- https://github.com/varmaprr/Confluent-Kafka-Certification
- https://github.com/afonsir/apacha-kafka-ccdak
- https://www.confluent.io/wp-content/uploads/confluent-kafka-definitive-guide-complete.pdf
- https://kafka.apache.org/documentation/
- https://docs.confluent.io/platform/current/platform.html
- Developer questions
- Administrator questions
Last active
October 9, 2023 17:28
-
-
Save tuannvm/35e86681f760f9abaef56b9e0ff7eaf4 to your computer and use it in GitHub Desktop.
#CCDAK #kafka #certification
Kafka Streams is a client library for building streaming applications and microservices, where the input and output data are stored in Kafka clusters. Kafka's cluster architecture makes Kafka Streams fault-tolerant, highly-scalable, and especially elastic solution. Kafka Streams utilizes exactly-once processing (Kafka topic -> Kafka topic) semantics, connects directly to Kafka, and does not require any separate processing cluster.
The requirements for data co-partitioning are:
-
The input topics of the join (left side and right side) must have the same number of partitions.
-
All applications that write to the input topics must have the same partitioning strategy so that records with the same key are delivered to same partition number.
Kafka Streams supports at-least-once and exactly-once processing guarantees
In order to speed up recovery, it is advised to store the Kafka Streams state on a persistent volume, so that only the missing part of the state needs to be recovered.
-
A stream provides immutable data. It supports only inserting (appending) new events, whereas existing events cannot be changed. Streams are persistent, durable, and fault tolerant. Events in a stream can be keyed, and you can have many events for one key.
-
A table provides mutable data. New events - rows - can be inserted, and existing rows can be updated and deleted. Here, an event's key aka row key identifies which row is being mutated. Like streams, tables are persistent, durable, and fault tolerant.
https://docs.confluent.io/platform/current/streams/developer-guide/dsl-api.html#transform-a-stream
-
Aggregate: Aggregates the values of records by the grouped key.
-
Count: Counts the number of records by the grouped key.
-
Reduce: Combines the values of records by the grouped key.
-
Streams and Tables can also be joined. All
joinsare stateful.
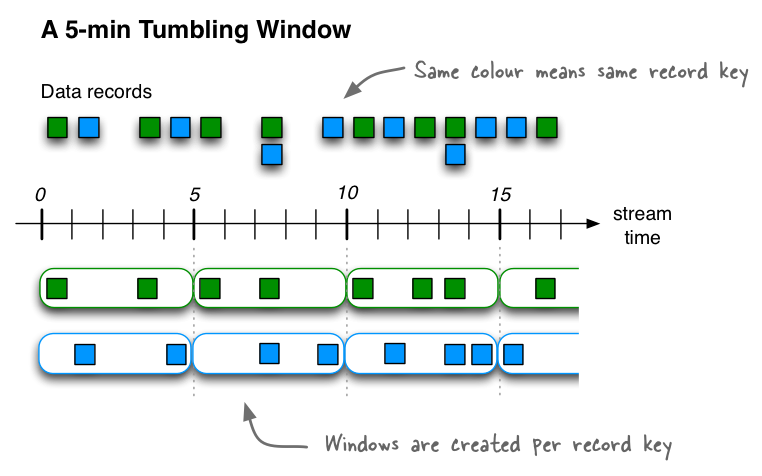
- Tumbling time windows - Fixed-size, non-overlapping, gap-less windows
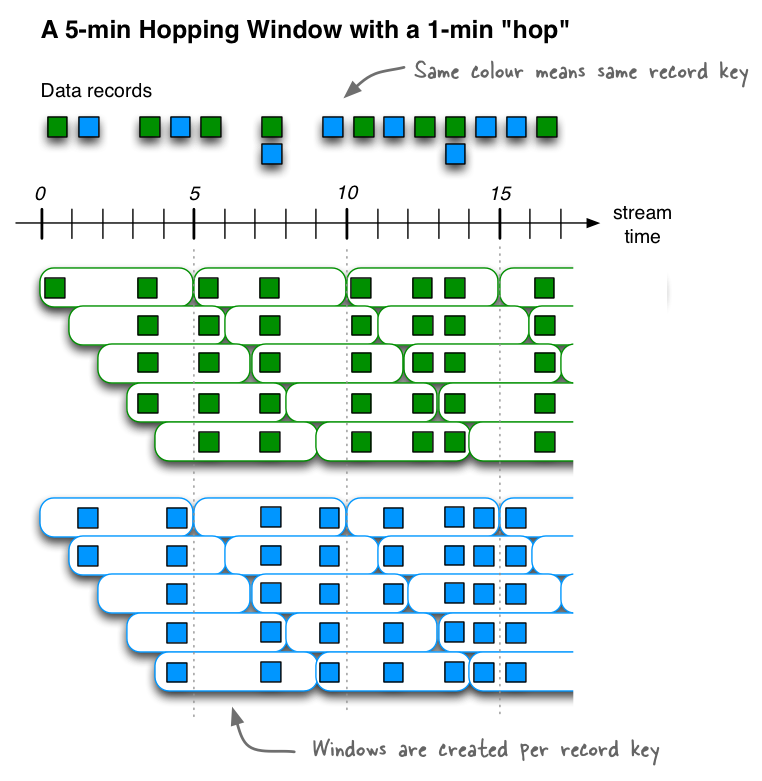
- Hopping time windows - Fixed-size, overlapping windows
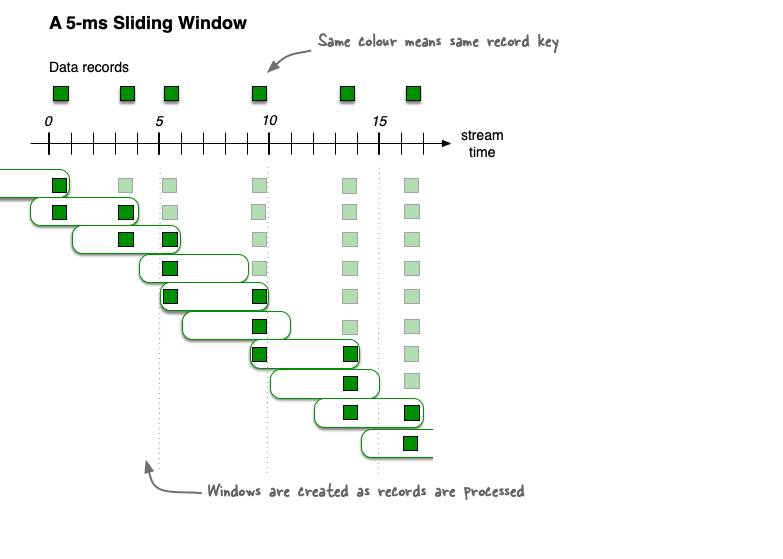
- Sliding time windows - Fixed-size, overlapping windows that work on differences between record timestamps
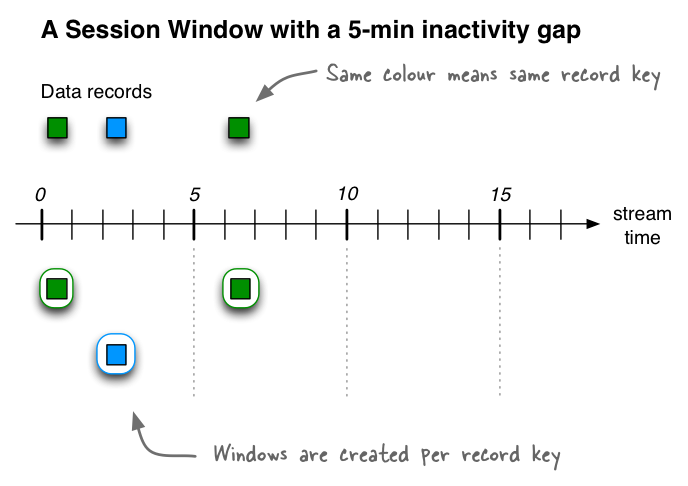
- Session Windows - Dynamically-sized, non-overlapping, data-driven windows
Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems.
Confluent Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving your Avro, JSON Schema, and Protobuf schemas. There is an implicit "contract" that producers write data with a schema that can be read by consumers, even as producers and consumers evolve their schemas. Schema Registry helps ensure that this contract is met with compatibility checks.
A producer can register schemas to the Schema Registry and a consumer can fetch a schema from the Schema Registry if not available in the local cache.
BACKWARD schema evolution. Can have a new version of the schema as reader and an old version as writer.
- Add optional fields
- Delete fields
FORWARD schema evolution. Can have a new version of the schema as writer and an old version of the schema as reader.
- Add fields
- Delete optional fields
FULL schema evolution. Old data can be read with the new schema, and new data can also be read with the last schema.
- Add optional fields
- Delete optional fields
NotLeaderForPartitionException --> send metadata request to the same broker to get leader infos and then connect to leader
Kafka producers are thread safe, which means one Kafka producer can be safely used in multiple threads.
Three mandatory properties:
-
bootstrap.servers
-
key.serializer
-
value.serializer
-
Sending Approach
- Fire-and-forget
We send a message to the server and don't really care if it arrives successfully or not. Most of the time, it will arrive successfully, since Kafka is highly available and the producer will retry sending messages automatically. However, some messages will get lost using this method.
- Synchronous send
We send a message, the send() method returns a Future object, and we use get() to wait on the future and see if the send() was successful or not. Here, we are using Future.get() to wait for a reply from Kafka. This method will throw an exception if the record is not sent successfully to Kafka. If there were no errors, we will get a RecordMetadata object that we can use to retrieve the offset the message was written to.
- Asynchronous send
We call the send() method with a callback function, which gets triggered when it receives a response from the Kafka broker.
If a Kafka producer produces messages faster than the broker can take, the records will be buffered in memory.
If the buffer is full, then the .send() method will start to block and won't return right away.
The configuration max.block.ms is the time the .send() method will block before throwing an exception. If an exception is thrown this usually means the brokers are down and cannot process any data.
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;The mapping of keys to partitions is consistent only as long as the number of partitions in a topic does not change.
The send() method returns a Future object with RecordMetadata.
-
InvalidTopicException
-
OffsetMetadataTooLargeException
-
RecordBatchTooLargeException
-
RecordTooLargeException
-
UnknownServerException
-
CorruptRecordException
-
InvalidMetadataException
-
NotEnoughReplicasAfterAppendException
-
NotEnoughReplicasException
-
OffsetOutOfRangeException
-
TimeoutException
-
UnknownTopicOrPartitionException
acks=0: If set to zero then the producer will not wait for any acknowledgment from the server at all. No guarantee can be made that the server has received the record in this case (possible data loss).
acks=1: This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost (limited data loss).
acks=all: This means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting (no data loss).
The simplest and most reliable of the commit APIs is commitSync(), but this will block the application until the broker responds to the commit request.
Another option is the asynchronous commit API commitAsync(), which will not block the application and not limit the throughput of the application.
Kafka consumer is not thread safe. Multi-threaded access must be properly synchronized, which can be tricky. This is why the single-threaded model is commonly used.
The only exception to this rule is wakeup(), which can safely be used from an external thread to interrupt an active operation. In this case, a WakeupException will be thrown from the thread blocking on the operation
When a consumer wants to join a group, it sends a JoinGroup request to the group coordinator (one of the brokers).
The first consumer to join the group becomes the group leader (one of the consumers in the consumer group).
The leader receives a list of all consumers in the group from the group coordinator (this will include all consumers that sent a heartbeat recently and which are therefore considered alive) and is responsible for assigning a subset of partitions to each consumer.
It uses an implementation of PartitionAssignor to decide which partitions should be handled by which consumer.
If the committed offset is smaller than the offset of the last message the client processed, the messages between the last processed offset and the committed offset will be processed twice.
If the committed offset is larger than the offset of the last message the client actually processed, all messages between the last processed offset and the committed offset will be missed by the consumer group.
For authorization it's a best practice to create one principal per application and give each principal only the ACLs it requires and no more.
If set to true, a Kafka broker automatically creates a topic under the following circumstances:
-
When a producer starts writing messages to the topic.
-
When a consumer starts reading messages from the topic.
-
When any client requests metadata for the topic.
If the replication factor is X, X-1 brokers can be down without impacting the topic availability.
The consumer configuration auto.offset.reset tells the consumer what to do when there is no initial offset in Kafka or if the current offset does not exist any more on the server
Kafka guarantees every partition replica resides on a different broker
If more than one similar config is specified, the smaller unit size will take precedence.
The broker property unclean.leader.election.enable allows you to specify a preference of availability or durability.
If availability is more important than avoiding data loss, ensure that this property is set to true. If preventing data loss is more important than availability, set this property to false.
Consumer Offsets and Schema Registry Schemas are not stored within Zookeeper. Consumer offsets are stored in a Kafka topic __consumer_offsets, and the Schema Registry schemas are stored in the _schemas topic.
The main idea behind Log Compaction is to selectively remove records where there are most recent updates with the same primary key.
Log compaction strategy ensures that Kafka will always retain at least the last known value for each message key within the log for a single topic partition.
A record with the same key from the record we want to delete is produced to the same topic and partition with a null payload. These records are called tombstones.
The retention.ms configuration controls the maximum time in milliseconds we will retain a log before we will discard old log segments to free up space if we are using the "delete" retention policy
ksqlDB currently supports the following formats:
-
DELIMITED (e. g. comma-separated value)
-
JSON
-
Avro message values are supported. Avro keys are not yet supported. This requires Schema Registry and
ksql.schema.registry.urlin the ksqlDB server configuration file. -
KAFKA (for example, a BIGINT that's serialized using Kafka's standard LongSerializer).
The maximum ksqlDB parallelism depends on the number of topic partitions.
- Headless: The simplest deployment mode for ksqlDB is the headless mode, also called application mode. In the headless mode, you write all of your queries in a SQL file, and then start ksqlDB server instances with this file as an argument. Each server instance will read the given SQL file, compile the ksqlDB statements into Kafka Streams applications and start execution of the generated applications.
Headless ksqlDB is recommended for production deployments.
- Interactive: The other option for running ksqlDB is interactive mode, in which you interact with the ksqlDB servers through a REST API either directly via your favorite REST clients, through ksqlDB CLI or through Confluent Control Center.
When using the Kafka CLI, you can use any bin/kafka-*.sh script with the --version parameter to display the Kafka version.
To produce messages with key-value delimiters, you need to set two properties, parse.key and key.separator. Both properties can be set with the --properties option
- kafka-topics.sh
--topics-with-overrides: If set when describing topics, only show topics that have overridden configs.
--unavailable-partitions: If set when describing topics, only show partitions whose leader is not available.
--under-min-isr-partitions: If set when describing topics, only show partitions whose ISR count is less than the configured minimum.
--under-replicated-partitions: If set when describing topics, only show under replicated partitions.
ZooKeeper is primarily used to track the status of nodes in the Kafka cluster and maintain a list of Kafka topics and messages.
-
Broker registration with heartbeat mechanisms.
-
Performing leader elections in case some brokers go down.
-
Storing the Kafka cluster id.
-
Storing ACLs (Access Control Lists).
-
Sending information to Kafka in case of changes like new topics, broker dies, topic deletion etc.
Configuration:
-
clientPort: The port to listen for client connections; that is, the port that clients attempt to connect to.
-
dataDir: The location where ZooKeeper will store the in-memory database snapshots and, unless specified otherwise, the transaction log of updates to the database.
-
tickTime: The length of a single tick, which is the basic time unit used by ZooKeeper, as measured in milliseconds. It is used to regulate heartbeats, and timeouts.
- tickTime: The length of a single tick, which is the basic time unit used by ZooKeeper, as measured in milliseconds. It is used to regulate heartbeats, and timeouts.
- initLimit: Amount of time, in ticks, to allow followers to connect and sync to a leader.
- syncLimit: Amount of time, in ticks, to allow followers to sync with ZooKeeper. If followers fall too far behind a leader, they will be dropped.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
The syncLimit value limits how long out-of-sync followers can be with the leader. Both values are a number of tickTime units, which makes the init Limit 20 × 2,000 ms, or 40 seconds
The current best practice is to use the newer --bootstrap-server option and connect directly to the Kafka broker
/pathAn optional ZooKeeper path to use as a chroot environment for the Kafka cluster. If it is omitted, the root path is used.
Note that the broker will place a new partition in the path that has the least number of partitions currently stored in it, not the least amount of disk space used, so an even distribution of data across multiple directories is not guaranteed.