「データベース」とは、ある特定の条件に当てはまる「データ」を複数集めて、後で使いやすい形に整理した情報のかたまりのことを表します。 特にコンピュータ上で管理するデータをデータベースと呼ぶことが多いですが、紙の上で管理する「電話帳」や「住所録」なども、立派なデータベースです。 また、コンピュータ上でデータベースを管理するシステム(DBMS:Database Management System)のことや、そのシステム上で扱うデータ群のことを、単に「データベース」と呼ぶ場合もあります。 データベースを使ってデータを管理するメリットには、次のようなものが挙げられます。
- 複数のデータをまとめて管理できる
- 目的のデータを簡単に探すことができる
- 簡単に編集して使うことができる
コンピュータ上のデータベースとしてDBMSを使用する最大のメリットは、やはり「大量のデータを自動的に整理してくれる」という点です。 多くても数百件程度の個人の住所録ならば手動で管理することも可能ですが、法人で扱う数万件のデータをいちいち手で整理するには膨大な人手や時間が必要になります。 数万件のデータを一瞬にしてあいうえお順などにソートするなどのアシストをDBMSは担っています。
SQLとはデータベースを操作するための言語のことであり、DBMS上でデータの追加や削除、並べ替えなどを行うようコンピュータに命令するための手段です。 基本的に1行ずつ入力して確定し、直ちに実行されます。複数のSQLを組み合わせて大きな一つの塊のSQLとして実行することもできますが、通常のプログラミング言語のように一連の操作をまとめてセットすることのできる「ストアドプロシージャ」という機能のあるDBMSもあります。
DBMSにSQL文を1つのプログラムにまとめ保存しておくことはストアドプロシージャと呼ばれます。 一連の処理が実行される。 また、メリットは以下の通りです。
- ネットワークの負荷削減
- 処理速度の向上
リレーショナルデータベース(RDB)は表の形でデータを管理するデータベースです。
| 種類 | 説明 |
|---|---|
| 表(テーブル) | 複数のデータを収容する場所 |
| 行(レコード) | 1件分のデータを表す |
| 列(フィールド) | データを構成する項目を表す |
RDBの例
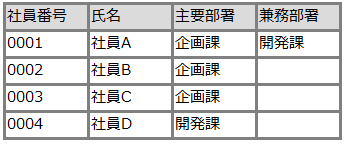
RDBMSは様々な会社が提供しており、以下のようなものがあります。
- Oracle DB(有料)
- SQL Server(有料)
- MYSQL(無料)
- PostgreSQL(無料)
- SQLite(無料)
テーブルをつくる時、どんなデータを入れるか構造を指定します。カラム型には以下のようなものがあります(My SQLの例)。
UNSIGNED を指定すると正の数しか格納できなくなります。(UNSIGNEDでデータ範囲:0~2n)
| 名称 | 型 | 概要 |
|---|---|---|
| TINYINT | 整数型 | -128 ~ 127 |
| SMALLINT | 整数型 | -32768 〜 32767 |
| MEDIUMINT | 整数型 | -8388608 〜 8388607 |
| INT、INTEGER | 整数型 | -2147483648 〜 2147483647 |
| BIGINT | 真数型 | -9223372036854775808 〜 9223372036854775807 |
| BOOL、BOOLEAN | Boolean型 | TINYINT(1) で指定した場合と同じ。true と false の2択を保存したいときに使うことが多い。 |
| BIT | BIT型 | 111 や 10000000 といったビットフィールド値を格納するのに使う。ビット値を指定するには、b'111' や b'10000000' のように指定する。 |
| DECIMAL、DEC、NUMERIC | 小数点型 | 誤差のない正確な小数を格納できる。 |
| FLOAT | 小数点型 | おおよそ小数第7位まで正確な小数を格納できる。 |
| DOUBLE | 小数点型 | おおよそ小数第15位まで正確な小数を格納できる。 |
| 型 | 用途 | フォーマット |
|---|---|---|
| DATE | 日付 | '年-月-日'(例: '2020-01-01') |
| DATETIME | 日付と時間 | '年-月-日 時:分:秒'(例: '2020-01-01 12:15:03') |
| TIMESTAMP | タイムスタンプ | '年-月-日 時:分:秒'(例: '2020-01-01 12:15:03')) |
| TIME | 時間 | '時:分:秒'(例: '12:15:03') |
| YEAR | 年 | 年(例: 2020) |
日付や時間を扱う型のカラムに値を挿入する場合、以下のような基本フォーマット以外の形も使えます。
- '2020-01-01 12:15:05' (基本)
- '20-1-1 12:15:5'
- '2020/01/01 12:15:05'
- '20200101121505'
文字列を扱う型は以下の種類があり、それぞれ用途が違います。
| 型 | 用途 |
|---|---|
| CHAR | 固定長文字列を格納。CHAR(10) のようにして格納できる文字数(0〜255・デフォルトは1)を指定できる。 |
| VARCHAR | 可変長文字列を格納。VARCHAR(10) のようにして格納できるバイト数(0〜65,535)を指定できる。 |
| BINARY | 固定長バイナリバイト文字列を格納。BINARY(10) のようにして格納できる文字数(0〜255・デフォルトは1)を指定できる。 |
| VARBINARY | 可変長バイナリバイト文字列を格納。VARBINARY(10) のようにして格納できるバイト数(0〜65,535)を指定できる。 |
| TINYBLOB | バイナリデータを格納。最大長は 255 (2^8 − 1) バイト。 |
| BLOB | バイナリデータを格納。最大長は 65,535 (216 − 1) バイト。BLOB(10) のようにして格納できるバイト数を指定できる。 |
| MEDIUMBLOB | バイナリデータを格納。最大長は 16,777,215 (2^24 − 1) バイト。 |
| LONGBLOB | バイナリデータを格納。最大長は 4,294,967,295 または 4G バイト (2^32 − 1) バイト。 |
| TEXT | 文字列を格納。最大長は 65,535 (216 − 1) 文字。TEXT(10) のようにして格納できる文字数を指定できる。 |
関係データベースにおいて蓄積データの重複や矛盾が発生しないように最適化するのが一般的です。 同じ内容を表のあちらこちらに書かないように表を分割するなどすることは正規化と呼ばれます。
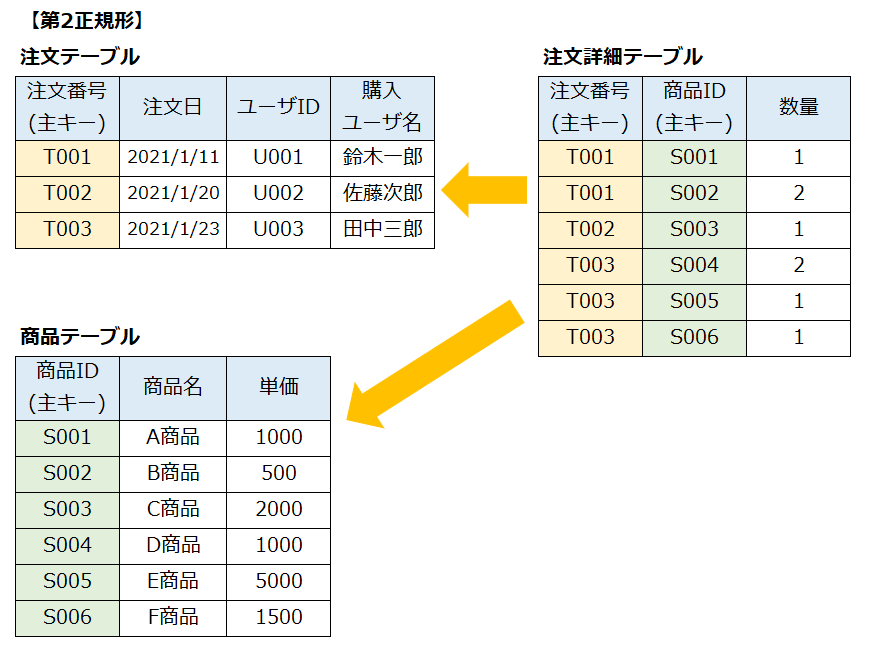
非正規形(正規化を行っていない元の形の表)を何回か正規化を行い最適化行います。
| 正規化 | 説明 |
|---|---|
| 非正規形 | 正規化されていない繰り返し部分を持つ表 |
| 第1正規形 | 繰り返し部分を分離させ独立したレコードを持つ表 |
| 第2正規形 | 部分関数従属しているところを切り出した表 |
| 第3正規形 | 主キー以外の列に関数従属している列を切り出した表 |
非正規型の表は繰り返し部分を持ち、関係データベースで扱えない表の形である。
非正規形の表から繰り返し部分を取り除いたものは第1正規形となる。 また表の形は2次元の表となる。
第1正規形の表から部分関数従属している列を分離した表が第2正規形の表である。
第2正規形の表から主キー以外の列に関数従属している列を分離した表が第3正規形の表である。
関係演算は表の中から特定の行や列を取り出したり、表と表をくっつけ新しい表を作り出したりする演算のことである。 選択、射影、結合などがある。
- 選択 ・・・ 行を取り出す演算
- 射影 ・・・ 列を取り出す演算
- 結合 ・・・ 表同士を結合する演算
このような演算を行い仮想的に作る一時的な表はビュー表と呼ばれる。
スキーマは「概念、要旨」という意味を持ち、データベース構造や使用の定義をするものである。 標準使用されているスキーマにはANSI/X3/SPARC規格は3層スキーマ構造をとり、外部スキーマ、概念スキーマ、内部スキーマという3層に定義を分けることでデータの独立性を高める。

データベースの表には行を識別できるようにキーとなる情報が含まれており、それは主キーと呼ばれます。また表同士を関連付けするときの主キーは外部キーと呼ばれます。 また複数列を組み合わせて主キーにしたものは複合キーと呼ばれます。
- 関数従属 ・・・ 主キーが決まったとき列が一意に定まる関係
- 部分関数従属 ・・・ 複合キーの一部の項目のみで列の値が一意に定まる関係
トランザクション管理と排他処理は複数人がデータベースにアクセスし同時変更などをした際にデータ内容に不整合が生じる問題からデータベースを守る処理です。
データベースにおいて、一連の処理をひとまとめにしたものはトランザクションと呼ばれます。 トランザクションが必要なケースは以下のようなものがあります。
- 手動でSQLを操作する場合
- 複数データの整合性を保つ場合
排他制御は処理中のデータをロックし、他の人が読み書きできないようにする機能である。 ロックする方法には共有ロックと専有ロックがある。
- 共有ロック ・・・ 各ユーザはデータを読むことはできるが、書き込みができない状態
- 専有ロック ・・・ 他ユーザはデータを読み書きすることができない
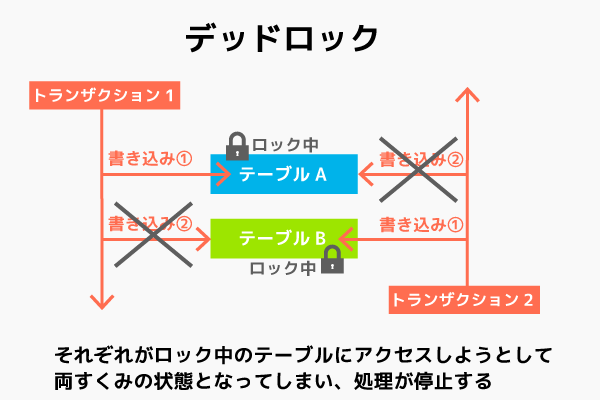
また、デットロックと呼ばれる現象がロック機能を使いすぎると起こる場合があります。
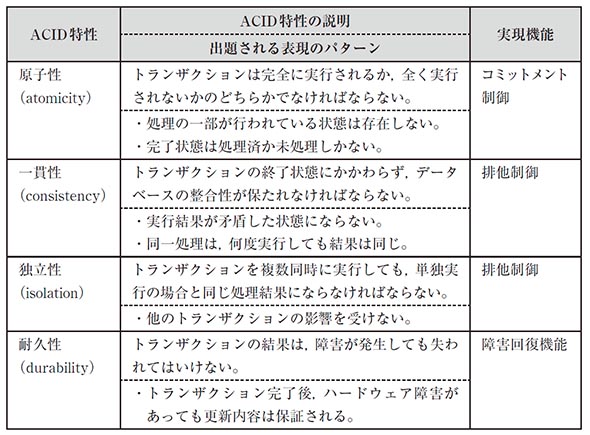
DBMSではトランザクション処理に対して4つの特性(ACID特性)が必要とされる。
データベースは定期的にバックアップを作ったり、更新前後の状態をジャーナルファイルに記録したりし障害の発生に備えます。 バックアップ後の更新はジャーナルと呼ばれるログファイルに更新前の状態と更新後の状態を逐一記録しデータベースの更新履歴を管理するようにする。 障害が発生した際にはこれらのファイルを用いてロールバックやロールフォワードなどの障害回復処理を行い、元の状態に復旧する。
データベースでは更新処理をトランザクション単位で管理します。 トランザクションは一連の処理が問題なく完了できたときに、最後にその更新を確定することでデータベースへ更新内容を反映させる。これはコミットと呼ばれる。 また、トランザクション処理中に障害が発生し更新に失敗した場合、データベース更新前の状態を更新前ジャーナルから取得し、データベースをトランザクション処理直前の状態に戻します。この処理はロールバックと呼ばれます。
物理的に分かれている複数のデータベースを見かけ上1つのデータベースとして扱えるようにしたシステムは分散データベースシステムと呼ばれます。 これはトランザクション処理が各サイトにわたり行われるので、全体の同期をとりコミット、ロールバックを取らないと、データの整合性が取れなくなる恐れがある。そのため全サイトに問い合わせを行い、その結果を見てコミット、ロールバックを行う。この処理は2相コミットと呼ばれる。
データベース自体が突然障害に見舞われた場合、バックアップ以降の更新ジャーナルから更新情報を取得し、データベースを障害発生直前の状態に復旧させる一連の処理があります。この処理はロールフォワードと呼ばれます。

