-
-
Save turicas/3e3621d61415e3453cd03a1997f7473f to your computer and use it in GitHub Desktop.
| import csv | |
| import gzip | |
| import io | |
| import json | |
| from urllib.parse import urlencode, urljoin | |
| from urllib.request import Request, urlopen | |
| class BrasilIO: | |
| base_url = "https://api.brasil.io/v1/" | |
| def __init__(self, auth_token): | |
| self.__auth_token = auth_token | |
| @property | |
| def headers(self): | |
| return { | |
| "User-Agent": "python-urllib/brasilio-client-0.1.0", | |
| } | |
| @property | |
| def api_headers(self): | |
| data = self.headers | |
| data.update({"Authorization": f"Token {self.__auth_token}"}) | |
| return data | |
| def api_request(self, path, query_string=None): | |
| url = urljoin(self.base_url, path) | |
| if query_string: | |
| url += "?" + urlencode(query_string) | |
| request = Request(url, headers=self.api_headers) | |
| response = urlopen(request) | |
| return json.load(response) | |
| def data(self, dataset_slug, table_name, filters=None): | |
| url = f"dataset/{dataset_slug}/{table_name}/data/" | |
| filters = filters or {} | |
| filters["page"] = 1 | |
| finished = False | |
| while not finished: | |
| response = self.request(url, filters) | |
| next_page = response.get("next", None) | |
| for row in response["results"]: | |
| yield row | |
| filters = {} | |
| url = next_page | |
| finished = next_page is None | |
| def download(self, dataset, table_name): | |
| url = f"https://data.brasil.io/dataset/{dataset}/{table_name}.csv.gz" | |
| request = Request(url, headers=self.headers) | |
| response = urlopen(request) | |
| return response | |
| if __name__ == "__main__": | |
| api = BrasilIO("meu-api-token") | |
| dataset_slug = "covid19" | |
| table_name = "caso_full" | |
| # Para baixar o arquivo completo: | |
| # Após fazer o download, você salvá-lo no disco ou percorrer o arquivo em | |
| # memória. Para salvá-lo no disco: | |
| response = api.download(dataset_slug, table_name) | |
| with open(f"{dataset_slug}_{table_name}.csv.gz", mode="wb") as fobj: | |
| fobj.write(response.read()) | |
| # TODO: o código acima pode ser melhorado de forma a não utilizar | |
| # `response.read()` para não colocar todo oarquivo em memória e sim fazer | |
| # streaming da resposta HTTP e salvar cada chunk diretamente no `fobj`. | |
| # Caso queira percorrer o CSV em memória: | |
| response = api.download(dataset_slug, table_name) | |
| fobj = io.TextIOWrapper(gzip.GzipFile(fileobj=response), encoding="utf-8") | |
| reader = csv.DictReader(fobj) | |
| for row in reader: | |
| pass # faça algo com `row` | |
| # Para navegar pela API: | |
| filters = {"state": "PR", "is_last": True} | |
| data = api.data(dataset_slug, table_name, filters) | |
| for row in data: | |
| pass # faça algo com `row` |
Estou usando a biblioteca Papa Parse no JavaScript para baixar os dataset com filtros em formato CSV e depois fazer a leitura dos dados. Estava funcionando perfeitamente até a implementação da autenticação com o token ser adicionada também ao download dos arquivos. Fiz vários testes tentando passar o token no cabeçalho, me inspirando nas orientações que constam na documentação da biblioteca, aqui. Meu código ficou assim, mas ainda não consigo autenticar corretamente e receber o arquivo como eu recebia antes:
function loadInfoEstados() { Papa.parse("https://brasil.io/dataset/covid19/caso_full/?place_type=city&is_last=True&is_repeated=False&format=csv", { header: true, download: true, dynamicTyping: true, downloadRequestHeaders: { 'Authorization': 'token 0123345678901234567890', }, complete: function(results) { var estrutura = results.data; estadosJSON(estrutura); id = "estado"; } }); }Alguém passou por uma situação parecida e conseguiu resolver?
- O endereço correto é https://api.brasil.io/v1/dataset/covid19/caso_full/data/ (você pode acessar do navegador para checar, se estiver autenticado no site)
- Não lembro se faz diferença, mas
tokené com T maiúsculo.
@turicas a função data não estava funcionando pois request não é definido. Fiz uma adaptação no código para:
(1) Utilizar nesse caso a função api_request e,
(2) Resolver a autenticação do usuário em headers (mudei o nome aqui, antes era api_headers) - adicionei uma condicional para o caso de requisição na API, e adicionei o parâmetro user_agent para autenticação:
Agora a função funcionou aqui! :D
import csv
import gzip
import io
import json
from urllib.parse import urlencode, urljoin
from urllib.request import Request, urlopen
class BrasilIO:
base_url = "https://api.brasil.io/v1/"
def __init__(self, user_agent=None, auth_token=None):
"""
Caso queria fazer uma requisição na API, passe os parâmetros user_agent e auth_token.
Para fazer somente o download do arquivo completo, não é necessário passar nenhum parâmetro.
"""
self.__user_agent = user_agent
self.__auth_token = auth_token
def headers(self, api=True):
if api:
return {
"User-Agent": f"{self.__user_agent}",
"Authorization": f"Token {self.__auth_token}"
}
else:
return {
"User-Agent": "python-urllib/brasilio-client-0.1.0",
}
def api_request(self, path, query_string=None):
url = urljoin(self.base_url, path)
if query_string:
url += "?" + query_string
request = Request(url, headers=self.headers(api=True))
response = urlopen(request)
return json.load(response)
def data(self, dataset_slug, table_name, filters=None):
url = f"dataset/{dataset_slug}/{table_name}/data/"
filters = filters or {}
filters["page"] = 1
finished = False
while not finished:
query_string = "&".join([f"{k}={v}" for k, v in filters.items()])
response = self.api_request(url, query_string)
next_page = response.get("next", None)
for row in response["results"]:
yield row
filters = {}
url = next_page
finished = next_page is None
def download(self, dataset, table_name):
url = f"https://data.brasil.io/dataset/{dataset}/{table_name}.csv.gz"
request = Request(url, headers=self.headers(api=False))
response = urlopen(request)
return response
if __name__ == "__main__":
# Caso não tenha, cadastre-se no Brasil.io e gere seu Token
# Para mais instruções: https://blog.brasil.io/2020/10/10/como-acessar-os-dados-do-brasil-io/
user_agent = "seu-usuario"
auth_token = "seu-token"
api = BrasilIO(user_agent, auth_token)
dataset_slug = "covid19"
table_name = "caso_full"
# Para baixar o arquivo completo:
# Após fazer o download, você salvá-lo no disco ou percorrer o arquivo em
# memória. Para salvá-lo no disco:
response = api.download(dataset_slug, table_name)
with open(f"{dataset_slug}_{table_name}.csv.gz", mode="wb") as fobj:
fobj.write(response.read())
# TODO: o código acima pode ser melhorado de forma a não utilizar
# `response.read()` para não colocar todo oarquivo em memória e sim fazer
# streaming da resposta HTTP e salvar cada chunk diretamente no `fobj`.
# Caso queira percorrer o CSV em memória:
response = api.download(dataset_slug, table_name)
fobj = io.TextIOWrapper(gzip.GzipFile(fileobj=response), encoding="utf-8")
reader = csv.DictReader(fobj)
for row in reader:
pass # faça algo com `row`
# Para navegar pela API:
filters = {"state": "PR", "is_last": True}
data = api.data(dataset_slug, table_name, filters)
for row in data:
print(row) # faça algo com `row`boa @fernandascovino! Eu tive o mesmo problema, levei um tempo para resolver e voltei aqui para compartilhar a solução também :) 👍
Pessoal, eu não sou fluente em Python, mas faço meus "frankensteins". Eu não estou entendendo como passar os filtros e colocar tudo em um pandas dataframe.
Antigamente eu fazia:
url = "https://brasil.io/api/dataset/covid19/caso/data?state=AM&page_size=10000"
r = requests.get(url)
data = r.json()
df = json_normalize(data['results'])e pronto, estava em um dataframe. Como eu reproduzo esse filtro (state=AM&page_size=10000) e coloco isso em um dataframe? Fiz várias tentativas fracassadas... Se alguém puder ajudar, agradeço muito!
PS.: os estado do AM tem duas páginas, então seria bom colocar os resultados das duas no mesmo dataframe.
@turicas, Algo interessante seria disponibilizar o arquivo RData com os dados completos. Por exemplo, atualmente o arquivo disponível em https://data.brasil.io/dataset/covid19/caso_full.csv.gz com 160 MB poderia ser reduzido para 5,1 MB. É importante destacar que essa compressão é muito rápida, muito fácil de implementar e a leitura do arquivo reduzido em R ou em Python também é muito rápida. A redução do tamanho do arquivo é mais de 31,37 vezes, aproximadamente.
Uma vez que foi declarado da grande possibilidade de bloqueios de IPs ou mesmo da não disponibilização da API diante dos excessos ("abusos"), penso que disponibilizar também os dados no formato RData seria algo muito útil e importante (pequeno para baixar e rápido para ler).

Em R, você poderá realizar a compressão com o código abaixo:
library(vroom)
library(fs)
download_save <- function(path = "~/Downloads") {
covid19_brasil_io <-
vroom("https://data.brasil.io/dataset/covid19/caso.csv.gz")
save(
file = fs::path(
path,
"covid19_brasil_io",
ext = "RData"
),
covid19_brasil_io,
compress = "xz"
)
}Em Python existem formas de ler arquivos RData:
import pyreadr
result = pyreadr.read_r('/path/to/file.RData') # also works for RdsAcredito que isso seria útil, uma vez que a rede de quem estiver usando uma aplicação pode não ser de alta velocidade. Baixar um arquivo menor é algo que poderia ajudar. Além disso, a leitura do arquivo compactado é muito rápida, para o estado atual do arquivo, dura um pouco mais de 1 segundo em minha máquina:
Mensurando o tempo de leitura de um arquivo RData:
> system.time(load(file = "/home/prdm0/Downloads/covid19_brasil_io.RData"))
usuário sistema decorrido
1.162 0.000 1.163 Mensurando melhor a leitura do arquivo RData - Benchmark:
O gráfico abaixo é um Violin Plot obtido em 100 execuções de leitura do arquivo RData com todos os dados da Covid-19 do projeto Brasil.IO, dados estes disponíveis em https://data.brasil.io/dataset/covid19/caso_full.csv.gz. Note que o tempo máximo de leitura foi de aproximadamente 2,4 segundos e o tempo mínimo um pouco acima de 1,6 segundos, com média de leitura em 2,03 segundos.
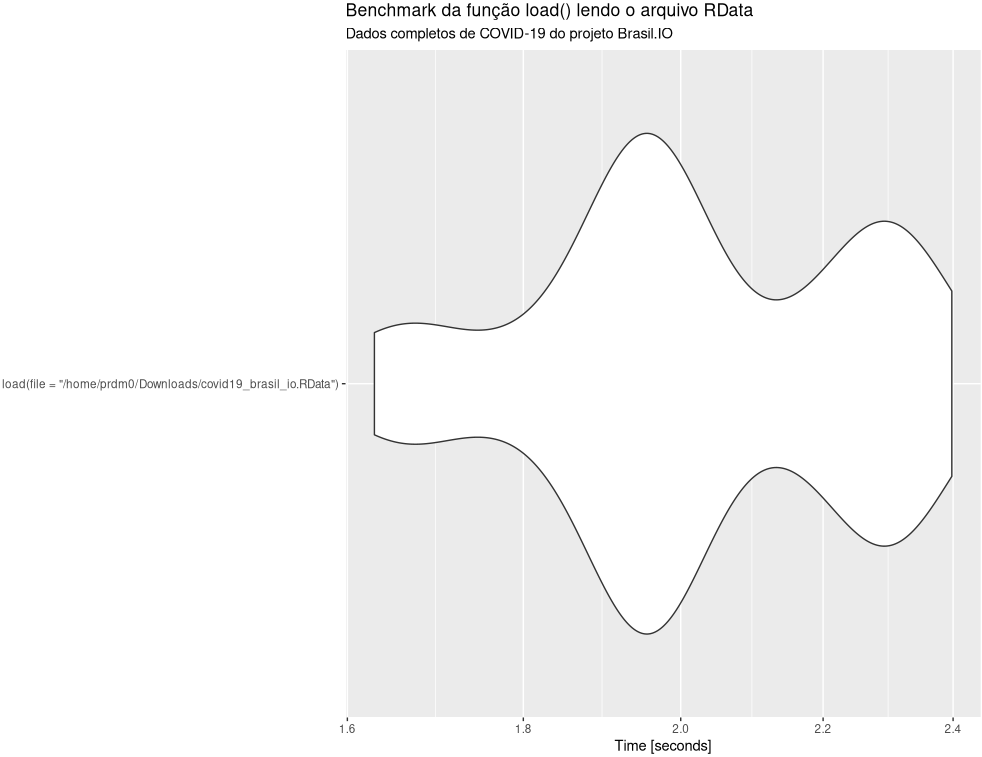
Isso mostra que considerar o arquivo RData pode ser uma boa ideia para todos. As vantagens de se considerar também a distribuição do formato RData são:
- Arquivo mais de 31 vezes menor que o arquivo disponibilizado em https://data.brasil.io/dataset/covid19/caso_full.csv.gz;
- É possível ler facilmente arquivos RData em R ou Python e muito provavelmente em vários outras linguagens;
- É muito rápido e fácil gerar o arquivo RData;
- É muito rápido ler o arquivo RData.
Importante: Note que é uma sugestão de um formato a mais de distribuição dos dados que poderá ser útil para muitas pessoas. Não sugiro jamais remover os outros formatos.
Dados em R:

Dados em Python:
Não sou programador de Python mas testei a biblioteca pyreadr e funcionou muito bem:

Acredito que disponibilizar o arquivo RData seria muito útil e algo muito fácil de implementar. Isso poderia abrir espaço para as pessoas desistirem de onerar a API de vocês. Isso seria uma forma de diminuir os abusos.
@turicas, eu cadastrei 2 tokens de acesso, estou usando PHP para acessar via cURL a API, para pegar dados apenas 1x ao dia, mas não consigo acessar... me dá o erro 401... não quero onerar de forma alguma a API de vocês, mas não vou poder buscar as informações 1x ao dia? Não é plausível?
Eu efetuei uma requisição para API utilizando a biblioteca Axios com node.js, o que acabou facilitando bastante consumir essa API de forma bem simples. Abaixo tem o código
const axios = require('axios')
const keyToken = '[SUA CHAVE TOKEN]'
axios.get('https://api.brasil.io/v1/dataset/covid19/caso/data/?format=json', {
headers: {
Authorization: `token ${keyToken}`
}
}).then(function(response) {
const structure = response.data
const data = response.data.results.forEach(element => {
const city = element.city
const confirmed = element.confirmed
const deaths = element.deaths
const state = element.state
console.log(`Cidade: ${city}`,
`Quantidade de confirmados: ${confirmed}`,
`Quantidade de mortes ${deaths}`,
`Estado: ${state}`)
});
console.log(data)
}).catch(function (error) {
if (error) {
console.log(error)
}
})
Olá! Estou tentando acessar a API porém estou com problemas.
Estou enviando o meu token no header com a chave gerada no site, porém ainda estou recebendo o erro 401.
Fiz o teste no site: https://reqbin.com/ conforme foi recomendado por um de nossos colegas, mas o resultado do teste com Bearer Token e Custom, retornam 401 também.
Isso me leva a crer que possa existir um problema com o token.
Fiz um Interceptor usando Angular para enviar o token no meu head, quando confiro o head em Network a opção Authorization retorna o valor: authorization: Bearer <meu token>
Mas o erro 401, persiste.
Podem me ajudar? Obrigado :)
import { Injectable } from '@angular/core';
import { HttpEvent, HttpInterceptor, HttpHandler, HttpRequest } from '@angular/common/http';
import { Observable } from 'rxjs';
@Injectable()
export class TokenInterceptor implements HttpInterceptor {
intercept(request: HttpRequest<any>, next: HttpHandler): Observable<HttpEvent<any>> {
const token = '<meuToken>';
const newRequest = request.clone({setHeaders: {'Authorization': `Bearer ${token}`}})
return next.handle(newRequest);
}
}
Fiz outra tentativa direto no meu service, porém o erro 401 persiste.
Também tentei fazer um GET na api usando a aplicação do Postman e passando o Token no Authorization, também não obtive sucesso.
Estou usando Angular para desenvolver a aplicação, mas acredito que exista uma falha nos tokens que estão sendo gerados no site.
constructor(private http: HttpClient) { }
dataList(): Observable<any>{
const httpHeaders = new HttpHeaders({
'Authorization': 'Bearer <meuToken>'
});
return this.http.get(`${environment.apiUrlBrasilioData}`, {headers: httpHeaders});
};
Olá pessoal, é possível configurar a requisição GET no Insomnia para testes?
Tentei fazer por aqui, coloquei no Header o parâmetro Authorization com a chave que gerei, mas retorna:
{
"message": "As credenciais de autenticação não foram fornecidas ou estão inválidas. Acesse https://brasil.io/auth/tokens-api/ para gerenciar suas chaves de acesso a API ou nosso blog post com o passo-a-passo da autenticação em https://blog.brasil.io/2020/10/31/nossa-api-sera-obrigatoriamente-autenticada/"
}
Tentei o endpoint https://api.brasil.io/v1/dataset/covid19/caso/data/?format=json que o @immichjs postou aqui.
Consegui resolver aqui, abaixo segue as telas do Insomnia para ilustrar e ajudar a quem precisar.

Nesta parte, atenção ao uso de aspas duplas, foi um detalhe que penei aqui.

Olá! Gostaria de saber como eu posso aplicar uma query como o limit na chamada de API. Eu quero apenas que tenha 10 itens e aplicar uma lógica neles para que saia o maior "last_available_confirmed" dos 10.

@ibandim123 Você pode user os query parameters limit e last_available_confirmed, mas info aqui
Python é muito ruim de visualizar qualquer coisa, estou tentando consumir no React mas o CORS ta impedindo mesmo meu header estando assim:
Authorization: "Token <meutoken>",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers": "*",
"User-Agent": "*",
Boa noite. Gente, o dataset de casos está ok? A propriedade CONFIRMED está muito acima do normal por UF. Estou fazendo algo errado? Como posso pegar o numero de casos do dia anterior?
Quando faço a requisição fica aparecendo esta menssagem: {'message': 'As credenciais de autenticação não foram fornecidas ou estão inválidas. Acesse https://brasil.io/auth/tokens-api/ para gerenciar suas chaves de acesso a API ou nosso blog post com o passo-a-passo da autenticação em https://blog.brasil.io/2020/10/31/nossa-api-sera-obrigatoriamente-autenticada/'}. sendo que eu já tenho uma chave
Sim, @elsonss1988. Dá o mesmo erro.
Na verdade, o caminho para download do arquivo CSV com o filtro é seguindo o padrão https://brasil.io/dataset/covid19/caso_full/...
Pelo os meus testes aqui, o caminho https://api.brasil.io/v1/dataset/... não retorna CSV