sudo apt-get install ganglia-webfrontend ganglia-monitor在主节点上安装ganglia-webfrontend和ganglia-monitor。在其他监视节点上,只需要安装ganglia-monitor即可
将ganglia的文件链接到apache的默认目录下
sudo ln -s /usr/share/ganglia-webfrontend /var/www/ganglia在其他监视节点上,只需要安装ganglia-monitor
sudo apt-get install ganglia-monitor- gmond.conf
在每个节点上都需要配置/etc/ganglia/gmond.conf,配置相同如下所示
sudo vim /etc/ganglia/gmond.conf修改后的/etc/ganglia/gmond.conf
globals {
daemonize = yes ##以后台的方式运行
setuid = yes
user = ganglia #运行Ganglia的用户
debug_level = 0
max_udp_msg_len = 1472
mute = no
deaf = no
host_dmax = 0 /*secs */
cleanup_threshold = 300 /*secs */
gexec = no
send_metadata_interval = 10 #发送数据的时间间隔
}
/* If a cluster attribute is specified, then all gmond hosts are wrapped inside
* of a <CLUSTER> tag. If you do not specify a cluster tag, then all <HOSTS> will
* NOT be wrapped inside of a <CLUSTER> tag. */
cluster {
name = "hadoop-cluster" #集群名称
owner = "ganglia" #运行Ganglia的用户
latlong = "unspecified"
url = "unspecified"
}
/* The host section describes attributes of the host, like the location */
host {
location = "unspecified"
}
/* Feel free to specify as many udp_send_channels as you like. Gmond
used to only support having a single channel */
udp_send_channel {
#mcast_join = 239.2.11.71 #注释掉组播
host = master #发送给安装gmetad的机器
port = 8649 #监听端口
ttl = 1
}
/* You can specify as many udp_recv_channels as you like as well. */
udp_recv_channel {
#mcast_join = 239.2.11.71 #注释掉组播
port = 8649
#bind = 239.2.11.71
}
/* You can specify as many tcp_accept_channels as you like to share
an xml description of the state of the cluster */
tcp_accept_channel {
port = 8649
}
- gmetad.conf
在主节点上还需要配置/etc/ganglia/gmetad.conf,这里面的名字hadoop-cluster和上面gmond.conf中name应该一致。
/etc/ganglia/gmetad.conf
sudo vim /etc/ganglia/gmetad.conf修改为以下内容
data_source "hadoop-cluster" 10 master:8649 slave:8649
setuid_username "nobody"
rrd_rootdir "/var/lib/ganglia/rrds"
gridname "hadoop-cluster"
注:master:8649 slave:8649为要监听的主机和端口,data_source中hadoop-cluster与gmond.conf中name一致
在所有hadoop所在的节点,均需要配置hadoop-metrics2.properties,配置如下:
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# syntax: [prefix].[source|sink].[instance].[options]
# See javadoc of package-info.java for org.apache.hadoop.metrics2 for details
#注释掉以前原有配置
#*.sink.file.class=org.apache.hadoop.metrics2.sink.FileSink
# default sampling period, in seconds
#*.period=10
# The namenode-metrics.out will contain metrics from all context
#namenode.sink.file.filename=namenode-metrics.out
# Specifying a special sampling period for namenode:
#namenode.sink.*.period=8
#datanode.sink.file.filename=datanode-metrics.out
# the following example split metrics of different
# context to different sinks (in this case files)
#jobtracker.sink.file_jvm.context=jvm
#jobtracker.sink.file_jvm.filename=jobtracker-jvm-metrics.out
#jobtracker.sink.file_mapred.context=mapred
#jobtracker.sink.file_mapred.filename=jobtracker-mapred-metrics.out
#tasktracker.sink.file.filename=tasktracker-metrics.out
#maptask.sink.file.filename=maptask-metrics.out
#reducetask.sink.file.filename=reducetask-metrics.out
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
*.sink.ganglia.slope=jvm.metrics.gcCount=zero,jvm.metrics.memHeapUsedM=both
*.sink.ganglia.dmax=jvm.metrics.threadsBlocked=70,jvm.metrics.memHeapUsedM=40
namenode.sink.ganglia.servers=master:8649
resourcemanager.sink.ganglia.servers=master:8649
datanode.sink.ganglia.servers=master:8649
nodemanager.sink.ganglia.servers=master:8649
maptask.sink.ganglia.servers=master:8649
reducetask.sink.ganglia.servers=master:8649在所有的hbase节点中均配置hadoop-metrics2-hbase.properties,配置如下:
# syntax: [prefix].[source|sink].[instance].[options]
# See javadoc of package-info.java for org.apache.hadoop.metrics2 for details
#*.sink.file*.class=org.apache.hadoop.metrics2.sink.FileSink
# default sampling period
#*.period=10
# Below are some examples of sinks that could be used
# to monitor different hbase daemons.
# hbase.sink.file-all.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file-all.filename=all.metrics
# hbase.sink.file0.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file0.context=hmaster
# hbase.sink.file0.filename=master.metrics
# hbase.sink.file1.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file1.context=thrift-one
# hbase.sink.file1.filename=thrift-one.metrics
# hbase.sink.file2.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file2.context=thrift-two
# hbase.sink.file2.filename=thrift-one.metrics
# hbase.sink.file3.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file3.context=rest
# hbase.sink.file3.filename=rest.metrics
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
hbase.sink.ganglia.period=10
hbase.sink.ganglia.servers=master:8649
start-dfs.sh
start-yarn.sh
start-hbase.sh先需要重启hadoop和hbase 。在各个节点上启动gmond服务,主节点还需要启动gmetad服务。
使用apt-get方式安装的Ganglia,可以直接用service方式启动。
-
sudo service ganglia-monitor start(每台机器都需要启动) -
sudo service gmetad start(在安装了ganglia-webfrontend的机器上启动)
登录浏览器查看:http://master/ganglia,如果Hosts up为9即表示安装成功。
若安装不成功,有几个很有用的调试命令:
- 以调试模式启动gmetad:gmetad -d 9
- 查看gmetad收集到的XML文件:telnet master 8649
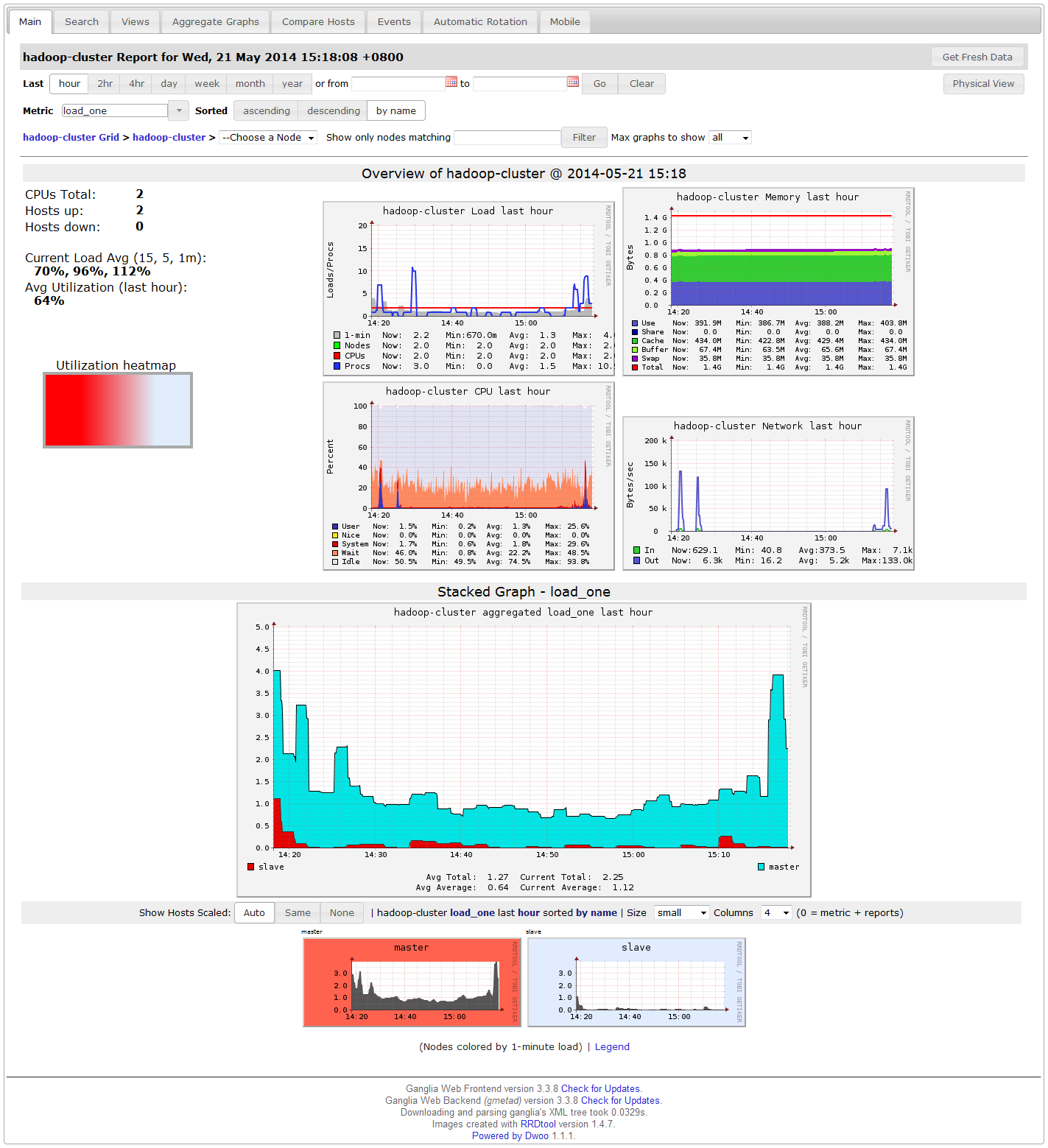
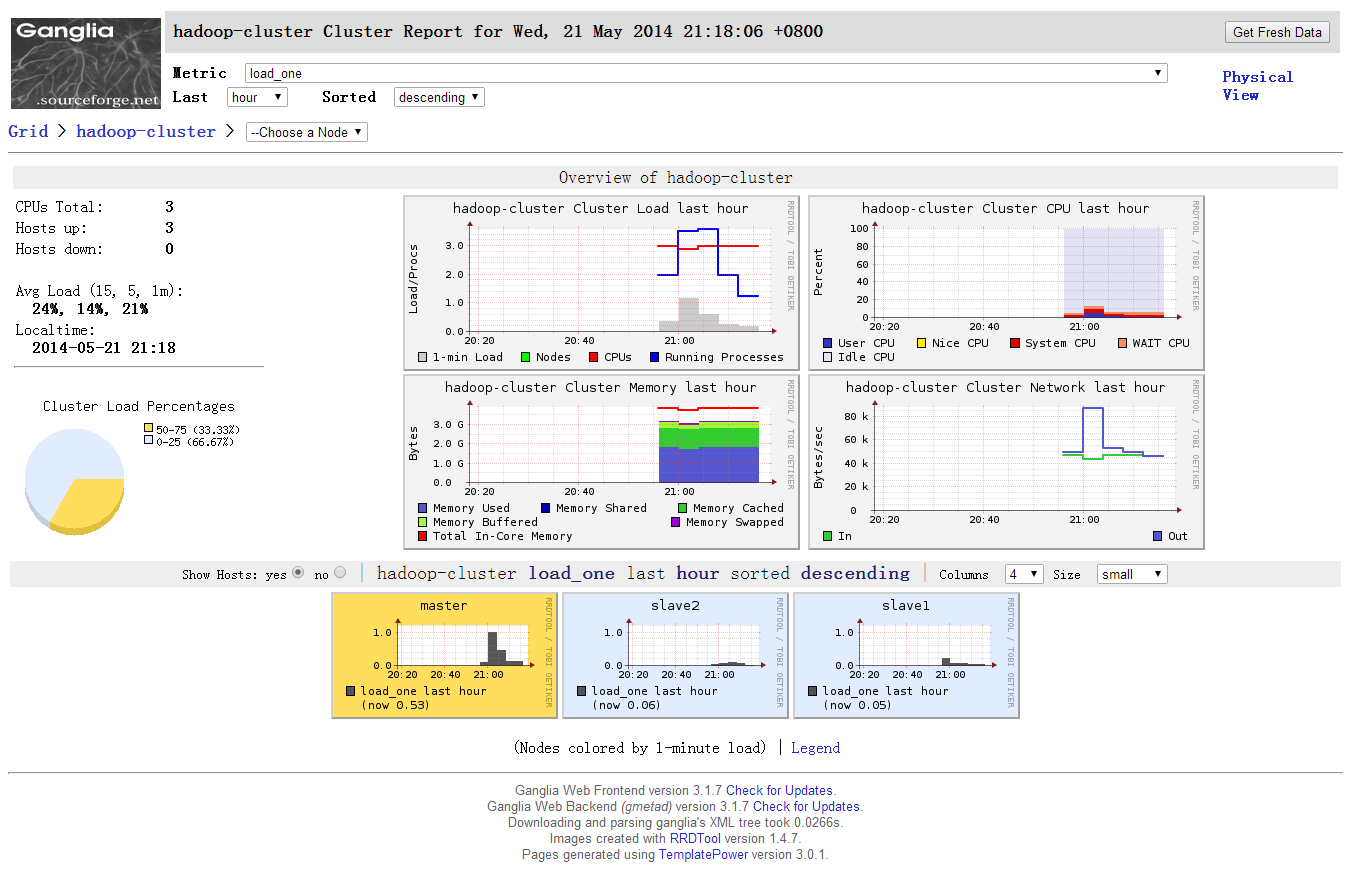

good!