👉 For a Read-Heavy System - Consider using a Cache.
👉 For a Write-Heavy System - Use Message Queues for async processing
👉 For a Low Latency Requirement - Consider using a Cache and CDN.
👉 If we need a system to be ACID complaint, we should go for RDBMS or SQL Database
👉 If data is unstructured & doesn't require ACID properties, we should go for NO-SQL Database
👉 If the system has complex data in the form of videos, images, files etc, we should go for Blob/Object storage
👉 If the system requires complex pre-computation like a news feed, we should use a Message Queue & Cache
👉 If the system requires searching data in high volume, we should consider using a search index, tries or a search engine like Elasticsearch
👉 If the system requires to Scale SQL Database, we should consider using Database Sharding
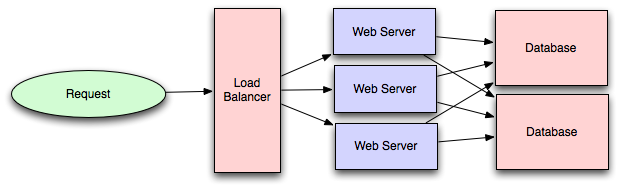
👉 If the system requires High Availability, Performance, & Throughput, we should consider using a Load Balancer
👉 If the system requires faster data delivery globally, reliability, high availability, & performance, we should consider using a CDN
👉 If the system has data with nodes, edges, and relationships like friend lists, & road connections, we should consider using a Graph Database
👉 If the system needs scaling of various components like servers, databases, etc, we should consider using Horizontal Scaling
👉 If the system requires high-performing database queries, we should use Database Indexes
👉 If the system requires bulk job processing, we should consider using Batch Processing & Message Queues
👉 If the system requires reducing server load and preventing DOS attacks, we should use a Rate Limiter
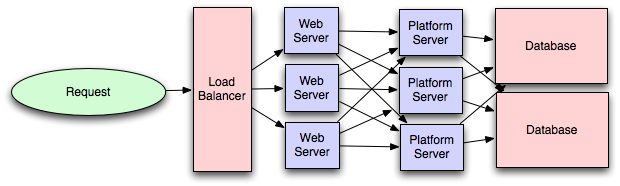
👉 If the system has microservices, we should consider using an API Gateway (Authentication, SSL Termination, Routing etc)
👉 If the system has a single point of failure, we should implement Redundancy in that component
👉 If the system needs to be fault-tolerant, & durable, we should implement Data Replication (creating multiple copies of data on different servers)
👉 If the system needs user-to-user communication (bi-directional) in a fast way, we should use Websockets
👉 If the system needs the ability to detect failures in a distributed system, we should implement a Heartbeat