- 在线应用都需要对
用户是否有权限对某个数字对象进行操作实现权限检查和控制。例如云照片应用可以允许用户共享部分照片给好友,但是同时保持部分照片是私密的。此处有权限控制的三要素:- 用户,或者称为操作者
- 权限,或者称为动作
- 对象,或者称为被操作者
- 通常这些权限管理都由应用本身实现,Zanzibar提供了另外一种方式,实现了
中心化的权限管理,你也可以理解为Zanzibar是谷歌所有在线服务的权限管理中心。 - 这种中心化的权限管理方式,比起由应用自身各自实现的方式,有以下的优点:
- 它提供了跨应用的一致的权限语义和用户体验。
- 它提升了跨应用间的互操作能力,例如,当你将一个应用的
对象嵌入到另一个应用的对象中时。 - 可以使用中心化的权限管理来提供一致的弹性的基础设施资源。
- 可以去除所有应用的权限管理重复开发部分,将应用开发的业务逻辑和权限管理逻辑分离。
- Zanzibar的设计目标:
- 正确性(作为权限控制的必须保障)
- 灵活性,能够支持广泛的应用以及不同的权限控制方法。
- 低延迟,作为访问的必经途径(甚至是入口),必须提供迅速的响应。
- 高可用,作为所有应用依赖的基础服务,应该具备极高的可用性。
- 大规模,它能够支撑数十亿的用户对数十亿对象的操作。
- 为了提供灵活性,Zanzibar设计了一套配置语言,这套语言允许客户端定义用户和对象之间的任意关系,例如所有者owner,编辑者editor,评论者commenter和查阅者viewer。它还提供了一系列的集合代数运算如交集和并集,用于实现用户和对象之间更加复杂的关系。例如在线文档应用可以赋予所有具有编辑者权限的用户具有评论者权限,但是评论者中不一定全部都具有编辑者权限。
- 在运行过程中,Zanzibar允许客户端通过远程进程调用RPC来对访问控制列表ACL进行创建、修改和查询。一个简单的ACL可以理解为“用户U和对象O有着关系R”,更加复杂的ACL可以是“用户组S和对象O有着关系R”,因为S实际上可以是另外的一个ACL,所以整个列表可以构成复杂的结构。例如,“对某个视频有着观看权限的用户(S)对同样的视频有着评论的权限”。
- 权限检查可以被简单的描述为“用户U和对象O之间是否具有关系R”,这个检查会在一个分布式的服务器中进行,例如,当检查一个嵌套的用户组S时,可以使用不同的服务器来递归查询不同层次的用户组关系。
- Zanzibar可以沿着多个维度进行全局权限检查,它存储了超过200亿条ACL,并且能在每秒进行超过1百万次查询。
- Zanzibar中的ACL记录没有进行地理位置分布存储,而是将全局ACL数据同步到所有的地理位置数据中心上,因为应用可能需要在任何地理位置上进行权限检查。
- Zanzibar通过两个有关联的特性来实现全球一致性的权限控制(全球强一致性保证):
- 它保留了ACL数据提交到底层存储的顺序。
- 它能保证任何权限检查结果都不会早于客户端对相关记录提交的更新。
- 低延迟性的实现,因为所有的ACL记录都是整体分布式存储的,因此避免了多数据中心的传输的回路延迟。同时还使用了以下技术:
- 缓存技术记录查询的最终和中间结果的热点数据。
- 对短暂时段的相同查询进行去重。
- 在深度嵌套集合中查询中采用对冲请求和计算优化技术进一步减少延迟(尾延迟)。通过这些技术,Zanzibar在运行的三年中可以达到95%的权限检查延迟在10ms以内,并且提供了5个9的可用性。
Zanzibar的ACL中用户和对象的关系是一个关系元组。用户组可以表达称为另一个ACL,使用从属关系的原语来表达。下面是关系元组的基本定义:
<tuple> ::= <object>'#'<relationi>'@'<user><object> ::= <namespace>':'<object id><user> ::= <user id> | <userset><userset> ::= <object>'#'<relation>
上面的<namespace>和<relation>是有客户端预先定义的,<object id>是一个字符串,<user id>是一个整数。一个关系元组的主键包括<namespace>,<object id>,<relation>和<user>。上面的<userset>是用户组,他同样也是一个关系元组,用于多层嵌套ACL。
通过使用关系元组而不是对每个对象定义ACL,可以提供灵活的权限控制管理,并且支持高效的读取和递进的更新。下表是一些元组的例子:
| 元组的字符串表达 | 语义 |
|---|---|
| doc:readme#owner@10 | 用户ID10是对象doc:readme的所有者 |
| group:eng#member@11 | 用户ID11是对象group:eng的成员 |
| doc:readme#viewer@group:eng#member | 对象group:eng的成员是对象doc:readme的浏览者 |
| doc:readme#parent@folder:A#... | 对象doc:readme处于目录folder:A中 |
本小节主要针对全球分布式的一致性,对于小型系统应用可以忽略。但是建议阅读原论文,对谷歌的分布式技术会有更深入的理解。当然也是因为谷歌本身有一个全球一致性的数据库Spanner。
下面是一个简单的命名空间配置:
name: "doc"
relation { name: "owner" }
relation {
name: "editor"
userset_rewrite {
union {
child { _this {} }
child { computed_userset { relation: "owner" } }
} } }
relation {
name: "viewer"
userset_rewrite {
union {
child { _this {} }
child { computed_userset { relation: "editor" } }
child { tuple_to_userset {
tupleset { relation: "parent" }
computed_userset {
object: $TUPLE_USERSET_OBJECT # parent folder
relation: "viewer"
} } }
} } }
有三种关系,分别是owner,editor和viewer。用户组重写即userset_rewrite,从上面的例子看出有三种可能取值:
- _this: 代表返回所有根据
<object>#<relation>关系对取得的用户,包括那些间接在嵌套ACL中定义的用户。如果没有定义userset_rewrite,这个会是默认值。 - computed_userset: 对某个对象计算后得到的用户组。例如
computed_userset { relation: "owner" }表示计算该对象的所有者。 - tuple_to_userset: 对某个对象计算后得到的关系元组。然后对取得的每个关系元组再计算
computed_userset。
上述取值可以再进行集合运算,例如上面的union,表示所有里面的child的并集。因此viewer关系的用户组重写值为:
- 所有直接定义为
viewer的用户,即例子中的child { _this {} }。 - 所有经过计算得到的对象的
editor的用户,即例子中的child { computed_userset { relation: "editor" } }。 - 对目标对象计算
parent关系得到的元组,然后计算元组中目标对象的viewer关系得到的用户。即例子中最后一个child的内容。
除了支持ACL检查,Zanzibar还支持客户端读写关系元组,监视元组修改和检查所有有效的元组。
可以依据下面的条件读取ACL元组集:
- 元组的ID集合。
- 目标对象object_id。
- 用户组userset。
- 可在目标对象或用户组上增加关系作为额外的约束条件。
需要注意的是,这里的读API返回的ACL元组集不包括所有计算得到的ACL,例如:上面例子中viewer是包括editor的,但是读取的时候不额外计算并返回。
客户端可以对一条ACL元组进行修改或删除,也可以对一个目标对象所有的ACL元组集进行修改或删除,多个写操作的步骤如下:
- 首先根据object_id读取所有的ACL元组集,包括目标对象的
lock关系元组。 - 然后产生需要修改或删除的元组集,提交写操作,附带目标对象的
lock关系元组。Zanzibar会检查当前lock关系元组是否在读取之后发生了修改,如果发生了修改,则不会提交写操作。 - 如果写入不成功,返回第一步。
一个应用客户端可能需要维护一份ACL元组集的副本,但是需要在这些元组集发生更改时获得通知。监视的颗粒度是命名空间,当一个命名空间的ACL元组集发生更改时,监视的客户端会收到通知。
检查API返回的是一个用户组userset,查询条件是<object>#<relation>。
扩展API用来查询对于某个<object>#<relation>的条件,所有有效的用户组userset。也就是在读API的基础上,还需要计算所有computed_userset和tuple_to_userset的集合,并按照命名空间配置的集合运算得到最终用户组。
Zanzibar架构图:
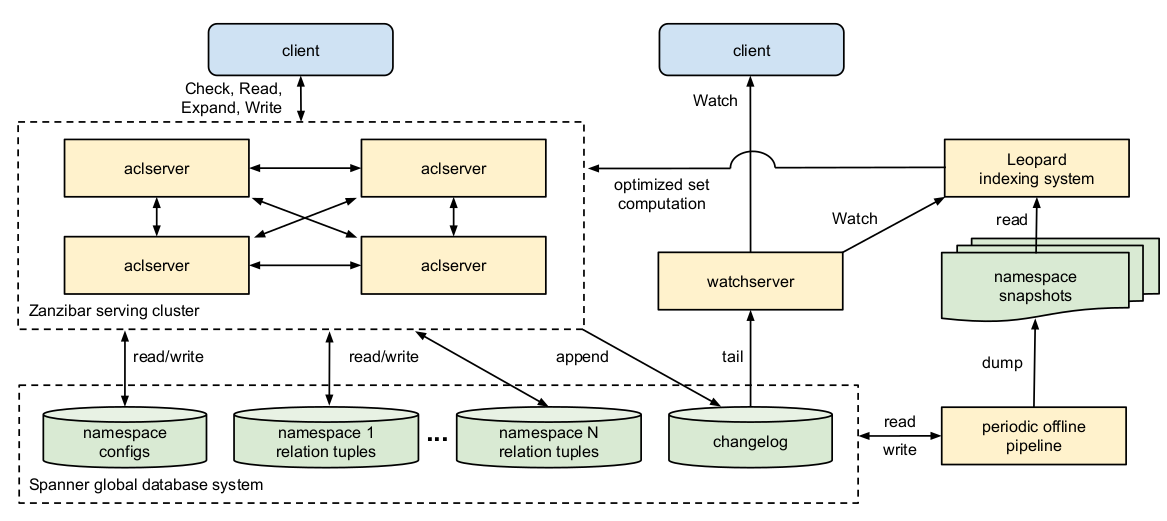
- aclserver: Zanzibar最主要的服务,提供读写检查和扩展API。请求可以发送到集群中任何一台aclserver上,该服务会根据需要将请求分解然后请求集群的其他aclserver帮助完成中间结果运算,最终结果会由收到客户端请求的aclserver进行整合并返回。
- Zanzibar将所有的ACL元组数据存储在谷歌的Spanner全球一致性数据库中。每个命名空间对应一个独立的Database,然后用一个独立的Database来存储所有命名空间的配置,还用一个独立的changelog database来存储所有命名空间的变更记录。
- watchserver: 用来响应监视请求的服务。它每次获取changelog中最新提交的内容,然后根据需要以近似实时的方式通知客户端。
- Zanzibar会使用离线的任务来对数据进行快照,以及根据每个命名空间的配置来对过期的ACL元组进行清理。
- Leopard索引系统用来优化深度和大数据量的嵌套集合运算。
- 关系元组存储:每个命名空间中的关系元组存储在一个独立的Database中。每条元组记录的主键为(分片ID,对象ID,关系,用户,提交时间戳),一个ACL元组可能会存在多个版本,存储为数据库中的多条记录。分片ID通常可以使用对象ID直接运算获得,在某些复杂和大数据量的情况下,也可以通过对象ID和用户共同运算获得。主键的顺序允许我们在查询
<object>#<relation>时,可以使用索引进行快速的查询。 - 更改记录:Zanzibar使用一个独立的database来记录所有命名空间的ACL元组修改记录,并提供给监视API使用。每个写操作都会在一个事务中同时提交给元组存储数据库和更改记录数据库。
- 命名空间配置存储:命名空间配置数据库中有两张表,一张存储所有命名空间的配置,主键是命名空间ID,另一张存储所有命名空间配置的变更记录。
- 副本:为了缩短延迟,所有的数据库都会在客户端就近的地理位置上存储副本。
本小节主要与Zanzibar要实现全球一致性相关,略过。可参看原论文3.2.1节。
本小节主要与Zanzibar要实现全球一致性相关,略过。可参看原论文3.2.2节。
在不考虑用户组重写配置的情况下,简单的检查运算如下:
CHECK (U, <object#relation>) =
∃ tuple <object#relation@U>
∨ ∃ tuple <object#relation@U'>, where
U' = <object'#relation'> s.t. CHECK (U, U').
上式中的U' = <object'#relation'>涉及到查找所有间接的ACL元组,因此上面是一个递归的定义。当关系元组的层级很深或者范围很广时,这将会是一个非常昂贵的计算。而同样,用户组重写的配置也可以按照上述方式描述计算,并使用集合运算得到最终结果。
Zanzibar使用并行的计算方式来获得所有叶子节点的检查结果,当某个aclserver发现后续需要的叶子节点计算已经被分派到其他server上运行时,该计算就会取消。
Zanzibar还会使用缓存来减少叶子节点检查直接访问Spanner数据库的次数,进一步缩短延迟。
如果ACL元组的嵌套层次很多(很深),或者其子节点数量很多(很广),那么使用aclserver来提供检查结果将会是一个很大延迟的实时计算。因此Zanzibar使用了一个特殊的索引系统Leopard来处理这种情况。
Leopard索引系统使用一个(T, s, e)元组的集合来索引整个ACL元组树,其中T是表示集合类型的枚举量,s和e是两个64位整数表示集合ID和元素ID。因此一个查询就可以表示位按照这些索引元组查到的元素(ACL记录)的有序(按照元素ID排序)集合,并且能够使用交集,并集,差集运算计算得到最终结果,查询时也可以指定结果集合的大小。
为了表示ACL层级结构,Zanzibar将T表示为两种不同类型:
- GROUP2GROUP(s) -> {e}: 表示所有直接或间接的父级为s的元素集合。
- MEMBER2GROUP(s) -> {e}: s表示一个独立的用户,而e表示所有该用户的直接父级元素集合。
例如,检查一个用户U是否从属与某个组G,其数学描述为:
(MEMBER2GROUP(U) ∩ GROUP2GROUP(G)) ≠ ∅
简单来说,成员关系检查实际上转换为一个图Graph上的路径可达问题。图上的节点表示组或者用户,边表示直接的从属关系。Leopard的做法就是将图中可达的路径都转换为铺平后的索引,因此能够大大提升查询的效率。
Leopard服务分为三个大模块:
- 一个实时查询模块,可以迅速检查权限关系。
- 一个离线的索引创建模块,可以将初始化数据库中的ACL元组集转换成索引。
- 一个实时的索引更新模块,可以在ACL元组集更新同时更新索引。
索引后的元组保存在Leopard中一个有序的列表中,这些列表通过元素ID进行分片,因此也是分布式计算方式。通常存储在内存当中,也可以根据需要将冷热索引分开存储在不同访问位置。
离线的索引创建通过读API访问ACL元组数据快照生成索引,实时更新通过监视API从watchserver获得最新的更改日志,然后修正索引内容。
后面还有几个及其细化的优化细节,这里不记录,请参考原论文。
原理部分基本如上所述,理解完基本就可以照样实现一个类似的系统了。论文后续部分还有一些非常工程化的内容,比如缓存的处理、尾延迟的抑制、客户端性能隔离,强烈建议有条件阅读原论文,会获益匪浅。
后续的章节基本就是3年来Zanzibar的表现数据,这里就不做记录了。