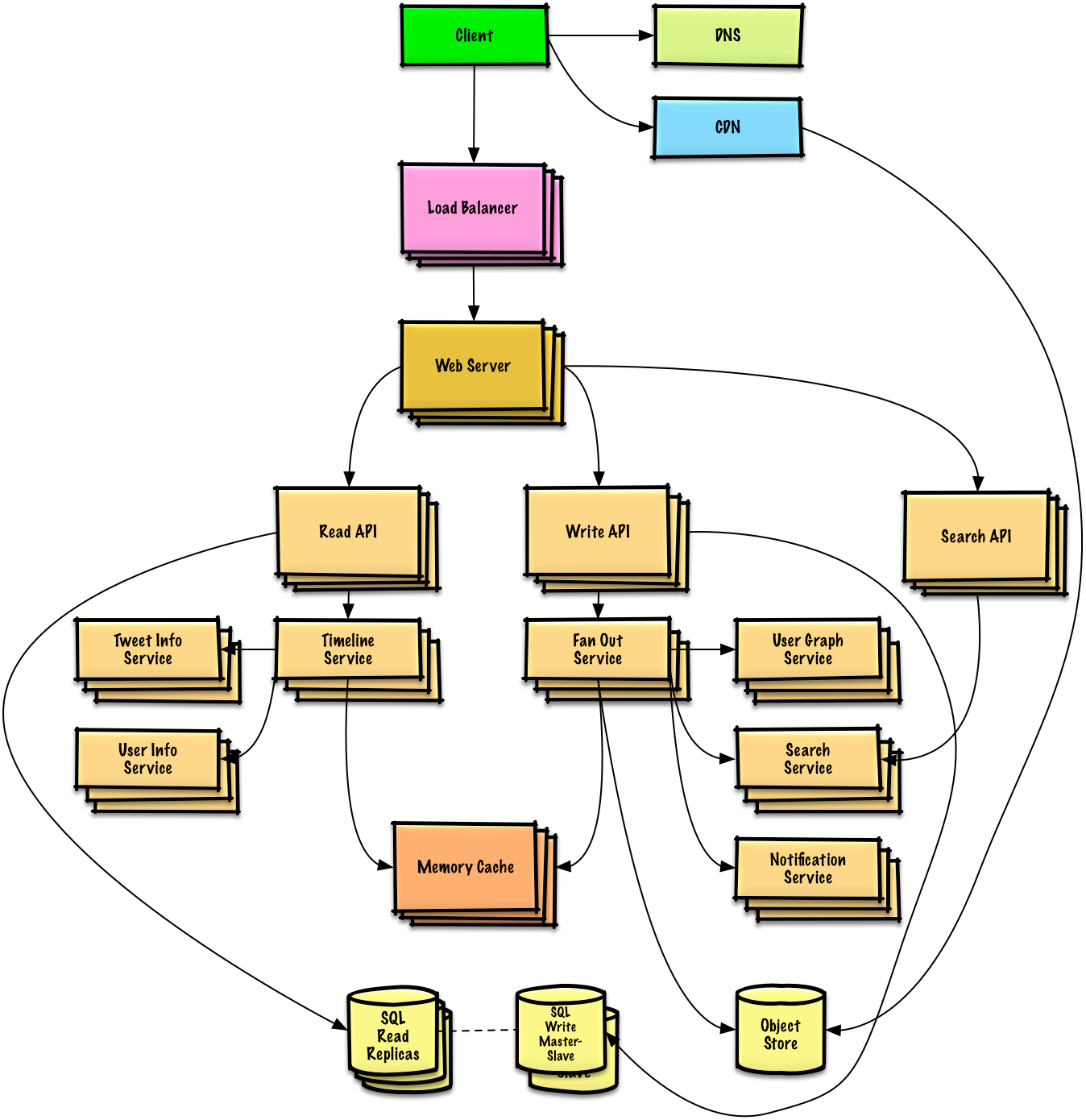
Pic credits : Github
Welcome back peeps. We are now starting System Design Series ( over weekends) where we will cover how to design large ( and great) systems, the techniques, tip/tricks that you can refer to in order to scale these systems. As a senior software engineer it’s expected that you know not just the breadth but also depth of the system design concepts.