![]()
Heat is a flexible and seamless open-source software for high performance data analytics and machine learning. It provides highly optimized algorithms and data structures for tensor computations using CPUs, GPUs and distributed cluster systems on top of MPI. The goal of Heat is to fill the gap between data analytics and machine learning libraries with a strong focus on single-node performance, and traditional high-performance computing (HPC) focusing on inter-node communication, e.g. through MPI.
The goal of the project is to automatize benchmarks/scaling tests for faster detection of performance degradation, and make the results easily accessible on the project’s GitHub repository.
The work of this project is to build a pipeline to run benchmarks continuously on every branch-to-master merge. Results then can be visualized as graphs in the Ginkgo Performance Explorer.
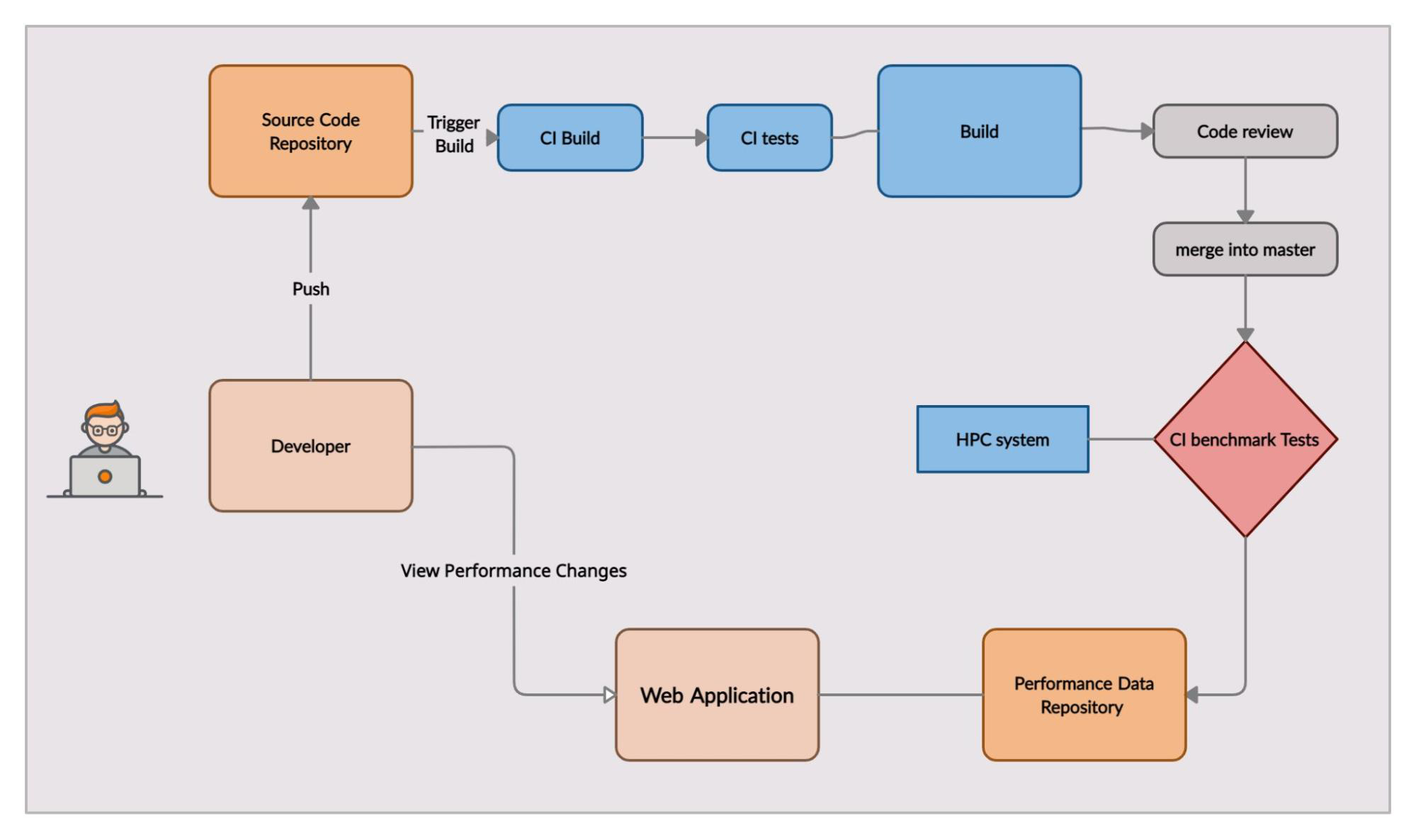
We implemented everything on a forked Repo of HeAT. Everything we implemented during the GSoC period can be found in this Git diff
This project is based on the three related pillars to performance measurement. The first is that a given benchmark can be represented in a function call. This function call can then be tested against various forms of datasets as parameters using a mature python testing library called pytest. Work geared to developing an extensible pipeline which can accommodate addition of benchmarks includes:
- Python script to collect benchmarks in the Pytest-benchmarks-directory
- Shell script to test and collect benchmarking statistics.
- Methodology to publish results into a repository for collecting data.
- JSON data parser to represent the visualization of the data in Ginkgo Performance explorer.
The benchmarking-test workflow calls the script pytest-benchmarks/run_benchmarks.sh to build and run the pytest enclosed benchmarks in the directory. Then the script aggregate.py is called, which is responsible for parsing and publishing the generated results.
After the successful completion of the CI, generated results can be found in the public repository Heat-data
To visualize the data go to Ginkgo Performance Explorer
https://ginkgo-project.github.io/gpe/Copy URL to data repository and put in section one of explorer and select benchmark file
https://raw.githubusercontent.com/tewodros18/heat-data/main/data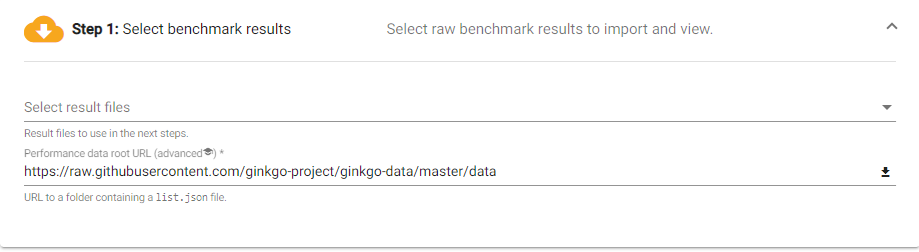
Copy URL to plot repository and put in section two of explorer
https://raw.githubusercontent.com/tewodros18/heat-data/main/plots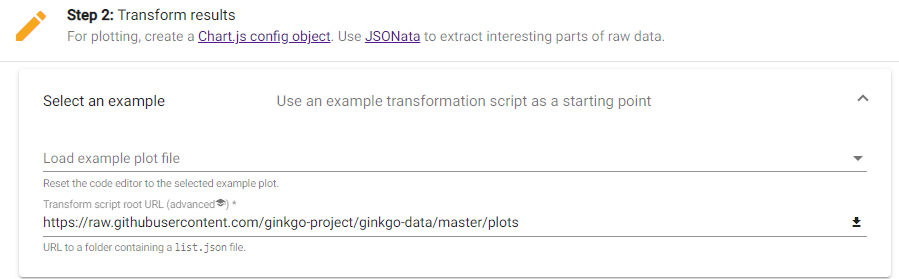
- Address potential security issues that arise with self-hosted runners
- Include more pytest benchmarks that will stress test HeAT library
I got an opportunity to learn so many things and participate in my first open source development and meet amazing people in the open-source community. It wouldn't have been possible without the constant support and guidance of my mentors Björn Hagemeier and Juan Pedro Gutiérrez Hermosillo Muriedas