PaddlePaddle is a deep learning framework originally developed in Baidu four years ago. Experienced Baidu researchers and engineers have successfully applied it in 80% of Baidu products. When we open sourced PaddlePaddle in September 2016, we know it is time to make it easy-to-use by everyone who is interested in deep learning.
Today we are happy to announce the alpha release of our new API. And we updated example programs in our open source book Deep Learning with PaddlePaddle accordingly.
The following screenshot shows that a PaddlePaddle program using the new API could be much shorter than its old counterpart.
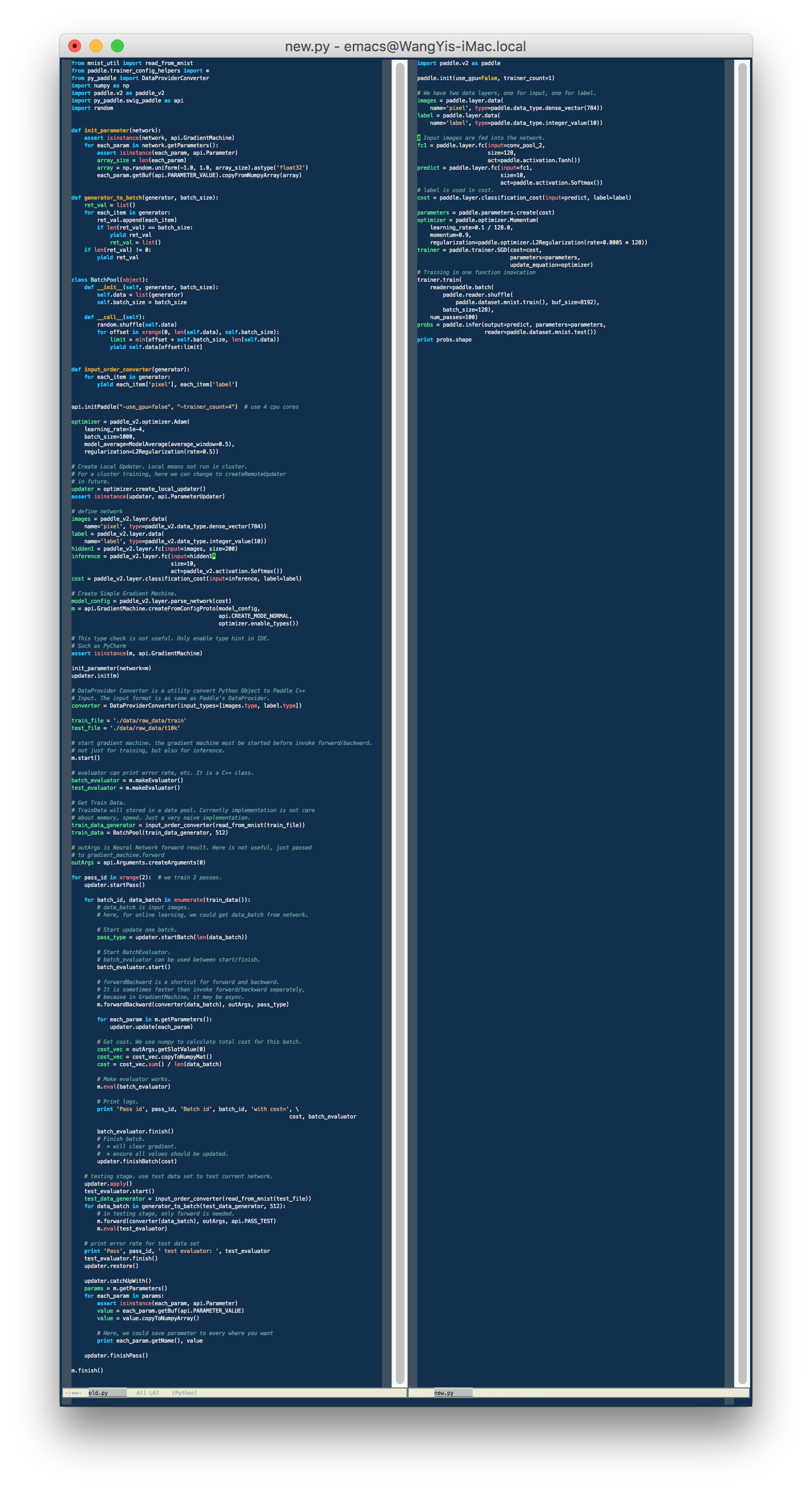
This significant simplification comes from several aspects.
New research requires a flexible way to describing innovative deep learning algorithms. For example, a GAN model contains two networks, whose layers share some parameters. Also, during the training, we need to fix some parameters while updating some others. With our old API, users would have to access very low-level APIs, which are often undocumented, for such flexibility. With the new API, the illustrative GAN example take a few lines of code.
PaddlePaddle was born to support distributed training. The old API exposes many details that users need to know before writing the distributed program. It is true that PaddlePaddle can run a train loop pre-defined in C++ code, but it prevents PaddlePaddle programs from running inside Jupyter Notebook, an ideal solution to documenting the work. In the new API, we provide higher-level APIs like train, test, and infer. For example, the train API can run a local training job and is going to be able to run a distributed job on a Kubernetes cluster.
Data loading in industrial AI applications is far from trivial and usually cost tons of source code. Our new API provides compositional concepts of reader, reader-creator, and reader-decorator, which enables the reuse of data operations. For example, we can define a reader-creator, impressions(), in a few lines of Python code, that reads search engine's impression log stream from Kafka, and another reader, clicks(), for reading the click stream. Then, we can buffer and shuffle using predefined reader-decorators. We can even compose/join data streams:
r = paddle.reader.shuffle(
paddle.reader.compose(
paddle.reader.buffer(impressions(impression_url)),
paddle.reader.buffer(clicks(click_url))),
4096)
If we want a small subset of 5000 instances for quick experiment, we can use
paddle.reader.firstn(r, 5000)
In package paddle.datasets, we provide pre-defined readers that download public datasets and read from local cache.
We will keep improve this new API. Your comments, feedback, and code contribution are highly appreciated!