Last active
December 4, 2021 01:54
Partial Correlation significance using kfolds
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #notebook: | |
| #https://github.com/thistleknot/python-ml/blob/master/code/pcorr-significance.ipynb | |
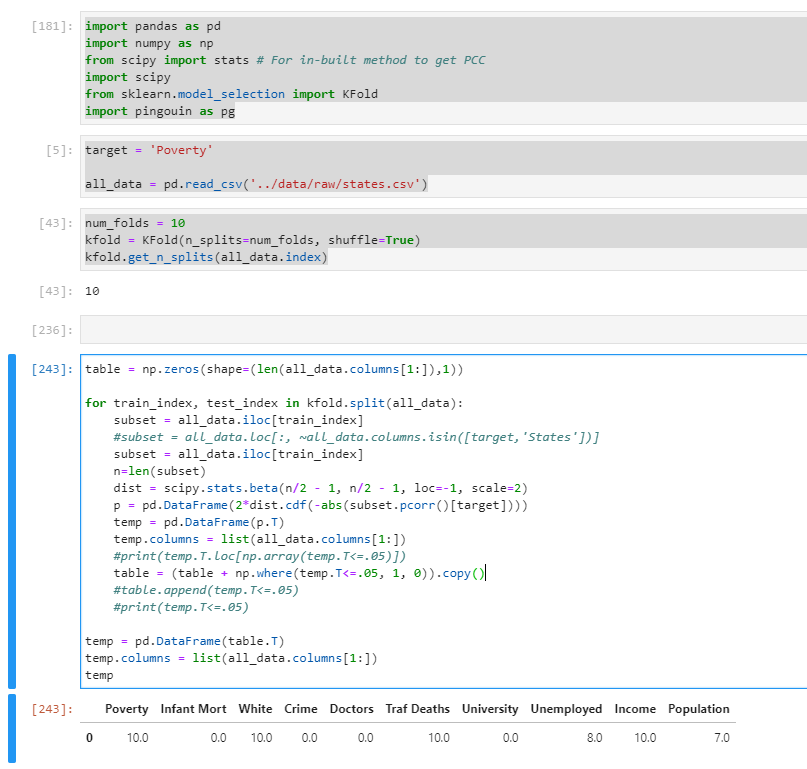
| import pandas as pd | |
| import numpy as np | |
| from scipy import stats # For in-built method to get PCC | |
| import scipy | |
| from sklearn.model_selection import KFold | |
| import pingouin as pg | |
| from sklearn.preprocessing import StandardScaler | |
| scaler = StandardScaler() | |
| from zca import zca | |
| import seaborn as sns | |
| import sklearn.linear_model | |
| import statsmodels.api as sm | |
| from statsmodels.stats.outliers_influence import OLSInfluence | |
| import statsmodels.tools | |
| import matplotlib.pyplot as plt | |
| zca = zca.ZCA() | |
| target = 'Poverty' | |
| all_data = pd.read_csv('../data/raw/states.csv') | |
| scaler.fit(np.array(all_data[target]).reshape(-1, 1)) | |
| num_folds = 10 | |
| kfold = KFold(n_splits=num_folds, shuffle=True) | |
| kfold.get_n_splits(all_data.index) | |
| exclude = 'States' | |
| sig_table = np.zeros(shape=(len(all_data.columns))) | |
| signs_table = np.zeros(shape=(len(all_data.columns))) | |
| p_threshold = .05 | |
| New_Names = all_data.columns[2:] | |
| iteration = 0 | |
| for train_index, test_index in kfold.split(all_data): | |
| #print(iteration) | |
| max_pvalue = 1 | |
| subset = all_data.iloc[train_index].loc[:, ~all_data.columns.isin([exclude])] | |
| #skip y and states | |
| set_ = subset.loc[:, ~subset.columns.isin([target])].columns.tolist() | |
| n=len(subset) | |
| while(max_pvalue>=.05): | |
| dist = scipy.stats.beta(n/2 - 1, n/2 - 1, loc=-1, scale=2) | |
| p_values = pd.DataFrame(2*dist.cdf(-abs(subset.pcorr()[target]))).T | |
| p_values.columns = list(subset.columns) | |
| max_pname = p_values.idxmax(axis=1)[0] | |
| max_pvalue = p_values[max_pname].values[0] | |
| if (max_pvalue > .05): | |
| set_.remove(max_pname) | |
| temp = [target] | |
| temp.extend(set_) | |
| subset = subset[temp] | |
| winners = p_values.loc[:, ~p_values.columns.isin([target])].columns.tolist() | |
| sig_table = (sig_table + np.where(all_data.columns.isin(winners),1,0)).copy() | |
| signs_table[all_data.columns.get_indexer(winners)]+=np.where(subset.pcorr()[target][winners]<0,-1,1) | |
| significance = pd.DataFrame(sig_table).T | |
| significance.columns = list(all_data.columns) | |
| display(significance) | |
| sign = pd.DataFrame(signs_table).T | |
| sign.columns = list(all_data.columns) | |
| display(sign) | |
| purity = abs((sign/num_folds)*(sign/significance)).T.replace([np.inf, -np.inf, np.NaN], 0) | |
| display(purity.T) | |
| threshold = .5 | |
| chosen = list(purity.T.columns.values[np.array(purity.T>=threshold).reshape(len(all_data.columns,))]) | |
| dataSet = pd.concat([all_data[target],all_data[chosen]],axis=1) | |
| y_scaled = pd.DataFrame(scaler.transform(np.array(dataSet[target]).reshape(-1, 1))) | |
| y_scaled.columns=[target] | |
| display(chosen) | |
| zca_data = pd.concat([y_scaled,pd.DataFrame(zca.fit_transform(dataSet[chosen]),columns=chosen)],axis=1) | |
| zca_data.pcorr() | |
| sns.pairplot(zca_data) | |
| #model = sklearn.linear_model.LinearRegression() | |
| data_set_wConstant = statsmodels.tools.tools.add_constant(zca_data) | |
| y = data_set_wConstant[target] | |
| X = data_set_wConstant[data_set_wConstant.columns.drop(target)] | |
| #results = model.fit(X, y) | |
| model = sm.OLS(y,X) | |
| results = model.fit() | |
| results.summary() | |
| pd.DataFrame(results.get_influence().resid_studentized_internal).hist() | |
| plt.scatter(results.fittedvalues*scaler.scale_[0] + scaler.mean_[0], y*scaler.scale_[0] + scaler.mean_[0]) |
v2

v2 continued
https://imgur.com/a/OwhTZ6U
R
newDF_t <- na.omit(newDF[1:nrow(training),])
newDF_h <- na.omit(newDF[(nrow(training)+1):nrow(combo_),])
cor(na.omit(newDF[,1:2,]))
sig_table = matrix(0, ncol=ncol(newDF_t))
colnames(sig_table) <- colnames(newDF_t)
signs_table = matrix(0, ncol=ncol(newDF_t))
colnames(signs_table) <- colnames(newDF_t)
p_threshold = .33
New_Names = colnames(newDF_t)[2:length(colnames(newDF_t))]
iteration=0
dat <- 1:10
n=length(dat)
lapply(folds,length)
folds<-createTimeSlices(y=rownames(newDF_t),initialWindow = 20,horizon = 10)
exclude <- c()
#crit <- critical.r(nrow(set_), .05)
for (k in 1:length(folds$train))
{#k=1
max_pvalue = 1
subset = newDF_t[(folds$train[k][[1]]),c(colnames(newDF_t) %notin% c(exclude))]
set_ = subset[,c(colnames(newDF_t) %notin% c(var_of_int))]
while(max_pvalue>=p_threshold)
{
p_values <- pcor(subset, method = c("spearman"))$p.value[,var_of_int,drop=FALSE]
max_pname = rownames(p_values)[which.max(p_values)]
max_pvalue = p_values[max_pname,]
if (max_pvalue >= p_threshold)
{
print(max_pvalue)
print(max_pname)
subset <- dplyr::select(subset,-c(max_pname))
}
}
winners = rownames(p_values)[rownames(p_values) %notin% c(var_of_int)]
sig_table = sig_table + as.integer(colnames(newDF_t) %in% winners)
t_ <- t(pcor(subset[,c(var_of_int,winners)], method = c("spearman"))$estimate[,var_of_int,drop=FALSE])[,-1]
rownames(t_) <- rownames(signs_table)
temp_ <- merge(t(signs_table), t_, by=0,all.x=TRUE)
rownames(temp_) <- temp_$Row.names
signs_table_ = rowSums(temp_[,2:3],na.rm=TRUE)
signs_table_ = ifelse(signs_table_==0,0,ifelse(signs_table_<0,-1,1))
signs_table = signs_table_ + signs_table
}
keepers = colnames(sig_table)[sig_table>=(length(folds$train)/2)]
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
v1