Created
March 22, 2018 15:53
-
-
Save turicas/6b9ca83dcd531a6cd4fd87ced2a28c70 to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import io | |
| import re | |
| import requests | |
| import rows | |
| def extrai_tabela(url): | |
| response = requests.get(url) | |
| return rows.import_from_pdf( | |
| io.BytesIO(response.content), | |
| ends_before=re.compile(r'\* ?Variação em .*'), | |
| ) | |
| arquivos = ['16032018194928.pdf', '18082017185431.pdf'] | |
| for arquivo in arquivos: | |
| url = f'http://www.imea.com.br/upload/publicacoes/arquivos/{arquivo}' | |
| print(f'Baixando {url}') | |
| table = extrai_tabela(url) | |
| print(rows.export_to_txt(table)) |
When I tried to run this code I get the error:
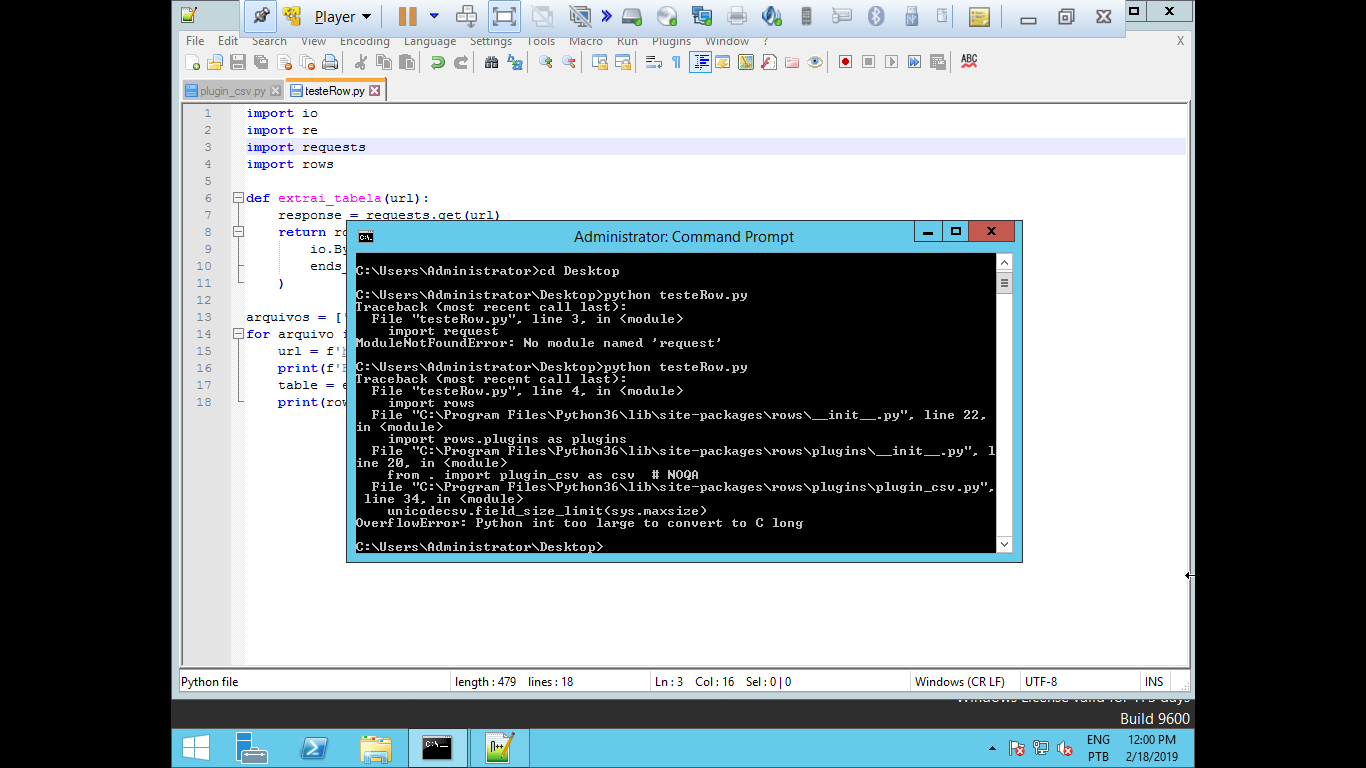
Any idea why?
@Danielydsm try access file plugin_csv.py and change value in line unicodecsv.field_size_limit to unicodecsv.field_size_limit(16777216)
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Na versão 0.3.1 não encontro
import_from_pdf, is it perhaps something you're still working on? 🤔