-
-
Save wangkuiyi/5aa5ae68b22873e5e2af406fd1547b5f to your computer and use it in GitHub Desktop.
Train a two-tower model using the MovieLens 100K dataset
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import torch | |
| import pandas | |
| class TT(torch.nn.Module): | |
| def __init__(self, n_user, n_item): | |
| super(TT, self).__init__() | |
| # The dimensionality of embedding vectors 32 is from | |
| #https://towardsdatascience.com/movielens-1m-deep-dive-part-ii-tensorflow-recommenders-4ca358cc886e | |
| emb_dim = 128 | |
| self.u = torch.nn.Embedding(n_user, emb_dim) | |
| self.v = torch.nn.Linear(emb_dim, n_item, bias = False) | |
| def forward(self, users: torch.Tensor) -> torch.Tensor: | |
| assert users.dtype == torch.long | |
| uembs = self.u(users) | |
| return self.v(uembs) | |
| def test_tt(): | |
| n_users, n_items, mbsize = 5, 10, 2 | |
| m = TT(n_users, n_items) | |
| users = torch.empty(mbsize, dtype=torch.long).random_(n_users) | |
| assert m(users).shape == torch.Size([mbsize, n_items]) | |
| df = pandas.read_csv("u.data.reword") | |
| users = torch.tensor(df['user'].values) | |
| items = torch.tensor(df['item'].values) | |
| ds = torch.utils.data.TensorDataset(users, items) | |
| n_user = df['user'].max() + 1 | |
| n_item = df['item'].max() + 1 | |
| m = TT(n_user, n_item) | |
| cel = torch.nn.CrossEntropyLoss() | |
| opt = torch.optim.Adam(m.parameters(), lr=0.001) | |
| mbsize = 32 | |
| for epoch in range(50): | |
| dl = torch.utils.data.DataLoader(ds, shuffle=True, batch_size=128) | |
| for users, items in dl: | |
| opt.zero_grad() | |
| loss = cel(m(users), items) | |
| loss.backward() | |
| opt.step() | |
| print(f"{loss}") | |
| torch.save(m.u.weight, "u.weight") | |
| torch.save(m.v.weight, "v.weight") |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
The input data was generated by this program https://gist.github.com/wangkuiyi/edb8870d30dc6b639bb3ae1384e8aa12
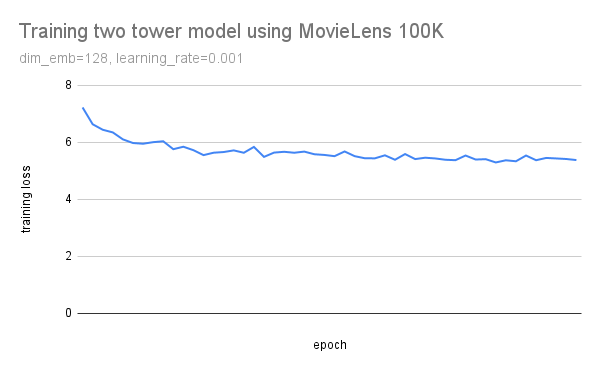
The training curve plotted using Google Sheet is as the following: