https://s3.amazonaws.com/amazon-reviews-pds/readme.html
vmacs:amazon-reviews vs$ find . -type f | cut -d/ -f2 | sort | uniq -c
10 product_category=Apparel
10 product_category=Automotive
10 product_category=Baby
10 product_category=Beauty
10 product_category=Books
10 product_category=Camera
10 product_category=Digital_Ebook_Purchase
10 product_category=Digital_Music_Purchase
10 product_category=Digital_Software
10 product_category=Digital_Video_Download
10 product_category=Digital_Video_Games
10 product_category=Electronics
10 product_category=Furniture
10 product_category=Gift_Card
10 product_category=Grocery
10 product_category=Health_&_Personal_Care
10 product_category=Home
10 product_category=Home_Entertainment
10 product_category=Home_Improvement
10 product_category=Jewelry
10 product_category=Kitchen
10 product_category=Lawn_and_Garden
10 product_category=Luggage
10 product_category=Major_Appliances
10 product_category=Mobile_Apps
10 product_category=Mobile_Electronics
10 product_category=Music
10 product_category=Musical_Instruments
10 product_category=Office_Products
10 product_category=Outdoors
10 product_category=PC
10 product_category=Personal_Care_Appliances
10 product_category=Pet_Products
10 product_category=Shoes
10 product_category=Software
10 product_category=Sports
10 product_category=Tools
10 product_category=Toys
10 product_category=Video
10 product_category=Video_DVD
10 product_category=Video_Games
10 product_category=Watches
10 product_category=Wireless
Sample query
select sum(total_votes), product_category from amazon_reviews where review_date > '2007' and review_date < '2009' group by product_category



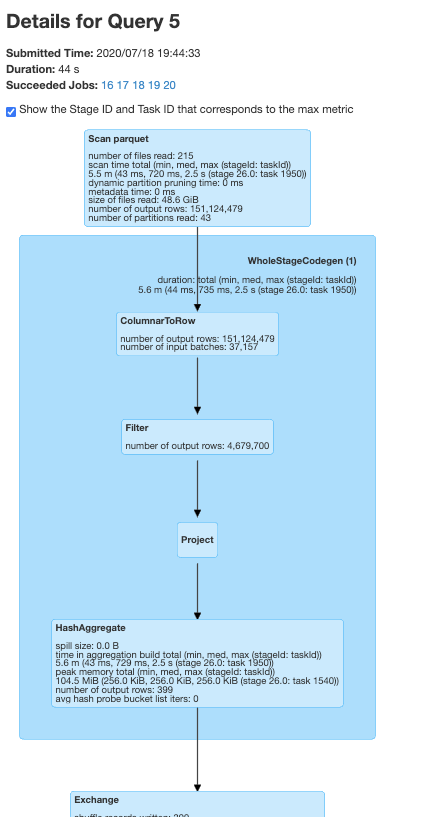

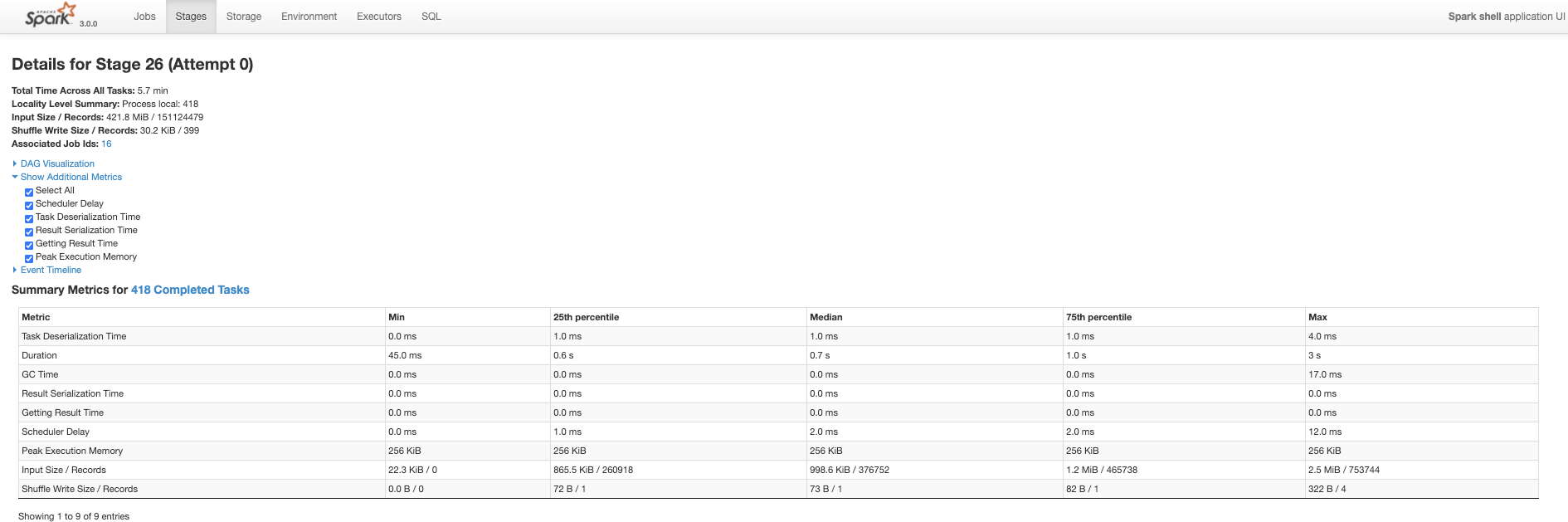
As-is (10 partitions)
Takes like 17 seconds, but the data has some natural date based proximity in files.