で国際標準化されています。
WBSはプロジェクトに必要な作業や成果物を階層化した図で表すものであり、PMBOKのスコープ管理に用いられます。
システムの開発の見積もり方法には以下のようなものがあります。
従来の手法で、ソースコードの行(ステップ)数により開発コストを算出する手法
標準画面、印刷する帳票、出力ファイルなどユーザから見える機能に着目し、その個数や難易度から開発コストを算出する方法
システム開発のスケジュール管理にはガントチャートやアローダイアグラムなどが活用されます。
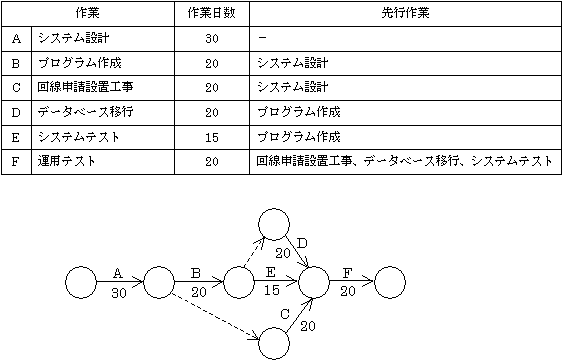
スケジュール短縮のために用いる代表的手法がクラッシングとファストトラックキングの2つがある。
クラッシングは資源を追加投入してコストの増大を最小限に抑えながらスケジュールの所要時間を短縮する技法である。
ファストトラックキングとは通常は順番に実施させるアクティビティやフェーズを並行して逐行するスケジュール短縮法である
ITサービスを提供するにあたっての管理・運用規則に関するベストプラクティスが体系的にまとめられましたITILと呼ばれます。 ITILは大きく分けてサービスサポートとサービスデリバリの2つにより拘束されます。
サービスレベルアグリーメント(SLA)はサービスレベル合意書であり、サービスの利用者と提供者の間で「どのようなサービスをどういった品質で提供するか」を取り決めて明文化したものである。 設定した目標を達成するために、計画-実行-確認-改善というPDCAサイクルを構築し、サービス水準の維持・向上に努める活動はサービスレベルマネージメント(SLM) と呼ばれる。
サービスサポートは1つの機能と5つの業務プロセスにより構成されます。

ユーザの拠点内、もしくは物理的に近い場所に設けられたサービスデスクである。
1か所に窓口を集約させたサービスデスクである。
インターネットなどの通信技術を利用することで、実際には各地に分散しているスタッフを疑似的に1か所で対応しているように見せかけるサービスデスクである。
ITILの中で長期視点でITサービスの計画と改善を図ることはサービスデリバリは5つの業務プロセスにより構成されます。

ファシリティマネジメントはサーバなどに設備を適切に管理・改善する取り組みのことで施設管理と呼ばれます。 UPSは無停電電源装置と呼ばれ、外付けバッテリのような使い方のできる装置である。
ITガバナンスは組織がITに関するすべての活動、成果及び関係者を適正に統一し、目指すべき姿へと導くための仕組みを組み込むことである。
システム監査人には次の要素が求められます。
- 外見上の独立性
- 精神上の独立性
- 職業倫理と誠実性
- 専門能力
↓
↓
↓
可監査性は処理の正当性や内部統制を効果的に監査、レビューできるようにシステムが設計運用されていることである。 またシステムにおける事象発生から最終結果に至るまでの一連の流れを時系列に沿った形で追跡できる仕組みは監査証跡と呼ばれます。
監査意見には保証意見と助言意見の2種類があります。 またシステム監査人が行う改善指導はフォローアップと呼ばれます。
ソースコードに書かれた命令を1つずつ機械語に翻訳しながら実行します。逐次翻訳するため動作を確認しながら作っていくことが容易に行えます。
ソースコードの内容を最初に全て機械語に翻訳します。作成途中で確認のため動かすと言った手法は用いれません。
コンパイラ方式のプログラムの場合、その過程でコンパイラ以外にリンカとローダが使われます。
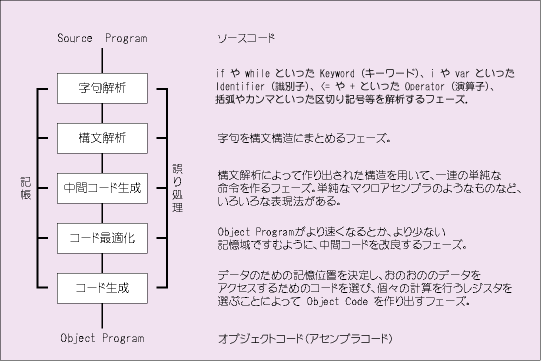
プログラムは自分で分割したモジュールやライブラリとしてあらかじめ提供されている関数や共通モジュールなどすべてつなぎ合わせる作業はリンク(連係編集) と呼ばれます。これがリンカの仕事です。 あらかじめリンクさせておく手法は静的リンキングと呼ばれます。またこの時点ではリンクさせず、プログラムの実行時にロードしてリンクする手法は動的リンキングと呼ばれます。
ロードモジュールを主記憶装置に読み込ませる作業はロードと呼ばれます。これを担当するプログラムがローダである。
構造化プログラミングはプログラムを機能単位の部品に分けて、その組み合わせで全体を形作るプログラミングです。
構造化プログラミングでは原則的に3つの制御構造を使ってプログラミングを行います。
- 順次構造 ・・・ 上から順番に処理を実行します
- 選択構造 ・・・ 何らかの条件によって分岐させいずれかの処理を実行させます
- 繰返し構造 ・・・ ある条件が満たされるまで一定の処理を繰り返します
変数はメモリの許す限りいくらでも使うことができ、変数は名前を付けて管理します。
コンピュータはプログラムに書かれたアルゴリズム(作業手順) にのっとり動作します。 アルゴリズムをわかりやすく記述するために用いるのがフローチャートである。

メモリの連続した領域にデータを並べて管理するのが配列です。 配列は固定サイズでまとめて領域を確保するため、データの削除や挿入は苦手です。
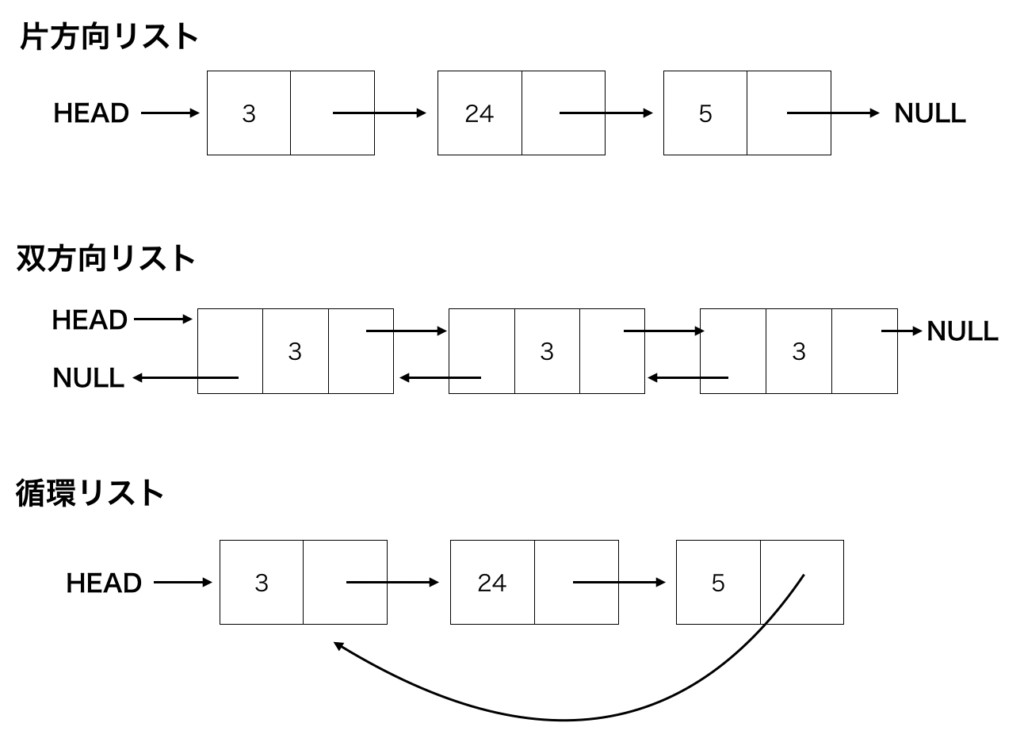
データ同士を数珠つなぎにして管理するのがリストです。 リストの扱うデータはポインタと呼ばれる番号がセットになっています。これはメモリ上の位置を表す番号で次のデータがメモリのどこにあるかを指し示します。 リストの特徴として、ポインタ順にデータをたどるため、配列のように添え字を使い各データに直接アクセスする使い方はできない。
リストの一般的構造です。一方通行です。
次のデータと前のデータのポインタを持つリストです、前後どちらにもリストをたどれます。
最後尾データは先頭データのポインタを持つリストです。
キュー(待ち行列)は最初に格納したデータから順に処理を行うFIFO方式のデータ構造である。
スタックはキューの逆で最後に入れたデータから処理を行うLIFO方式のデータ構造である。
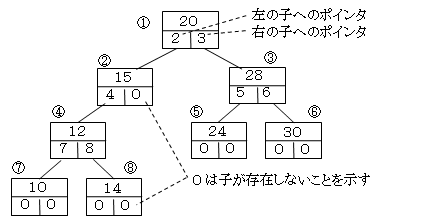
ツリー構造のうち節から延びる枝が2本以上のものは2分木と呼ばれます。
また2分木は左右の子にポインタを付加すると次のような配列構造になります。
葉以外の節がすべて2つの子を持ち、根から葉までの深さが等しい2分木は完全2分木と呼ばれます。
ツリーの左分木と右分木の関係が「左<親<右」となる2分木は2分探索木と呼ばれます。 このツリー構造ではデータ探索を節の中身と比較して簡単に行えます。
探索のアルゴリズムには主に以下のようなものがあります。
先頭から順に探索していく方法は線形探索法と呼ばれます。 線形探索法では番兵と呼ばれる目的のデータを配列最後尾につけることでフロー処理の簡素化を行えます。
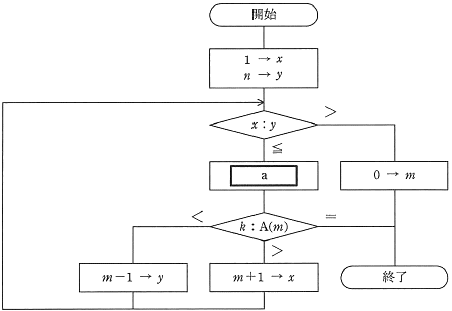
探索対象のデータ列が昇順か降順の場合、2分探索法を実施することで効率よくデータを求められます。 流れは次のようになります。
- データ構造の真ん中のデータを求めているデータと比較します
- 求めているデータに近い方の範囲(右か左)を絞り込みます
- 絞り込んだ範囲の真ん中のデータと求めているデータを比較します
- 1から3を繰り返すと求めたいデータが求まります。
フローチャートは以下のようになります。
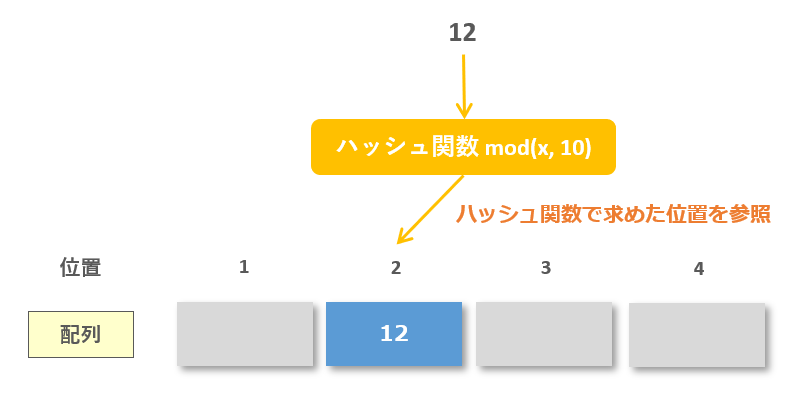
ハッシュ関数と呼ばれる「一定の計算式」を用いてデータの格納位置を算出する方法です。 なおデータの登録もハッシュ関数を用いて行われる必要があります。 シノニムが発生する場合オープンアドレス法やチェイン法でデータを追加します。
先頭にあるときと末尾にあるときの平均なので、平均探索回数は (0+n)/2 :nはデータ範囲の最大値
半分ずつに絞り込みを行うので対数logを使うと、平均探索回数はlog2n :nはデータ範囲の最大値
シノニム(コリジョン)の発生確率が無視できるほど小さい場合、平均探索回数は1回
隣接するデータの大小を比較し、必要に応じて入れ替えることで全体を整列させるのがバブルソートである。
対象とするデータの中から最小値(or最大値)のデータを取り出し、先頭データと交換しこれを1つずつずらして繰り返すことで整列させるのが選択ソートである。
データ列を「整列済みのもの」と「未整列なもの」に分け、未整列の側からひとつずつ整列済みの列の適切な位置に挿入し、全体を整列させる手法が挿入ソートである。
ある一定間隔沖に取り出した要素からなる部分列を整列しさらに間隔を詰めて同様の操作を行い、間隔が1になるまで繰り返して整列させる手法
中間的な基準値を決めてそれよりも大きな値を集めた区分と小さな値を集めた区分に要素を振り分けてこれを繰り返すことで整列する手法
未整列データを順序木に構成し、そこから最大値(or最小値)を取り出して既整列に移す。これを繰り返して未整列部分をなくしていって整列する手法
オーダ記法はアルゴリズムの計算量(実行時間)をO(式) の形で表すことです。
平均計算時間≒オーダ
処理の対象をオブジェクトという概念でとらえ、オブジェクトの集まりとしてシステムの設計開発を行うことはオブジェクト指向プログラミングと呼ばれます。 詳細に説明するとオブジェクトはデータ(属性)とそれに対するメソッド(手続き)を一つにまとめた概念である。 オブジェクト指向でプログラムを設計するとモジュールの独立性が高く保守しやすいプログラムの作成が可能です。
オブジェクト指向プログラミングではカプセル化できることが大きな特徴です。カプセル化することでオブジェクト内部の構造は外部から知ることができなくなります。つまり、情報隠蔽ができることがカプセル化の利点である。 カプセル化を用いるとオブジェクトの実装方法に修正を加えてもその影響を最小限にとどめることができます。
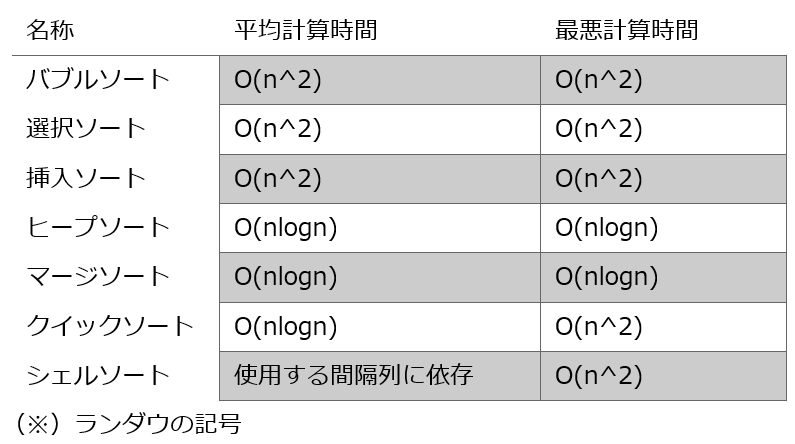
オブジェクトはデータとメソッドを定義したものでした。この「オブジェクトがもつ性質」を定義したものはクラスと呼ばれます。
言い換えると、オブジェクトの設計図がクラスであり、データやメソッドを持っています。
この設計図に対して具体的な属性値を与えメモリ上に実体化させたものはインスタンスと呼ばれます。
クラスの基本的な考え方はオブジェクトを抽象化し定義することです。 クラスの階層化というのはクラスに上位、下位の階層を持たせることができるというものです。 下位クラスは上位クラスのデータやメソッドの構造を受け継ぐことができます。 上位クラスはスーパクラス(基底クラス) 、下位クラスはサブクラス(派生クラス) と呼ばれます。 サブクラスがスーパクラスの特性を引き継ぐことは継承(インヘリタンス) と呼ばれます。
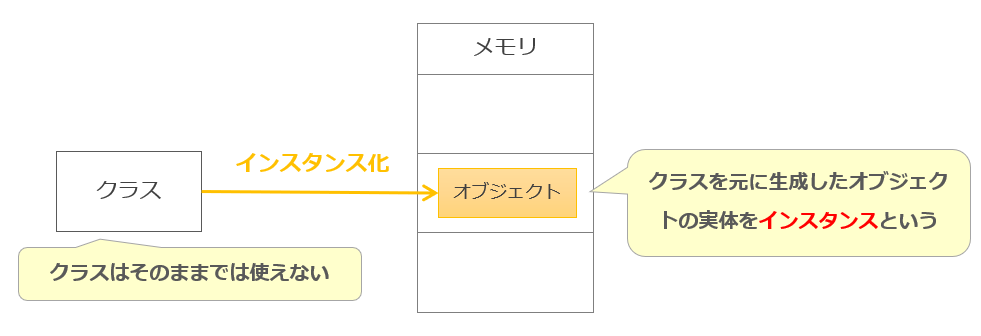
汎化は下位クラスが持つ共通性質を抽出し上位クラスとして定義することです。
特化は抽象的な上位クラスをより具体的なクラスとして定義することです。
それぞれの関係は下記図のようになります。
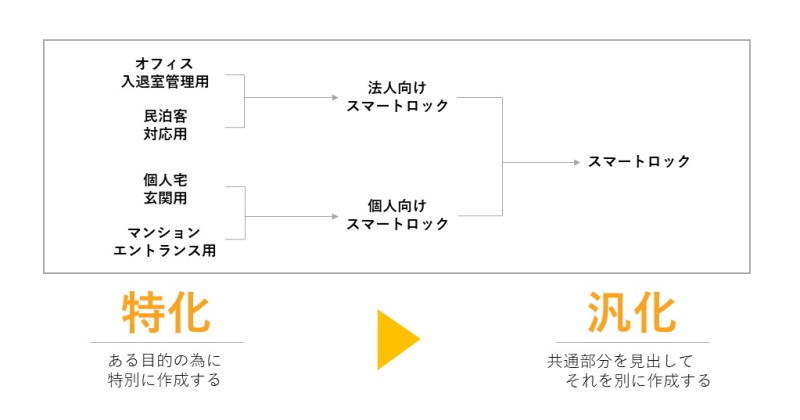
下位クラスは上位クラスの特性を分化して定義したもの。上位クラスは下位クラスを集約して定義したものという関係です。
多態性は同じメッセージを複数のオブジェクトに送ると、それぞれが独立した固有の処理を行うというものです。
UMLはオブジェクト指向分析・設計において用いられる統一モデリング言語である。 またこれは複数人で設計モデルを共有してコミュニケーションをとるための手段です。 UMLでは13種類の図が規定されています。これらはダイヤグラムと呼ばれます。
UMLの図は構造図と振る舞い図に分類できます。

クラスの定義や関連付けを示す図である。 クラス内の属性と操作を記述し、クラス同士を線でつないで互いの関係を表します。
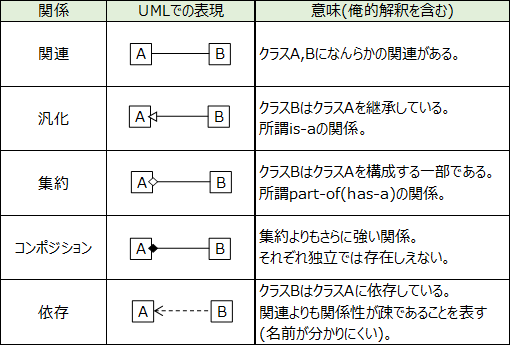
利用者視点でシステムが要求に対してどう振る舞うかを示す図である。
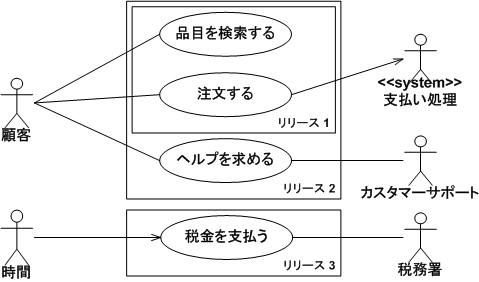
業務や処理のフローを表す図である。
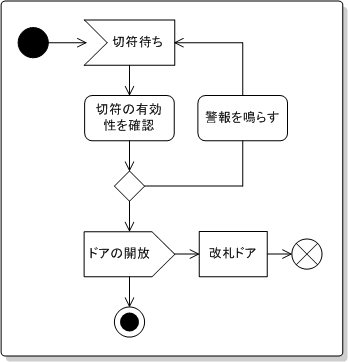
オブジェクト間のやり取りをし系列に沿って表す図である。オブジェクト同士の相互作用を表すもので、オブジェクト下の点線で生成から消滅までを表しそこで行われるメッセージのやり取りを矢印で表します。
クライアントサーバシステムは現在の主流の処理形態です。これは基本的には分散処理を行い、ネットワーク上の役割を2つに分け集中して管理や処理を行う部分をサーバとして残すことが特徴です。
シンクライアントにおけるクライアント側の端末は入力や表示部分を担当するだけで情報の処理や保管はすべてサーバに任せます。
ピアツーピアは完全分散処理型のシステムです。これはネットワーク上で協調動作するコンピュータ同士が対等な関係でやり取りをするものでサーバなどの一次元的に管理するものが必要としません。
クライアントサーバシステムの機能をプレゼンテーション層、ファンクション層、データ層の3つに分けて構成するシステムのことです。これに対し通常のクライアントサーバシステムのことは2層クライアントサーバシステムと呼ばれています。
・ビジネスロジックに変更があるとすべてのクライアントに修正が必要となる ・処理に必要なデータがネットワーク上を流れるので帯域を圧迫する ・データベースをロックする時間が長くなりがち
・GUI操作を行うだけなのでシンクライアントが使用可能 ・処理結果が返ってくるだけなのでネットワーク上を流れるデータ量の削減可能 ・ビジネスロジックに変更があってもサーバ側だけ修正すればよい ・サーバ側で処理が完成する分データベースをロックする時間も短く済む
普段コンピュータを使って普通に行う操作を対話型処理と呼ばれます。
システムの稼働形態として要求に対して即座に処理行い結果が反映されるものはオンライントランザクション処理と呼ばれます。
リアルタイムにすぐに反映する必要のない処理の場合、一定期間ごとに処理をまとめて実行するものはバッチ処理と呼ばれます。
システムの性能を評価する指標にはスループット、レスポンスタイム、ターンアラウンドタイムがあります。 これらを評価する手法にはベンチマークテストがあります。これは性能測定用のソフトウェアを使って、システムの各処理性能を数値化するものです。
スループットは単位時間あたりに処理できる仕事量をあらわします。

レスポンスタイムはコンピュータに処理を依頼し終えてから実際に何か応答が返されるまでの時間を示します。
ターンアラウンドタイムはコンピュータに処理を依頼し始めてその応答がすべて返されるまでに時間を示します。
デュアルシステムは2組のシステムを使って信頼性を高めるものです。このシステムでは2組のシステムが同じ処理を行いながら、処理結果を互いに突き合わせて誤動作していないかを監視します。いずれかが故障した場合に異常の発生したシステムを切り離し、残る片方だけでそのままの処理を継続します。
デュプレックスシステムは2組のシステムを用意するのはデュアルシステムと同じです。このシステムでは主系が正常に動作している間、従系ではリアルタイム性の求められないバッチ処理などの作業を担当します。また主系が故障した場合には従系が主系の処理を代替するように切り替わる。
あらかじめ主系の処理を引き継ぐために必要なプログラムを起動しておくことで瞬時に切り替える待機方法である。
従系は出番が来るまで別の作業をしていたり電源がOFFだったりして、切り替え時に時間がかかります。なおその分コストダウンが可能です。
稼働率はトラブルに内部時に使えていた期間を割合として示すものである。この計算に用いる指標には平均故障間隔(MTBF) や平均修理時間(MTTR) などが信頼性などを表す指標として用いられます。
RASISはシステムの信頼性を評価する概念です。


**直列システムの稼働率 = 稼働率A × 稼働率B
並列システムの稼働率 = 1 - ((1-故障率A) × (1-故障率B))
フォールトトレラントは壊れても大丈夫なように対策を図る考え方です。
故障が発生した際に、安全性を確保する方向で壊れるように仕向ける方法です。 故障の場合は安全性が最優先とする考え方です。
故障が発生した場合にシステム全体を停止させるのではなく機能を一部停止するなどして動作の継続を図る方法です。 故障の場合は継続性が最優先とする考え方です。
意図しない使われ方をしても故障しないようにするという考え方です。
品質管理などを通してシステム構成要素の信頼性を高め、故障そのものの発生を防ぐ考え方です。
故障の発生頻度と時間の関係をグラフにしたものはバスタブ曲線と呼ばれます。
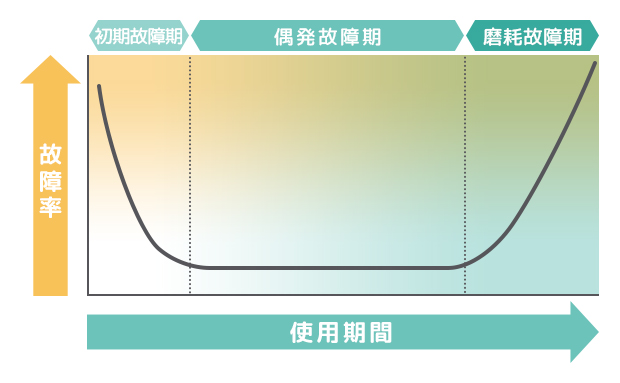
システムに必要となるすべてのコストはTCO(Total Cost of Ownership) と呼ばれます。 TCO=初期コスト+運用コスト
バックアップを行う際には以下のような点に注意します。
- 定期的にバックアップを行う
- バックアップを行う媒体を分ける
- 業務作業中にバックアップをしない
バックアップには3種類の方法があり、これらを組み合わせることで効率よくバックアップを行うことができます。
保存されているすべてのデータをバックアップするのがフルバックアップである。障害発生時に直前のバックアップだけで元の状態に戻せます。
前回のフルバックアップ以降に作成変更されたファイルだけをバックアップするのが差分バックアップである。障害発生時に直近のフルバックアップと差分バックアップを使い元の状態に戻します。
バックアップの種類の関係なく、前回のフルバックアップ以降に作成変更されたファイルだけをバックアップするのが増分バックアップである。障害発生時は元の状態に復元するために直近となるフルバックアップ以降のバックアップ全てが必要となる。