Although GitHub.com is still a Rails monolith [...], over the past few years we've begun the process of extracting critical functionality outside of the monolith, by rewriting critical pieces of functionality (mostly code that needs to run faster and/or more reliably than what we can accomplish with Ruby) particularly ones where performance is critical. Last year, we deployed a new Authorizations service in production, authzd, which powers the new "Fine-grained Authorizations" feature.
This has been an interesting challenge because authzd is our first critical Go service that reads from production MySQL databases as part of a web request. In the past, we've deployed other other services in our infrastructure that read and write to MySQL, but they are either internal management services (such as our Search cluster manager, manticore), or async batch jobs (such as gitbackups, which takes care of scheduling Git repository backups). authzd is called several times during a normal request to our Rails monolith, meaning that its requirements for performance and reliability are much more stringent.
To top off this challenge, authzd is deployed to our Kubernetes clusters, on which we've been experiencing some hard-to-debug issues with high latencies when opening new TCP connections. One of the most dangerous lies that programmers tell themselves is that the network is reliable, because, well, most of the time the network is reliable. But when it gets slow, or spotty, that's when things start breaking, and we get to find out the underlying issues in the libraries we take for granted.
Here's what it took, from a MySQL point of view, to get authzd ready to ship on Satellite whilst meeting our availability SLOs.
"Invalid connection (unexpected EOF)" was for a long time the big White Whale of Go MySQL bugs. It has been more than 2 years since I initially diagnosed and reported the bug upstream: we first came across this error when deploying the first versions of our repository backup orchestrator (gitbackups) to production, and there was no consensus on how to fix it on the MySQL driver back then, so we fixed gitbackups with a workaround in the application's code. Last year, when doing our first authzd deploys to production, the issue was back in full effect: hundreds of Invalid connection errors per minute were dramatically increasing authzd's error response rate, so I went back to the drawing board and finally landed a fix upstream that solves the issue without having to change any application code. Let's dive into the issue and its fix.
The job of a Go SQL driver is to provide a very simple primitive to the database/sql package that comes in the Go standard library: a "SQL connection". The connections that a driver provides are stateful, and cannot be used concurrently, because this is the default behavior for the connections of all major SQL servers (including MySQL and Postgres). This is where the database/sql package comes in: its job is to manage the access and lifetime of these connections. The DB struct in the package, which is the entry point for all operations you can perform on a SQL database, is an abstraction over a connection pool, full of individual connections provided by the driver. Hence, calling methods like (*DB).Query or (*DB).Exec involves quite a bit of complex logic: polling the connection pool for a connection that is active but idle, or calling the underlying Driver to create a new connection if all the existing ones are busy, and then executing the command or query and returning the connection back to the pool, or discarding it if the pool is full.
The "unexpected EOF" crash we experienced in both gitbackups and authzd happens always in the same location: when taking a connection out of the connection pool and trying to perform a query on it. The reason was obvious simply by reading the MySQL server logs: the server was closing connections that had spent too long in Go's sql.(*DB) pool because they had reached their idle timeout (we run our production MySQL clusters with a pretty aggressive idle timeout, 30s, to ensure we never have too many connections open at any given time). And yet, the fact that this invalid connection error was being reported to the app was puzzling (and a problem, because our service was continuously crashing): TCP connections being interrupted is a very common occurrence; the database/sql package is definitely designed to handle an interruption in any of the hundreds of simultaneous connections that can be sitting in a (*DB) pool at any time, and the specific Driver implementation is supposed to help with this. Whenever a Driver detects that a connection has become unhealthy (be it because it has been closed; or because it has received a bad packet or any of the many things that can go wrong with a SQL connection), it is supposed to return driver.ErrBadConn on the next call to any of the methods in the connection.
ErrBadConn is the magic word that signals to the database/sql package that this stateful connection is no longer valid: if the connection was in the pool, it needs to be removed from the pool; if the connection was just pulled from the pool to perform a query, it must be discarded and a new connection must be pulled from the pool (or created) so the query can be performed. So, with this logic in mind, it was to be expected that calling (*DB).Query would never fail with an "invalid connection" error, because even if the library attempted to perform the query in an invalid connection, the return of driver.ErrBadConn would cause the query to be retried in another connection, transparently and without the user noticing.
So, what was going on in authzd to cause all these "invalid connection" errors?
There is a nuanced mismatch between the TCP protocol and the MySQL wire protocol overlaid on top. A TCP connection is full-duplex (that is, data can be flowing in each direction independently of the other direction), whilst the overlaid MySQL protocol on top, once it's in its Command Phase, becomes fully client-managed: a MySQL server will only send a packet to a MySQL client in response to a packet from the client! This becomes an issue when the server has to close an active connection in Command Phase (because it has reached its idle timeout, or because connections are actively being pruned by e.g. pt-kill). Let's look at a network diagram:
Figure 1: I know you didn't want to look at one, but here's a network flow diagram

In this reproduction of the bug we can see a standard TCP handshake, followed by a request/response pair at the MySQL level. We then sleep for several seconds. After a while without sending requests to the MySQL server, we will hit the server-side timeout and the MySQL server will perform an active close our socket. When a TCP server closes a socket, the server's kernel sends a [FIN, ACK] pair to the client, which means that the server is finished sending data. The client's kernel acknowledges the [FIN, ACK] with an [ACK] but it does not close its side of the connection: this is what we mean by TCP being full-duplex. The write side (client -> server) of the connection is independent, and must be explicitly closed by calling close in the client.
In most network protocols on top of TCP, this is not an issue. The client is performing reads from the server, and as soon as it receives a [SYN, ACK], the next read will return an EOF error, because the Kernel knows that the server will not write more data to this connection. However, as discussed earlier, once a MySQL connection is in its Command Phase, the MySQL protocol is client-managed. The client only reads from the server after it has sent it a request, because the server only sends data in response to requests from the client!
The previous network diagram clearly shows the practical effects of this: after the sleeping period, we send a request to the server and this write succeeds because our side of the connection is still open. The server consequently answers our request with a [RST] packet because its side is actually closed -- we just don't know about it yet. And then, when our client attempts to read the response from the MySQL server, it belatedly finds out that the connection is invalid as it receives an EOF error.
This answers why our connection is crashing, but not why our application code is crashing with it. Our MySQL connection is no longer valid, and we found out about it (better late than never!), so why doesn't our MySQL driver return driver.ErrBadConn when this happens and lets database/sql retry our query in a brand new connection? Sadly, because this is not safe to do in the general case.
The sequence of events depicted in the previous network diagram is very frequent; in our production MySQL clusters it happens thousands of times per minute, particularly during off-peak hours when our service is mostly idle and the timeouts are reached. But that's far from the only thing that could cause a connection to be closed. What would happen if we performed an UPDATE in a perfectly healthy connection, MySQL executed it, and then our network went down before it could reply to us?
The Go MySQL driver would also receive an EOF after a valid write. But if it were to return driver.ErrBadConn, database/sql would go ahead and run the UPDATE statement on a new connection. Disaster! Data corruption! And what a thoroughly annoying place to be in: we know that in the common case (when MySQL kills our connection), it's safe to retry these queries. There was no error when writing the query to the network, but we know MySQL didn't receive it -- let alone executed it. But we must assume the worst, that the query did make it to the server. And hence, returning driver.ErrBadConn is not safe.
So, how do we go about fixing this? The most obvious solution, and the one we applied on gitbackups back in the day, is calling (*DB).SetConnMaxLifetime on our client to set the max lifetime of MySQL connections to a value lower than our MySQL cluster's idle timeout. This is far from ideal. For starters, SetConnMaxLifetime sets the maximum duration of any connection on the client, not it's maximum idle duration. That means that database/sql will continuously kill connections when they've lived that long, even if the connections are being actively used and could not trigger the server's idle timeout. The database/sql package does not provide a "maximum idle duration" API for databases, because not all SQL servers implement the concept of idle timeouts. Ah, the miseries of abstraction. In practice, this fix works OK except for the needless connection churn, and cases where the MySQL server is actively prunning connections, which this workaround cannot detect.
Clearly, the optimal solution would be checking for a connection's health once it's pulled from the connection pool, and before we attempt to write any requests to it. This was unfortunately not possible until the introduction of SessionResetter in Go 1.10: before that interface was available, there was no way to know when a connection was being returned to the pool, which is why the bug stalled for almost 2 years until we could come up with an adequate fix.
There are two ways to check the health of that connection: at the MySQL level, or at the TCP level. A MySQL health check involves sending a PING packet and waiting for its response. It is always safe to return driver.ErrBadConn because the ping packet does not perform write operations in MySQL (one would hope). There is however the drawback of adding arbitrary latency to the first operation performed on a connection fresh off the pool. That's a bit spooky, because connections are sent and returned to the pool very often in a Go application. Consequently, we went with the cheaper and simpler fix: simply checking whether the MySQL server had closed its side of the connection at the TCP level.
Performing this check is very inexpensive: all we have to do is a non-blocking read on our connection before we attempt any writes. If the server has closed its side of the connection, we'll get an EOF right away. If the connection is still open, the read will also return immediately but with an EWOULDBLOCK error, signaling that there's no data to be read (yet). Now, the good news is that all sockets in a Go program are already set to non-blocking mode (do not be fooled by the elegant abstraction of Goroutines; under the hood, the user-land Go scheduler uses an async event loop to put Goroutines to sleep and wake them once they have data to read -- how quaint). The bad news is that we do not get to perform non-blocking reads by calling e.g. net.Conn.Read, because that will make the scheduler put us right to sleep (again, the elegant abstraction of Goroutines). The proper interface to perform this non-blocking read wasn't introduced until Go 1.9: (*TCPConn).SyscallConn gives us access to the underlying file descriptor so we can use the read system call directly.
Armed with this new API, I was able to implement a connection health check that solved the "stale connections" issue with less than 5 microseconds of overhead. A non-blocking read is very quick because, huh, that's the point of non-blocking reads -- they don't block.
After deploying the fix in production, all the "Invalid Connection" needles disappeared right away, which resulted in our first "9" of availability for the service.

Figure 2: client-side needles and retries in authzd after our deploy at ~18:00
-
If your MySQL server has idle timeouts enabled, or is actively pruning connections, you do not need to call
(*DB).SetConnMaxLifetimein your production services. It is no longer needed as the driver can now gracefully detect and retry stale connections. Setting a max lifetime for connections simply causes unnecessary churn by killing and re-opening healthy connections. -
A good pattern to manage high-throughput access to MySQL is configuring your
sql.(*DB)pool ((*DB).SetMaxIdleConnsand(*DB).SetMaxOpenConns) with values that support your peak-hour traffic for the service, and making sure that your MySQL server is actively pruning idle connections during off-hours. These pruned connections will be detected by the MySQL driver and re-created when necessary.
When we put a service like authzd as a dependency in the standard request path for our monolith, we're fundamentally adding its response latency to the response latency of all the requests of our app (or, you know, for the requests that perform some kind of authorization -- which is a lot of them). It is crucial to ensure that authzd requests never take more time than what we have allotted for them, or they could very easily lead to a site-global performance degradation.
In the Rails side, this means being very careful with how we perform RPC requests to the service and how we time them out -- a topic worthy of its own blog post. In the Go server side, it means one thing: Context. The context package was introduced to the standard library back in Go 1.7, although its API was already available for years as a separate library. Its premise is simple: pass a context.Context to every single function that is involved in the life-cycle of your service's requests to make your service cancellation-aware. Each incoming HTTP request provides a Context object, which becomes canceled if the client disconnects early, and on top of it you can extend your Context with a deadline: this allows us to manage early request cancellation and request timeouts using a single API.
The engineering team in charge of developing the new service had done a stellar job of ensuring that all the methods in authzd were passing around a Context, including the methods that perform queries to MySQL. Passing a Context to these methods is fundamental because they're the most expensive part by far of our request life-cycle, and we need to ensure the database/sql query methods are receiving our request's Context so they can cancel our MySQL queries early if they're taking too long.
In practice, however, it seemed like authzd was not really taking into account request cancellations or timeouts:

Figure 3: in-service response times for an authzd deployment. The resolver's timeout was set to 1000ms -- you can tell from the helpful red line I've drawn in the graph, but definitely not from the many random spikes that climb all the way to 5000ms
Just from looking at these metrics it's quite clear that even though we're successfully propagating our request's Context throughout our application's code, there's a point during the lifetime of some requests where request cancellation is simply ignored. Finding out this spot through code review can be rather laborious, even when we strongly suspect that the source of the timeouts must be the Go MySQL driver, since it's the only part of our service that performs external requests. In this case, what I did was simply capturing a stack trace from a production host to find out where the code was blocking. It took several tries to capture a stack trace that seemed relevant, but once I had one that was blocking on a QueryContext call, the issue became immediately obvious:
0 0x00000000007704cb in net.(*sysDialer).doDialTCP
at /usr/local/go/src/net/tcpsock_posix.go:64
1 0x000000000077041a in net.(*sysDialer).dialTCP
at /usr/local/go/src/net/tcpsock_posix.go:61
2 0x00000000007374de in net.(*sysDialer).dialSingle
at /usr/local/go/src/net/dial.go:571
3 0x0000000000736d03 in net.(*sysDialer).dialSerial
at /usr/local/go/src/net/dial.go:539
4 0x00000000007355ad in net.(*Dialer).DialContext
at /usr/local/go/src/net/dial.go:417
5 0x000000000073472c in net.(*Dialer).Dial
at /usr/local/go/src/net/dial.go:340
6 0x00000000008fe651 in github.com/github/authzd/vendor/github.com/go-sql-driver/mysql.MySQLDriver.Open
at /home/vmg/src/gopath/src/github.com/github/authzd/vendor/github.com/go-sql-driver/mysql/driver.go:77
7 0x000000000091f0ff in github.com/github/authzd/vendor/github.com/go-sql-driver/mysql.(*MySQLDriver).Open
at <autogenerated>:1
8 0x0000000000645c60 in database/sql.dsnConnector.Connect
at /usr/local/go/src/database/sql/sql.go:636
9 0x000000000065b10d in database/sql.(*dsnConnector).Connect
at <autogenerated>:1
10 0x000000000064968f in database/sql.(*DB).conn
at /usr/local/go/src/database/sql/sql.go:1176
11 0x000000000065313e in database/sql.(*Stmt).connStmt
at /usr/local/go/src/database/sql/sql.go:2409
12 0x0000000000653a44 in database/sql.(*Stmt).QueryContext
at /usr/local/go/src/database/sql/sql.go:2461
[...]
The issue is that we're not propagating our request's Context as deeply as we had initially thought. Although we are passing the Context to QueryContext when performing SQL queries, and this context is being used to actually perform and timeout the SQL queries, there's a corner case in the database/sql/driver API we're missing: when we're trying to perform a query but there are no connections available in our connection pool, we need to create a new SQL connection by calling driver.Driver.Open() and, what do you know, this interface method does not take a context.Context!
The stack trace above clearly shows how in (8) we stop propagating our Context and simply call (*MysqlDriver).Open() with the DSN to our database. Opening a MySQL connection is not a cheap operation: it involves doing a TCP open, SSL negotiation (if we're using SSL), performing the MySQL handshake and authentication, and setting any default connection options. In total, there are at least 6 network round trips which do not obey our request timeout, because they're not Context-aware. It really is no wonder that the graph looked the way it looked.
Now, what do we do about this? The first thing we tried is setting the timeout value on our connection's DSN, which configures the TCP open timeout that (*MySQLDriver).Open uses. But this is not good enough, because TCP open is just the first step of initializing the connection: the remaining steps (MySQL handshake, etc) were not obeying any timeouts, so we still had requests going way past the global 1000ms timeout.
The proper fix involved refactoring a large chunk of the Go MySQL driver. The underlying issue was introduced back in the Go 1.8 release, which implemented the QueryContext and ExecContext APIs. Although these APIs could be used to cancel SQL queries because they are Context aware, the driver.Open method was not updated to actually take a context.Context argument. This new interface was only added two patches later, in Go 1.10: a new Connector interface was introduced, which had to be implemented separately from the driver itself. Hence, supporting both the old driver.Driver and driver.Connector interfaces required major changes in the structure of any SQL driver. Because of this complexity, and a lack of awareness that the old Driver.Open interface can easily lead to availability issues, the Go MySQL driver never got around to implementing the new interface.
Fortunately, I had the time and patience to undertake that refactoring. After shipping the resulting Go MySQL driver with the new Connector interface in authzd, we could verify on stack traces that the context passed to QueryContext was being propagated when creating new MySQL connections:
0 0x000000000076facb in net.(*sysDialer).doDialTCP
at /usr/local/go/src/net/tcpsock_posix.go:64
1 0x000000000076fa1a in net.(*sysDialer).dialTCP
at /usr/local/go/src/net/tcpsock_posix.go:61
2 0x0000000000736ade in net.(*sysDialer).dialSingle
at /usr/local/go/src/net/dial.go:571
3 0x0000000000736303 in net.(*sysDialer).dialSerial
at /usr/local/go/src/net/dial.go:539
4 0x0000000000734bad in net.(*Dialer).DialContext
at /usr/local/go/src/net/dial.go:417
5 0x00000000008fdf3e in github.com/github/authzd/vendor/github.com/go-sql-driver/mysql.(*connector).Connect
at /home/vmg/src/gopath/src/github.com/github/authzd/vendor/github.com/go-sql-driver/mysql/connector.go:43
6 0x00000000006491ef in database/sql.(*DB).conn
at /usr/local/go/src/database/sql/sql.go:1176
7 0x0000000000652c9e in database/sql.(*Stmt).connStmt
at /usr/local/go/src/database/sql/sql.go:2409
8 0x00000000006535a4 in database/sql.(*Stmt).QueryContext
at /usr/local/go/src/database/sql/sql.go:2461
[...]
Note how (*DB).conn now calls our driver's Connector interface directly, passing the current Context. Likewise, it was very clear from looking at the graphs that the global request timeout was being obeyed for all requests:

Figure 4: resolver response times with a timeout set at 90ms. You can tell that the Context is being respected because the 99th percentile looks more like a barcode than a graph
-
You do not need to change your
sql.(*DB)initialization to use the newsql.OpenDBAPI: even when callingsql.Openin Go 1.10, thedatabase/sqlpackage will detect theConnectorinterface and new connections will be created withContextawareness. -
However: changing your application to use
sql.OpenDBwith amysql.NewConnectorhas several benefits, most notably, the fact that the connection options for your MySQL cluster can be configured out of amysql.Configstruct, without requiring to compose a DSN. -
Do not set a
?timeout=(or itsmysql.(Config).Timeoutequivalent) on your MySQL driver. Having a static value for a dial timeout is a bad idea, because it doesn't take into account how much of your current request budget has been spent. -
Instead, make sure that every single SQL operation in your app is using the
QueryContext/ExecContextinterfaces, so they can be canceled based on your current request'sContextregardless of whether the connection is failing to dial or the query is slow to execute.
Last, but not least, here's a very serious security issue caused from a data race, which is as devious as it is subtle. We've talked a lot about how sql.(*DB) is simply a wrapper around a pool of stateful connections, but there's a detail we haven't discussed: performing a SQL query (either via (*DB).Query or (*DB).QueryContext), which is one of the most common operations you can do on a database, actually steals a connection from the pool.
Unlike a simple call to (*DB).Exec, which has no actual data returned from the database, (*DB).Query may return one or more Rows, and in order to read these rows from our app code, we must take control of the stateful connection where those rows will be written to by the server. That's the purpose of the sql.(*Rows) struct, which is returned from each call to Query and QueryContext: it wraps a connection we're borrowing from the pool so we can read the individual Rows from it. And this is why it's critical to call (*Rows).Close once we're done processing the results from our query; otherwise, the stolen connection will never be returned to the connection pool.
The flow of a normal SQL query with databaseb/sql has been identical since the very first stable release of Go. Something like:
rows, err := db.Query("SELECT a, b FROM some_table")
if err != nil {
return err
}
defer rows.Close()
for rows.Next() {
var a, b string
if err := rows.Scan(&a, &b); err != nil {
return err
}
...
}That's straightforward in practice: (*DB).Query returns a sql.(*Rows), which is stealing a connection from the SQL pool -- the connection on which we've performed the query. Subsequent calls to (*Rows).Next will read a result row from the connection, whose contents we can extract by calling (*Rows).Scan, until we finally call (*Rows).Close and then any further calls to Next will return false and any calls to Scan will return an error.
Under the hood, the implementation involving the underlying driver is more complex: the driver returns its own Rows interface, which is wrapped by sql.(*Rows), but as an optimization, the driver's Rows does not have a Scan method: it has a Next(dest []Value) error iterator. The idea behind this iterator it that it returns Value objects for each column in the SQL query, so calling sql.(*Rows).Next simply calls driver.Rows.Next under the hood, keeping a pointer to the values returned by the driver. Then, when the user calls sql.(*Rows).Scan, the standard library converts the driver's Value objects into the target types that the user passed as arguments to Scan. This means that the driver does not need to perform argument conversion (the Go standard library takes care of it), and that the driver can return borrowed memory from its rows iterator instead of allocating new Values, since the Scan method will convert the memory anyway.
As you may guess right away, the security issue we're dealing with is indeed caused by this "borrowed memory". Returning temporary memory is actually a very important optimization, which is explicitly encouraged in the Driver contract, and which works very well in practice for MySQL because it lets us return pointers to the connection buffer where we're reading results directly from MySQL. The row data for a SQL query as it comes off the wire can be passed directly to the Scan method, which will then parse its textual representation into the types (int, bool, string, etc) that the user is expecting. And this has always been safe to do, because we're not overwriting our connection buffer until the user calls sql.(*Rows).Next again, so no data races are possible.
...This was the case, at least, until the introduction of the QueryContext APIs in Go 1.8. With these new interfaces, it is now possible to call db.QueryContext with a Context object that will interrupt a query early -- we've discussed this at length in this post. But the fact that a query can be interrupted, or timed out, while we're scanning its resulting Rows opens up a serious security vulnerability: any time a SQL query is interrupted while inside a sql.(*Rows).Scan call, the driver will start overwriting the underlying MySQL connection buffer, and Scan will return corrupted data.
This may seem surprising, but it makes sense if we understand that canceling our Context means canceling the SQL query in the client, not in the MySQL server. The MySQL server is going to continue serving the results of the query through of our active MySQL connection, so if we want to be able to re-use the connection where a query has been canceled, we must first "drain" all the result packets that the server has sent us. To drain and discard all the remaining rows in the query, we need to read these packets into our connection buffer, and since query cancellation can happen at the same time as a Scan call, we will overwrite the memory behind the Values the user is scanning from. The result is, with an extremely high likelihood, corrupted data.
This race is certainly spooky as described so far, but here's the scariest thing of it all: in practice, you won't be able to tell if the race is happening or has happened in your app. In the previous example of rows.Scan usage, despite the fact that we're performing error checking, there is no reliable way to tell if our SQL query was canceled because our Context expired. If context cancellation has happened inside the rows.Scan call (i.e. where it needs to happen for this data race to trigger), the row values will be scanned, potentially with corrupted data, but no error will be returned because rows.Scan only checks if the rows are closed once when entering the function. Hence, when the race triggers we're getting back corrupted data without an error return. We won't be able to tell that the query has been canceled until our next call to rows.Scan -- but that call will never happen because rows.Next() is going to return false, again without reporting an error.
The only way to tell whether scanning the rows of our SQL query has finished cleanly or whether the query has been canceled early is checking the return value of rows.Close. And we're not doing that because the rows are being closed in a defer statement. Oof. A quick Code Search for rows.Close() on GitHub shows that pretty much nobody is explicitly checking the return value of rows.Close() in their Go code. This was actually safe to do before the QueryContext APIs were introduced, because rows.Scan would always catch any errors, but since Go 1.8, this is simply not correct. Even after this data race is fixed in the Go MySQL driver, you won't be able to tell whether you have scanned all the rows of your SQL query unless you check the return value of rows.Close(). So update your linters accordingly.
Now, I can think of several ways to fix this race. The most obvious is to always clone memory when returning from driver.Rows.Next, but this is also the slowest. The whole point of the Driver contract is that the driver does not allocate memory when calling driver.Rows.Next, because the memory allocation is delayed until the user calls sql.(*Rows).Scan. If we allocate in Next, we're allocating twice for each row, which mean that this bug fix would cause a significant performance regression. The Go MySQL maintainers were not OK with this, and I wasn't either. Other similar approaches such as truncating the underlying connection buffer when calling sql.(*Rows).Close were rejected by the same reason: they potentially allocate memory on each Scan. All these rejected fixes led to a stalemate between the maintainers which caused this critical bug to become stale for 6+ months. I personally find it terrifying that such a bug can go unfixed for so long, so I had to come up with a hot new take to fix the issue in our production hosts without causing a performance regression.
The first thing I attempted was "draining" the MySQL connection without using the underlying connection buffer. If we don't write to the connection buffer, then there can be no data race. This quickly became a nightmare of spaghetti code, because MySQL can send lots of packets which we must drain, and these packets all have different sizes, defined in their headers. Partially parsing these headers without a buffer was not pretty.
After some more thought, I finally came up with a solution which was extremely simple and fast enough to be eventually merged upstream: double buffering. In ancient Computer Graphics stacks, one would write individual pixels directly on a frame buffer, and the screen/monitor would simultaneously read the pixels at its given refresh rate. When the frame buffer was being written to while the screen was reading from it, a graphical glitch would arise -- what we commonly call flickering. Flickering is fundamentally a data race which you can see with your own eyes, and you'll agree that's a pretty cool concept. The most straightforward way to fix flickering in computer graphics is to allocate two frame buffers: one buffer that the screen will be reading from (the front buffer), and another buffer that the graphics processor will be writing to (the back buffer). When the graphics processor is done rendering a frame, we atomically flip the back buffer with the front buffer, so the screen will never read a frame that is currently being composed.

Figure 5: Double Buffering in the Nintendo 64 graphics stack. If this shit is good enough for Mario, it's good enough for the MySQL driver
This situation surely sounds a lot like what's happening with the connection buffer on the MySQL driver, so why not fix it in the same way? In our case, when our driver.Rows struct is being closed because a query was canceled early, we swap our connection buffer with a background buffer, so that the user can still call sql.Rows.Scan on the front buffer while we're draining the MySQL connection into the back buffer. The next time a SQL query is performed on the same connection, we're going to continue reading into the background buffer, until the Rows are closed again and we flip the buffers to their original positions. This implementation is trivial, and although it allocates memory, it only does so once for the lifetime of a MySQL connection, so the allocation is easily amortized. We further optimized this corner case by delaying the allocation of the back buffer until the first time we need to drain data into it; in the common case where no queries have been canceled early in a MySQL connection, no extra allocations will be performed.
After carefully crafting some benchmarks to ensure that the double-buffering approach was not causing performance regressions in any cases, I finally landed the bug fix upstream. Unfortunately, we have no way to check how often we've performed corrupted reads in the past because of this bug, but it's probably been quite a few because despite the subtlety in its origin, it is surprisingly easy to trigger.
-
Always do an explicit check in for the error return in
(*Rows).Close: it's the only way to detect whether the SQL query has been interrupted during scanning. However, do not remove thedefer rows.Close()call in your app, as it's the only way theRowswill be closed if apanicor early return happens during your scanning. Calling(*Rows).Closeseveral times is always safe. -
Never use
(*Rows).Scanwith asql.RawBytestarget. Even though the Go MySQL driver is now much more resilient, accessingRawBytescan and will fail with other SQL drivers if your query is cancelled early. You will most likely read invalid data if that happens. The only difference between scanning into[]byteandsql.RawBytesis that the raw version will not allocate extra memory; this tiny optimization is not worth the potential data race in aContext-aware application.
MySQL reliability is only one part of the availability story for authzd. A titanic amount of work has been put by @vroldanbet to overcome the Kubernetes latency issues through aggressive timeouts & retries for our HTTP connections, and earlier this week, our SRE teams started a daring effort to get authzd over the finish line in time for Satellite (this is called "future clickbait" -- stay tuned for this story because it's also very cool).
This is the progress we've made, together, in one month:
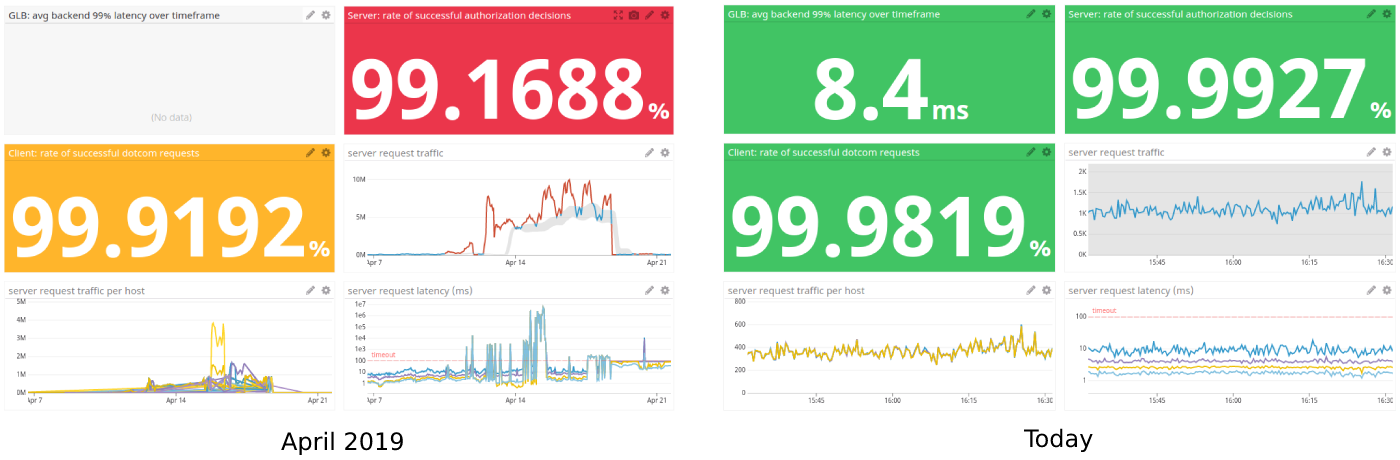
Not graphed: the hard lessons learned about Go and MySQL. Fortunately these are written down and upstreamed, so shipping these kind of services is only going to get easier from now on.
@vmg
Regarding the data race issue:
From the Go implementation, when the query context is canceled or times out, Rows'
rs.lasterrwould be set to an error, e.g. Canceled or DeadlineExceeded.https://golang.org/src/database/sql/sql.go#L2824
Therefore it should be sufficient to check
Rows.Err()to know if the previousRows.Scansucceeded or not, like the following. Am I misunderstanding something?