Elixir における並行性と並列性
https://exercism.io/blog/concurrency-parallelism-in-elixir
This is the second part of Percy Grunwald's series on Elixir. Don't miss out on the first article on Unicode matching in Elixir.
Exercises on Exercism are small, synthetic, and often seemingly trivial. It’s easy to imagine that experienced practitioners would have nothing to learn from them. However, solving these synthetic problems can push you to learn and apply parts of your language that you may not have explored. This new learning can lead you to solve real-world problems more efficiently or more expressively.
Parallel Letter Frequency is a medium difficulty exercise on Exercism's Elixir Trackthat unpacks a surprising number of interesting lessons. To solve this problem successfully your solution should execute in parallel in multiple worker processes. Achieving true parallelism in Elixir is surprisingly easy compared to other languages, but if you've never written concurrent code in Elixir, it may seem a little daunting. One of the things you'll discover in solving this exercise is how easy Elixir makes it to write code that can execute concurrently or in parallel. Applying these skills to your code can have a significant impact on the performance of your applications.
This exercise requires you to implement a function, Frequency.frequency/2, that determines the letter frequency in a list of strings. The calculation should be carried out in several worker processes, set by the workers argument:
運動に関するエクササイズは、小さく、総合的で、そしてしばしば一見些細なことです。経験豊富な実務家が彼らから学ぶことは何もないだろうと想像するのは簡単です。しかしながら、これらの総合的な問題を解決することはあなたがあなたが探求しなかったかもしれないあなたの言語の部分を学びそして適用するようにあなたを推し進めることができます。この新しい学習により、実社会の問題をより効率的にまたはより表現力豊かに解決することができます。
Parallel Letter FrequencyはExercismのElixir Trackに関する中程度の難易度の練習で、驚くべき数の興味深いレッスンをアンパックします。この問題をうまく解決するために、あなたのソリューションは複数のワーカープロセスで並行して実行するべきです。 Elixirで真の並列処理を達成することは、他の言語と比較して驚くほど簡単ですが、Elixirで並行コードを書いたことがない場合、それは少し困難なように思われるかもしれません。この課題を解決する上であなたが発見することの1つは、Elixirが同時または並列に実行できるコードを書くのをいかに簡単にするかということです。これらのスキルをコードに適用すると、アプリケーションのパフォーマンスに大きな影響を与える可能性があります。
この課題では、文字列のリスト中の文字の出現頻度を決定する関数 Frequency.frequency / 2を実装する必要があります。計算は、 workers引数によって設定されたいくつかのワーカープロセスで実行されるべきです。
iex> Frequency.frequency(["Freude", "schöner", "Götterfunken"], workers)
%{
"c" => 1,
"d" => 1,
"e" => 5,
...
"ö" => 2
}
In this post, we'll explore concurrency in Elixir by making a working sequential solution to this exercise concurrent. However, before we jump into the code, let's take a moment to examine what "concurrency" and "parallelism" actually mean, and how to achieve both in Elixir vs. other languages.
この記事では、Elixirでの並行性について、この演習の実用的な順次解決策を並行して検討します。 しかし、コードに飛び込む前に、「並行性」と「並列性」が実際に何を意味するのか、そしてElixirと他の言語の両方でどのように達成するかを検討しましょう。
Concurrency and parallelism are related terms but don't mean precisely the same thing. A concurrent program is one where multiple tasks can be "in progress," but at any single point in time, only one task is executing on the CPU (e.g., executing one task while another is waiting for IO such as reading or writing to the disk or a network). On the other hand, a parallel program is capable of executing multiple tasks at the same time on multiple CPU cores.
Both concurrent and parallel execution can give significant speed increases, but the amount of speedup possible -- if any -- is dependent on many factors. There are cases in which concurrency or parallelism are not even possible; it may be that the task you're trying to complete doesn't lend itself to either concurrent or parallel execution, or that the runtime doesn't support them. If your case does allow for concurrent or parallel execution, the amount of speedup possible is largely dependent on whether the task is IO- or CPU-bound, and whether there is more than 1 CPU core available.
Despite the number of contributing factors, there are a few "rules of thumb" for determining whether concurrency or parallelism is possible and how much speedup to expect. Firstly, concurrent execution is possible on a single CPU core, but parallel execution is not. Secondly, parallelism and concurrency should give significant speedup to IO-bound tasks, and the speedup should be nominally the same for both. Finally, CPU-bound tasks should have the same (or slower) performance when executed concurrently and generally speed increases are only possible when executed in parallel across multiple CPU cores.
The letter frequency calculation in this exercise is an example of a CPU-bound task, so according to rules of thumb above, a speed increase should only be possible by doing the calculation in parallel on multiple CPU cores.
並行性と並列性は関連用語ですが、まったく同じ意味ではありません。並行プログラムとは、複数のタスクを「進行中」にすることができるプログラムですが、どの時点でもCPU上で1つのタスクしか実行されていません(たとえば、タスクの読み取りまたは書き込みなどのIOの待機中に1つのタスクを実行)。ディスクまたはネットワーク)。一方、並列プログラムは、複数のCPUコア上で複数のタスクを同時に実行することができます。
同時実行と並列実行の両方で速度が大幅に向上する可能性がありますが、可能な限りの高速化の量は、あるとしても多くの要因に左右されます。並行性や並列処理が不可能な場合もあります。実行しようとしているタスクが、同時実行または並列実行のどちらにも適していないか、ランタイムがそれらをサポートしていない可能性があります。あなたのケースが同時または並列実行を可能にするならば、可能なスピードアップの量はタスクがIOまたはCPUバウンドであるかどうか、そして利用可能なCPUコアが2つ以上あるかどうかに大きく依存します。
寄与する要素の数にもかかわらず、同時実行または並列処理が可能かどうか、そしてどれだけ高速化が期待できるかを判断するための「経験則」がいくつかあります。まず、単一のCPUコアで同時実行が可能ですが、並列実行はできません。第二に、並列処理と並行処理は、IOに関連したタスクを大幅にスピードアップするはずであり、そのスピードアップは両方とも公称上同じであるべきです。最後に、CPUにバインドされたタスクは、同時に実行されたときに同じ(または遅い)パフォーマンスを持つべきであり、一般的に速度の向上は複数のCPUコアにまたがって並列に実行されたときにのみ可能です。
この演習での文字頻度の計算は、CPUにバインドされたタスクの一例です。したがって、上記の経験則によれば、速度の向上は、複数のCPUコアで並列に計算することによってのみ可能になります。
Many popular languages give you tools to write concurrent code, but achieving parallelism is usually much more complex and full of trade-offs.
For example, concurrency is a first class citizen in JavaScript running on the Node.js runtime, and the default versions of IO-related functions are almost always "asynchronous" (i.e., concurrent). For example, [**fs.ReadFile**](http://nodejs.org/api/fs.html#fs_fs_readfile_path_options_callback) is a concurrent function and the standard way to read the contents of a file. This is great but also has its downsides in the form of callback hell, or the need for Promises. Also, since Node doesn't schedule CPU time equally across tasks, it's still possible to block execution with a single CPU-intensive task. Parallelizing execution in Node is possible, but certainly not easy. Given that Node is single threaded, the only way to achieve parallelism is to manually fork worker processes with the [**cluster**](https://nodejs.org/api/cluster.html) module or run multiple instances of your program and manually implement communication between them.
Python, unlike Node, is not concurrent by default but does give you multiple tools for writing concurrent and parallel code. However, each option has trade-offs and choosing one is not necessarily straightforward. You could use the [**threading**](https://docs.python.org/3/library/threading.html)module and deal with the fact that the [**global interpreter lock (GIL)**](https://docs.python.org/3/glossary.html#term-global-interpreter-lock) limits execution to a single thread at a time, making parallelism impossible. The other option is Python's [**multiprocessing**](https://docs.python.org/3/library/multiprocessing.html) module, which bypasses the GIL limitation by spawning OS processes (as opposed to threads). Using multiprocessing makes parallelism possible but has the trade-off that OS processes are slower to spawn and use more memory than threads.
Writing concurrent and parallel code in Elixir is much simpler since Elixir is concurrent at the runtime level. Elixir's reputation for massive scalability comes from the fact that it runs on the BEAM virtual machine, which executes all code inside extremely lightweight "processes" that all run concurrently within the VM. BEAM processes have negligible cost to spawn and use minute amounts of memory compared to the OS-level threads and processes spawned by Python's concurrency modules. Also, in contrast to Node's event loop, the BEAM VM has schedulers that allocate available CPU time to all processes, which ensures that a single CPU-intensive task can't block other processes from executing.
Because of this architecture, going from executing processes concurrently to executing in parallel is just a matter of adding more CPU cores. In fact, for many years now BEAM automatically activates Symmetric Multiprocessing (SMP) capabilities on multi-core systems, which allows the VM's schedulers to allocate CPU time from all cores to the running processes. In Elixir, not only is concurrency a first class citizen, but there is no distinction between concurrent and parallel code. All you need to do is write concurrent code and the VM will automatically and by default parallelize it if there is more than 1 CPU core available.
多くの一般的な言語では、並行コードを作成するためのツールが用意されていますが、並列処理を達成することは、通常、はるかに複雑でトレードオフがいっぱいです。
例えば、並行性は、Node.jsランタイム上で実行されるJavaScriptの第一級の市民であり、IO関連関数のデフォルトバージョンは、ほとんど常に「非同期」(すなわち、並行)です。例えば、 fs.ReadFileは並行関数であり、ファイルの内容を読むための標準的な方法です。これは素晴らしいことですが、コールバック地獄のような欠点、またはPromiseの必要性もあります。また、Nodeはタスク間で均等にCPU時間をスケジュールしないため、単一のCPU集中タスクで実行をブロックすることは依然として可能です。 Nodeで並列実行することは可能ですが、確かに容易ではありません。 Nodeがシングルスレッドであることを考えると、並列処理を達成する唯一の方法は手動で clusterモジュールを使ってワーカープロセスをフォークするか、プログラムの複数のインスタンスを実行してそれらの間の通信を手動で実装することです。
Nodeとは異なり、Pythonはデフォルトでは並列ではありませんが、並列および並列コードを書くための複数のツールを提供します。ただし、各オプションにはトレードオフがあり、選択するのは必ずしも簡単ではありません。 threadingモジュールを使用して、グローバルインタプリタロック(GIL)が一度に実行を単一スレッドに制限し、並列処理を不可能にするという事実に対処することができます。他の選択肢はPythonの multiprocessingモジュールで、これは(スレッドとは対照的に)OSプロセスを生み出すことによってGILの制限を回避します。 multiprocessingを使うことは並列処理を可能にしますが、OSプロセスはスレッドよりも生成とメモリ消費が遅いというトレードオフを持ちます。
Elixirはランタイムレベルで並行しているので、Elixirで並行並行コードを書くのはずっと簡単です。 Elixirの大規模なスケーラビリティに対する評判は、すべてがVM内で同時に実行される非常に軽量な「プロセス」内ですべてのコードを実行するBEAM仮想マシン上で実行されるという事実からきています。 BEAMプロセスは、Pythonの並行処理モジュールによって生み出されるOSレベルのスレッドやプロセスと比較して、わずかな量のメモリを生成して使用するためのごくわずかなコストを持っています。また、ノードのイベントループとは対照的に、BEAM VMにはすべてのプロセスに使用可能なCPU時間を割り当てるスケジューラがあるため、1つのCPUを集中的に使用するタスクが他のプロセスの実行を妨げることはありません。
このアーキテクチャのため、プロセスの同時実行から並列実行への移行は、CPUコアを追加するだけの問題です。実際、何年にもわたってBEAMはマルチコアシステム上でSMP(Symmetric Multiprocessing)機能を自動的に有効にしているため、VMのスケジューラはすべてのコアから実行中のプロセスにCPU時間を割り当てることができます。 Elixirでは、並行性が第一級の市民であるだけでなく、並行コードと並列コードの間に区別はありません。あなたがする必要があるのは並行コードを書くことだけで、利用可能なCPUコアが1つ以上ある場合はVMは自動的にそしてデフォルトでそれを並列化します。
As mentioned above, in Elixir, concurrency is achieved by distributing operations to multiple BEAM processes. You can very easily spawn processes with functions like [**Kernel.spawn_link/1**](https://hexdocs.pm/elixir/Kernel.html#spawn_link/1), but you're much better off using the awesomely powerful abstractions provided by the [**Task**](https://hexdocs.pm/elixir/Task.html) module:
前述のように、Elixirでは、並行処理は複数のBEAMプロセスに操作を分散することによって実現されています。 Kernel.spawn_link / 1のような関数を使ってプロセスを非常に簡単に生成することができますが、Taskモジュールによって提供される非常に強力な抽象化を使うほうがはるかに良いです。
The most common use case for [Task] is to convert sequential code into concurrent code by computing a value asynchronously.
タスク]の最も一般的な使用例は、値を非同期に計算することによってシーケンシャルコードをコンカレントコードに変換することです。
The Task module lets you write unbelievably clean concurrent code in Elixir -- no callback hell and no need for Promises.
For this exercise, [**Task.async_stream/3**](https://hexdocs.pm/elixir/Task.html#async_stream/3) is a great option:
TaskモジュールはElixirで信じられないほどきれいな並行コードを書くことを可能にします - コールバック地獄とPromisesの必要性なし。
この課題のために、 Task.async_stream / 3は素晴らしい選択肢です:
async_stream(enumerable, function, options \\ [])
Task.async_stream/3 returns a stream that runs the given function concurrently on each item in enumerable. By default, the number of processes spawned (workers) is equal to the number of items in enumerable. This gives us a straightforward way to control the level of parallelism with the workers argument (assuming we have enough CPU cores). All we need to do is split the list of letters into the correct number of chunks and use Task.async_stream/3 to process each chunk in a separate worker.
Task.async_stream / 3は、列挙型の各項目で指定された関数を同時に実行するストリームを返します。 デフォルトでは、生成されたプロセス(ワーカー)の数は、列挙可能なアイテムの数と同じです。 これにより、workers引数を使って並列処理のレベルを制御する簡単な方法が得られます(十分なCPUコアがあると仮定して)。 必要なのは、文字のリストを正しい数のチャンクに分割し、Task.async_stream / 3を使用して各チャンクを別々のワーカーで処理することだけです。
Let's start with a working sequential implementation from my solution:
def frequency(texts, _workers) do
texts
|> get_all_graphemes()
|> count_letters()
end
defp get_all_graphemes(texts) do
texts
|> Enum.join()
|> String.graphemes()
end
defp count_letters(graphemes) do
Enum.reduce(graphemes, %{}, fn grapheme, acc ->
if String.match?(grapheme, ~r/^\p{L}$/u) do
downcased_letter = String.downcase(grapheme)
Map.update(acc, downcased_letter, 1, fn count -> count + 1 end)
else
acc
end
end)
end
We can make the implementation above concurrent by doing the following:
- Split up the list of graphemes returned by
get_all_graphemes/1into a number of chunks equal to the number ofworkers - Process each chunk with
count_letters/1in a worker by usingTask.async_stream/3 - Merge the results from each worker into a single result
Here's a diagram of the steps above:
次のようにして、上記の実装を並行処理することができます。
get_all_graphemes / 1によって返される書記素のリストを、` workers 'の数と等しい数のチャンクに分割します。Task.async_stream / 3を使ってワーカーでcount_letters / 1で各チャンクを処理する- 3.各作業者の結果を単一の結果にマージする
これが上記のステップの図です。
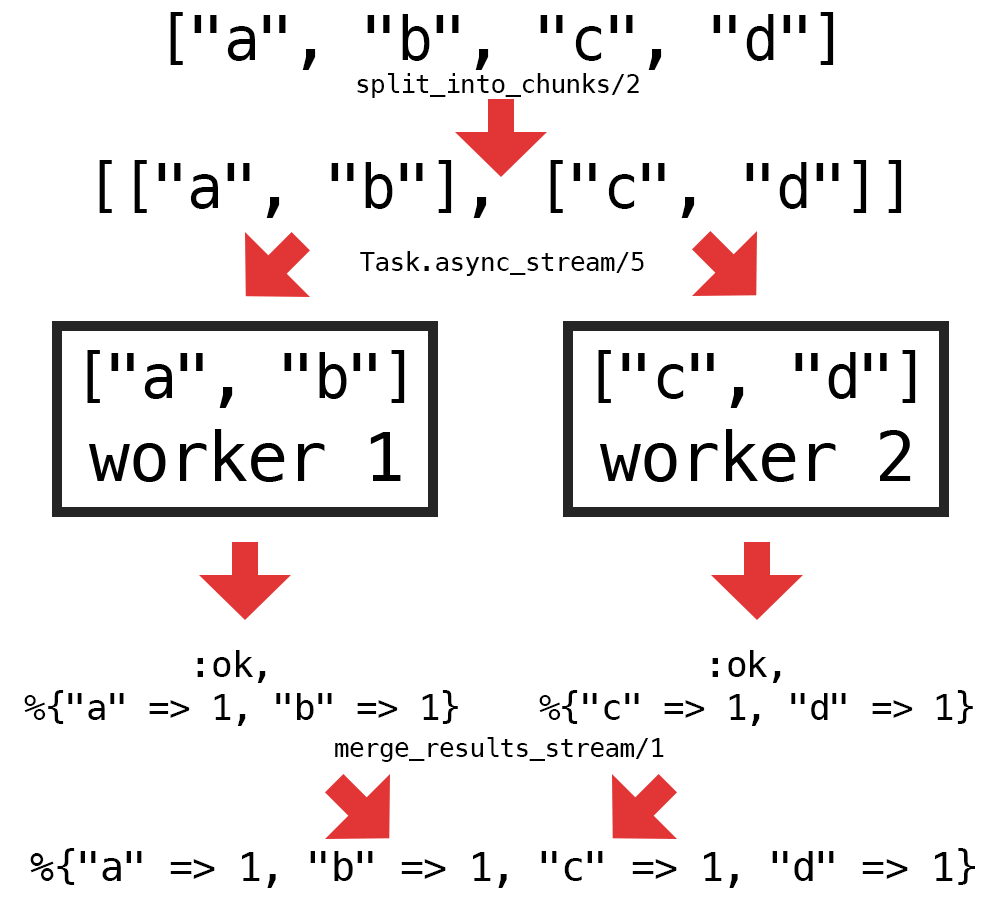
We only need to implement 2 new helper functions to enable the concurrent logic: one to split the graphemes into chunks (split_into_chunks/2) and one to merge the stream of results from the workers (merge_results/1). Here's one way to implement those helpers:
並行ロジックを有効にするには、2つの新しいヘルパー関数を実装するだけです。1つは書記素をチャンクに分割する(split_into_chunks / 2)、もう1つはワーカーからの結果のストリームをマージする(merge_results / 1)です。 これらのヘルパーを実装する1つの方法があります。
defp split_into_chunks(all_graphemes, num_chunks) do
all_graphemes_count = Enum.count(all_graphemes)
graphemes_per_chunk = :erlang.ceil(all_graphemes_count / num_chunks)
Enum.chunk_every(all_graphemes, graphemes_per_chunk)
end
defp merge_results_stream(results_stream) do
Enum.reduce(results_stream, %{}, fn {:ok, worker_result}, acc ->
Map.merge(acc, worker_result, fn _key, acc_val, worker_val ->
acc_val + worker_val
end)
end)
end
With those 2 functions implemented, all that's left to do to make the frequency/2function run concurrently is to add calls to the new helper functions and replace the direct call to count_letters/1 with Task.async_stream/3:
これら2つの関数が実装されているので、frequency / 2関数を同時に実行するために必要なのは、新しいヘルパー関数への呼び出しを追加し、count_letters / 1への直接呼び出しをTask.async_stream / 3に置き換えることだけです。
def frequency(texts, workers) do
texts
|> get_all_graphemes()
|> split_into_chunks(workers)
|> Task.async_stream(&count_letters/1)
|> merge_results_stream()
end
The function above is a fully working concurrent implementation and passes all the tests. Despite being concurrent, the code reads exactly like regular sequential code, which demonstrates the power of the abstractions provided in Task.
上記の関数は完全に機能する並行実装であり、すべてのテストに合格します。 並行していても、コードは通常の順次コードとまったく同じように読み取られます。これは、Taskで提供される抽象化の力を示しています。
As I mentioned earlier in the post, there is no distinction between concurrent and parallel code in Elixir. If we set workers to a number greater than 1, and we have more than 1 CPU core available, the BEAM VM automatically parallelizes the execution of the spawned processes.
By default, BEAM starts a scheduler for each (logical) CPU core available. You can check the number of schedulers that BEAM has started with :erlang.system_info/1:
この記事の冒頭で述べたように、Elixirでは並行コードと並列コードの間に違いはありません。 workersを1より大きい数に設定し、利用可能なCPUコアが複数ある場合、BEAM VMは自動的に生成されたプロセスの実行を並列化します。
デフォルトでは、BEAMは利用可能な(論理)CPUコアごとにスケジューラを起動します。 BEAMが起動したスケジューラの数は :erlang.system_info / 1で確認できます。
iex> :erlang.system_info(:schedulers_online)
8
This represents the maximum number of VM processes that can be executing at the same time. Setting workers to a number greater than the number of schedulers does not increase parallelism and may hurt performance.
これは、同時に実行できるVMプロセスの最大数を表します。 ワーカーをスケジューラーの数よりも大きい数に設定しても、並列処理は増えず、パフォーマンスが低下する可能性があります。
Converting the code from sequential to concurrent turns out to be much easier than expected using Elixir's Task module. The concurrent code adds some extra complexity in the splitting of the list of graphemes and combining the worker results, but the end result is surprisingly clean.
Before solving this Exercism problem I had heard about Task, but never used it. After applying it in my solution, I would now consider it an indispensable part of my Elixir toolbox.
You could use this new tool in many ways to try to optimize performance in your applications. Most web applications are IO-bound and would, therefore, benefit from concurrency even if there is only a single CPU core available. One fairly reliable way to speed up a web application is to make HTTP requests concurrently:
コードをシーケンシャルコードからコンカレントコードに変換することは、Elixirの Taskモジュールを使って予想されるよりはるかに簡単であることがわかります。 並行コードにより、書記素のリストの分割とワーカーの結果の結合がさらに複雑になりますが、最終的な結果は驚くほどクリーンです。
この運動問題を解決する前に、私は `タスク 'について聞いたことがありましたが、それを使ったことはありませんでした。 私のソリューションにそれを適用した後、私は今それを私のElixirツールボックスの不可欠な部分と考えます。
この新しいツールをさまざまな方法で使用して、アプリケーションのパフォーマンスを最適化することができます。 ほとんどのWebアプリケーションはIOに制限されているため、単一のCPUコアしか使用できない場合でも、同時実行性の恩恵を受けます。 Webアプリケーションを高速化するためのかなり信頼できる方法の1つは、HTTP要求を同時に行うことです。
def call_apis_async() do
["https://api.example.com/users/123", ...]
|> Task.async_stream(&HTTPoison.get/1)
|> Enum.into([], fn {:ok, res} -> res end)
end
The code above applies [**Task.async_stream/3**](https://hexdocs.pm/elixir/Task.html#async_stream/3) to call all the URLs in the list concurrently, as opposed to waiting for each request to complete before initiating the next, which should give a significant speedup depending on the duration of each request.
上記のコードは、次の要求を開始する前に各要求が完了するのを待つのではなく、リスト内のすべてのURLを同時に呼び出すためにTask.async_stream / 3を適用し、各要求の期間によっては大幅にスピードアップします。