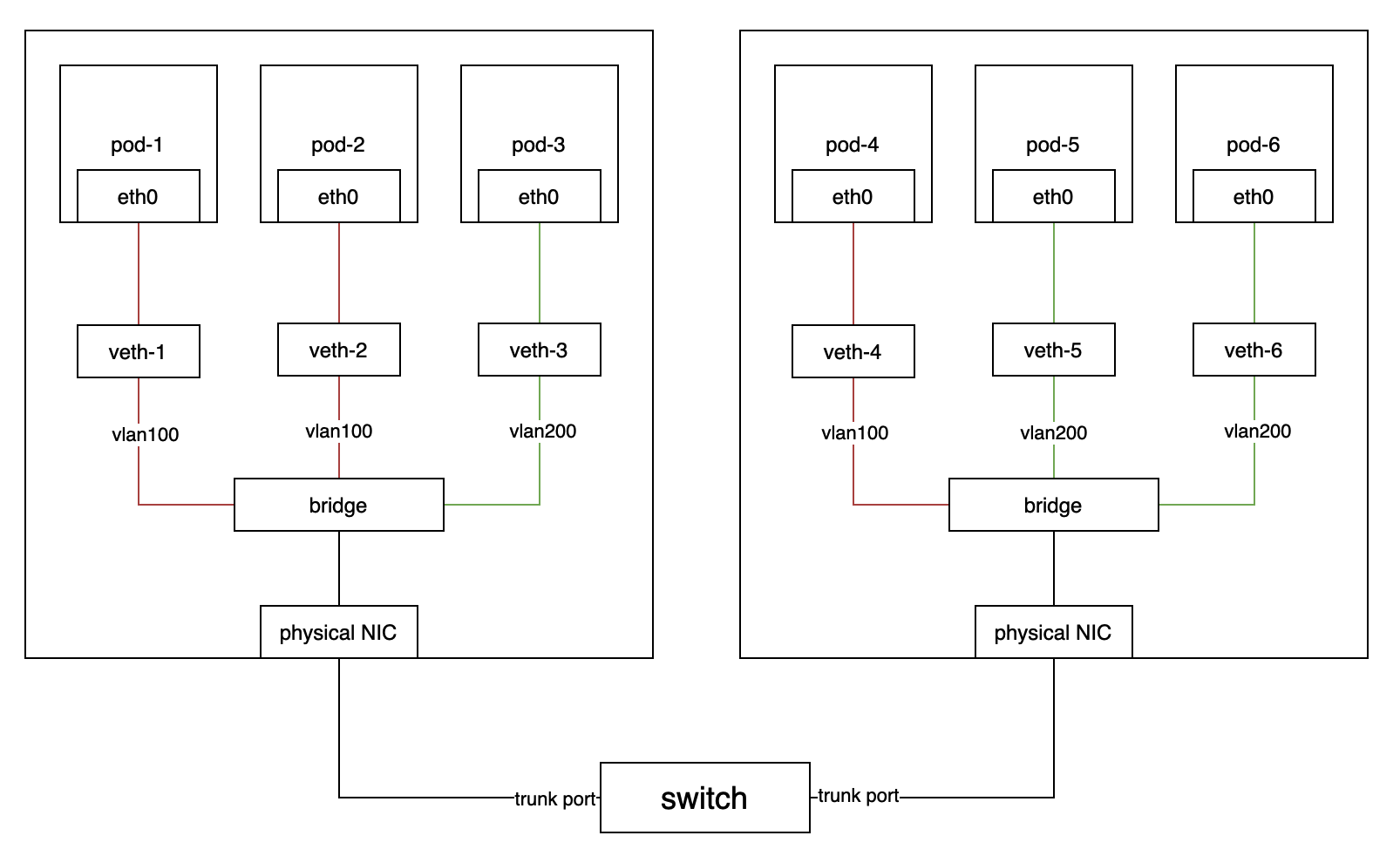
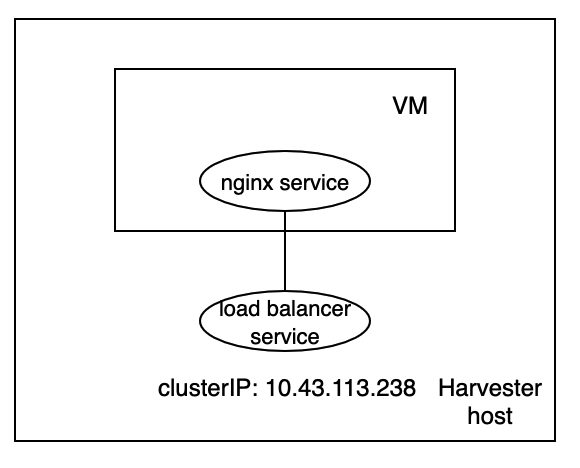
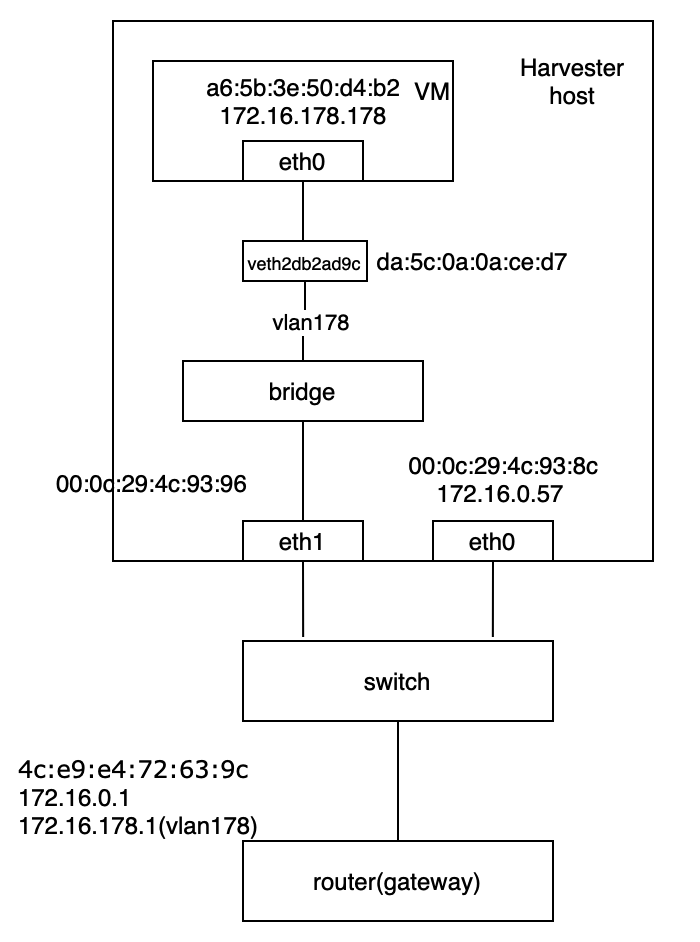
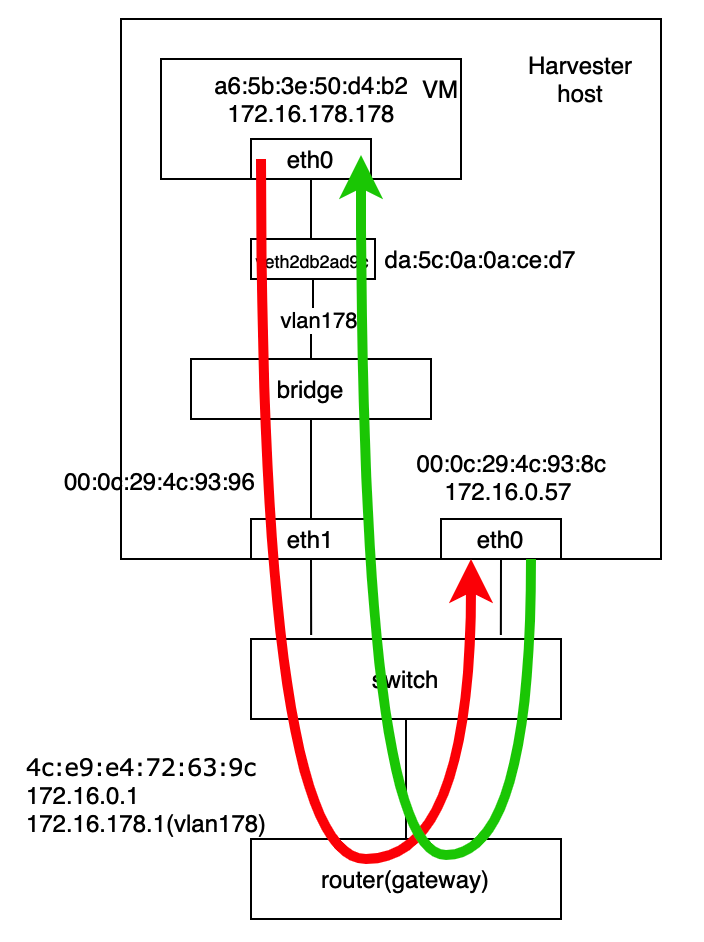
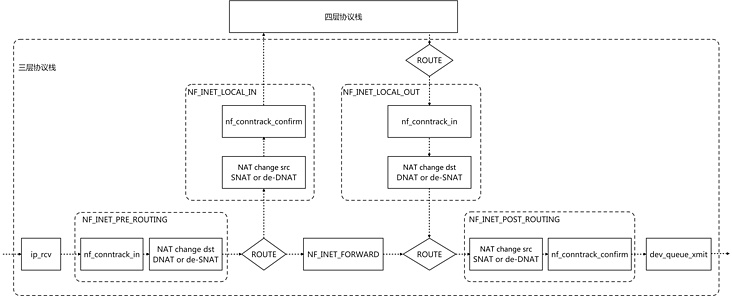
Harvester is an open-source HCI software built on Kubernetes. It's convenient for users to set up a Kubernetes cluster or using the Rancher node driver in Harvester. In this sense, it's logical to make Harvester a cloud provider for Kubernetes. That's the motivation for us to implement a Kubernetes cloud controller manager (CCM) for Harvester like other cloud providers, such as AWS, Openstack and so on.
Currently, users can spin up a Kubernetes through the Harvester node driver, but they can only expose service through nodeport or ingress. Our motivation is to provide a load balancer type of service for the guest cluster.
Issues:
- Harvester should have a fixed VIP for the external node driver.
- Harvester should provide load balancers for the guest clusters constructed by Harvester VMs.
- Develop a CCM for Harvester.
- Use Kube-vip to implement control-plane HA and provide a fixed VIP.
- There are 2 options to implement load balancers.
- Leverage Kubernetes service.
- Use Traefik.
- Develop an out-of-tree CCM.
We will discuss the technical details below.
- We have to add the VIP in TLS cert before setting up Harvester so that the users can access the apiservers. As we know, Harvester is a K3s cluster. According to the K3s Server Configuration Reference, We should set VIP as the value of
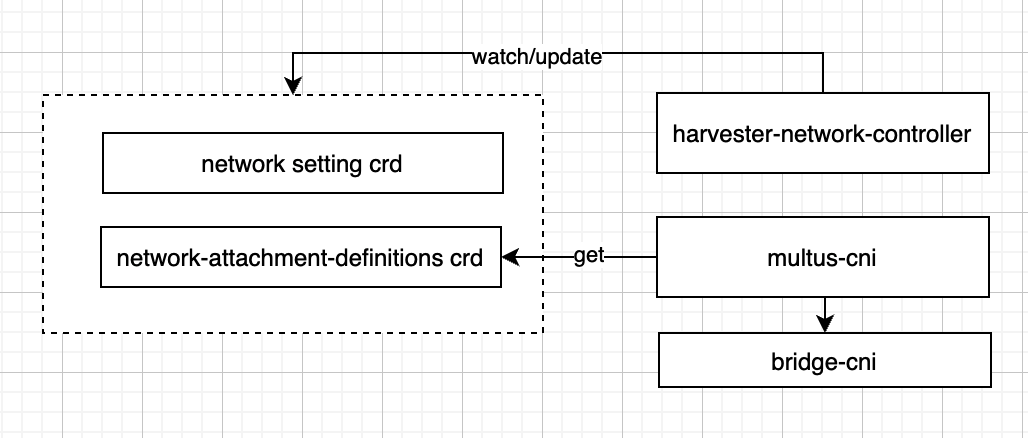
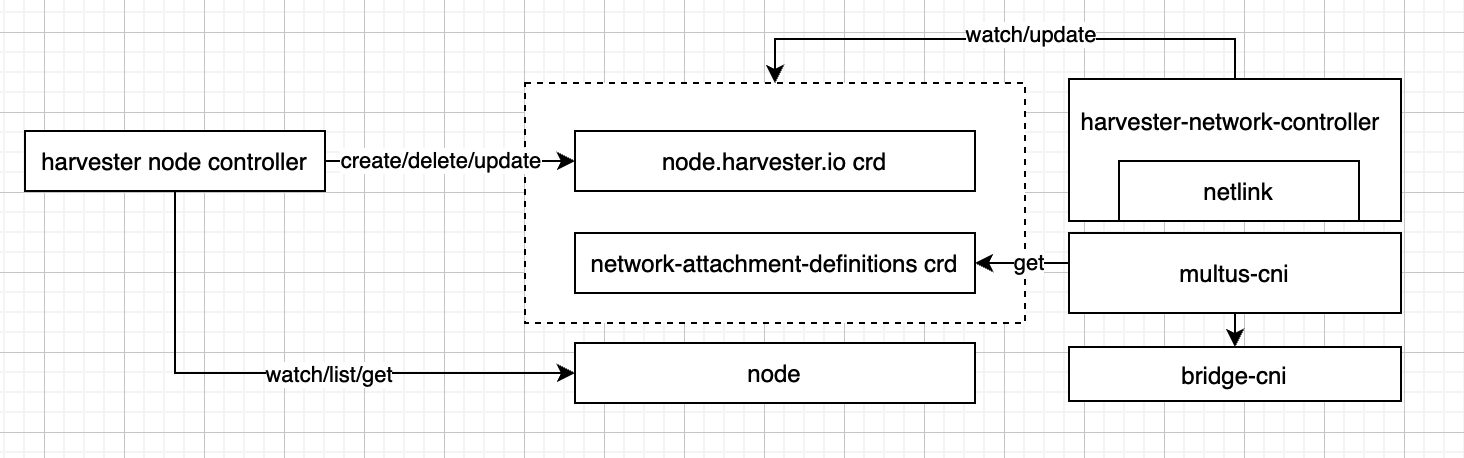
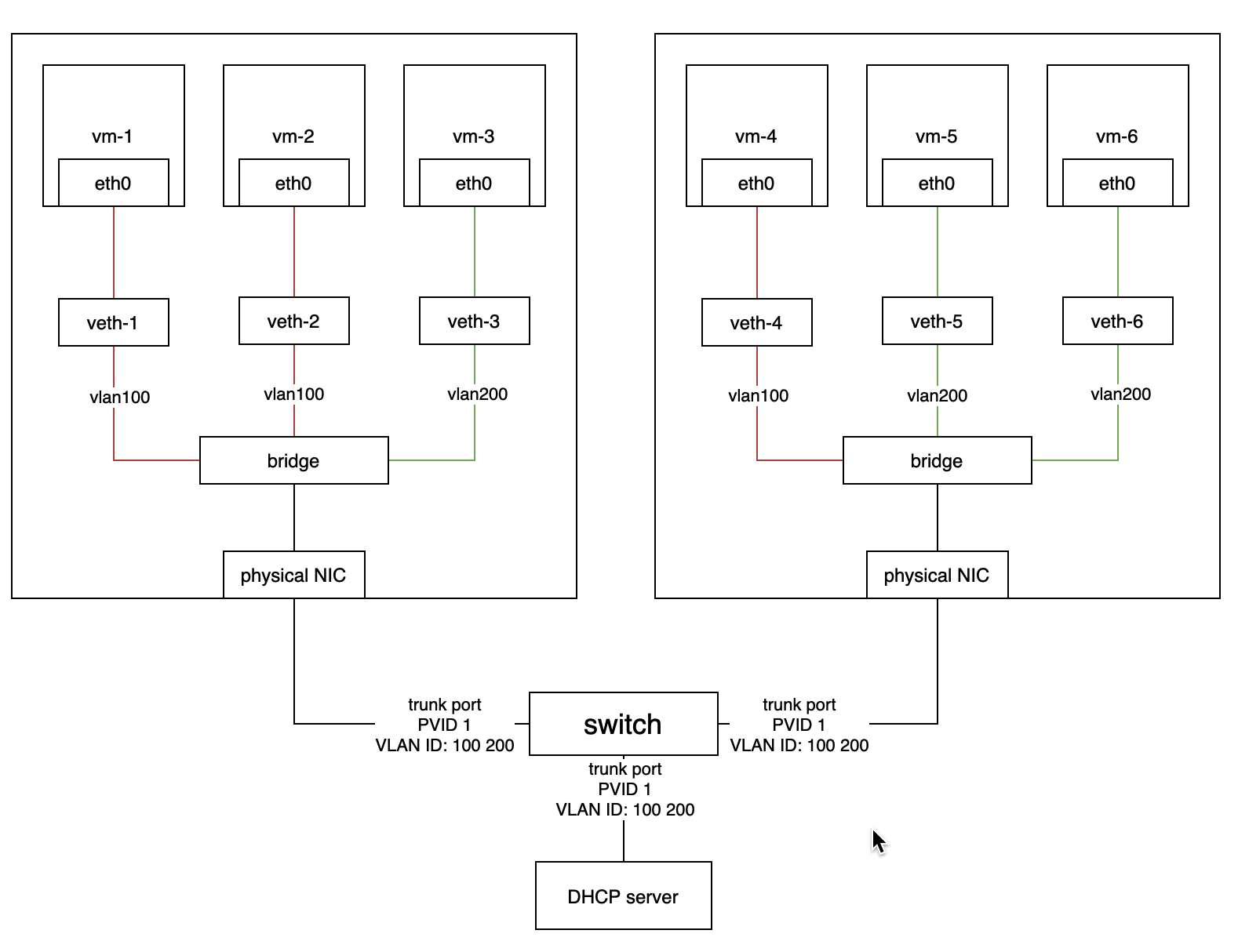
--tls-sanparameter. - Kube-vip will set the VIP as a float IP to the specified network interface. Harvester network controller should consider the float IP when setting up the VLAN network.
- Kube-vip supports two VIP failover mechanisms. They both have limitations.
- Arp mode: single-node bottlenecking and potentially slow failover.
- BGP mode: depend on external routers BGP configuration.
The following two components are required.
- Load Balancer: It's the basic component to forward traffics to the Kubernetes load balancer service.
- Entry: we need an entry to access the service behind the load balancer. Kube-vip is a proper choice.
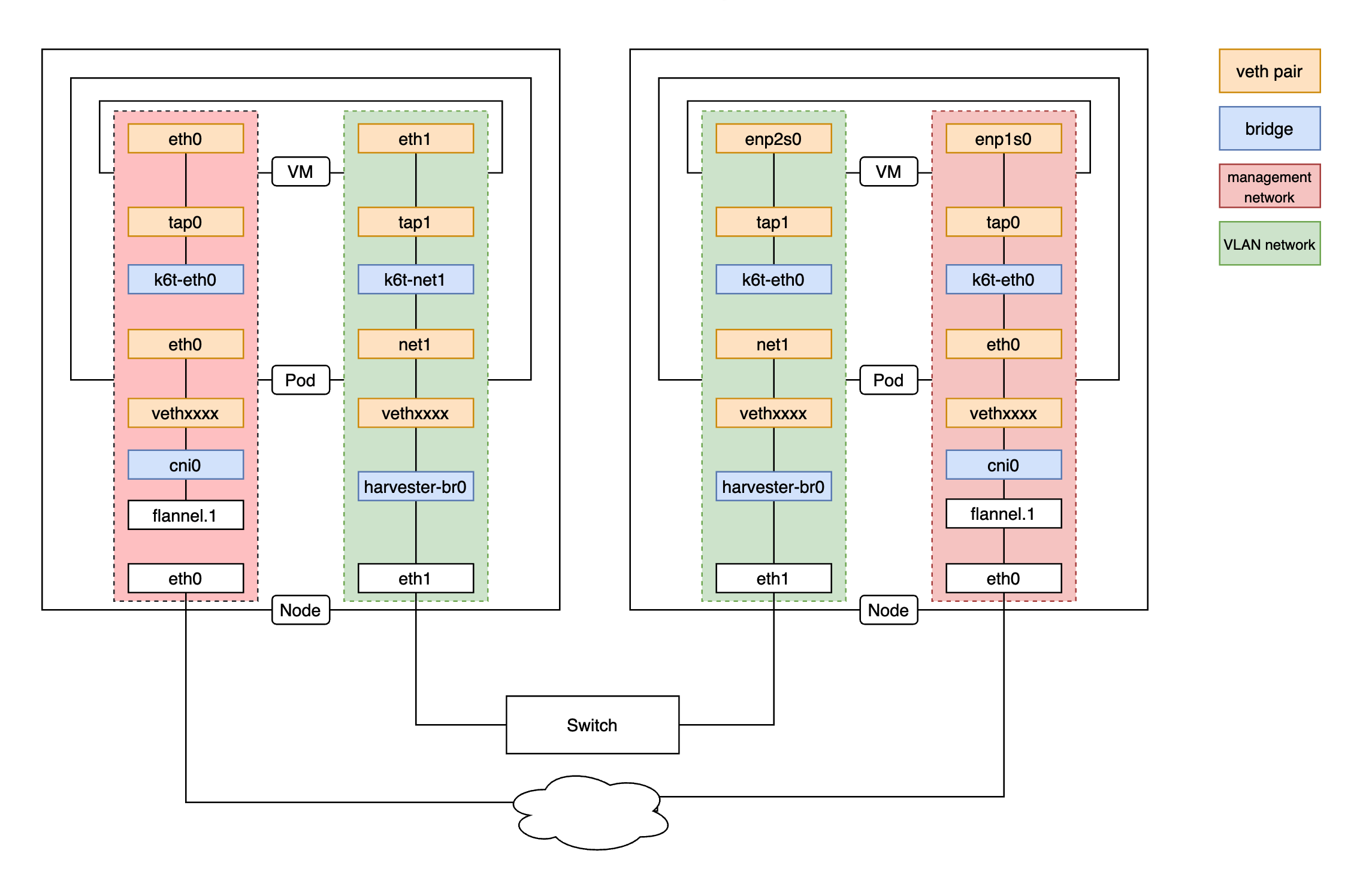
Kubernetes service is a built-in load balancer for the pods. The VM in Harvester is a pod. Thus, it's simple to provide a load balancer by leveraging Kubernetes service in Harvester. Every service of type “LoadBalancer” has a nodeport. We take this nodeport as the target port for service in Harvester. In this way, a service in Harvester can become a load balancer for the service of the guest cluster.
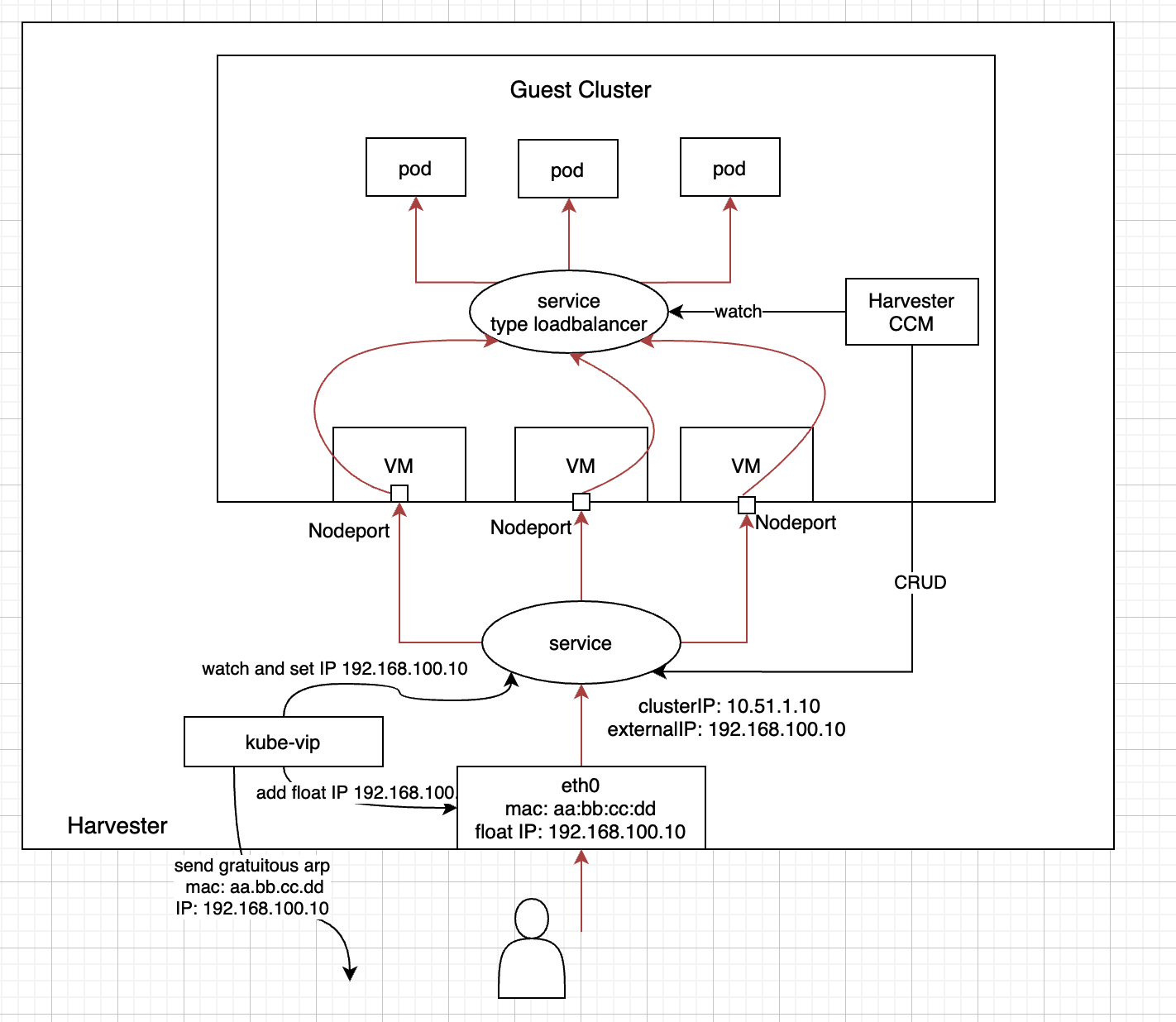
Pros:
- It's simple to configure and we don’t need to modify the source code.
Cons:
-
Need to add health check
-
Poor extensibility because of Kubernetes service, for example, do not support QoS.
-
Do not support TLS.
We can use a reverse proxy such as Traefik as the load balancer component implementation.
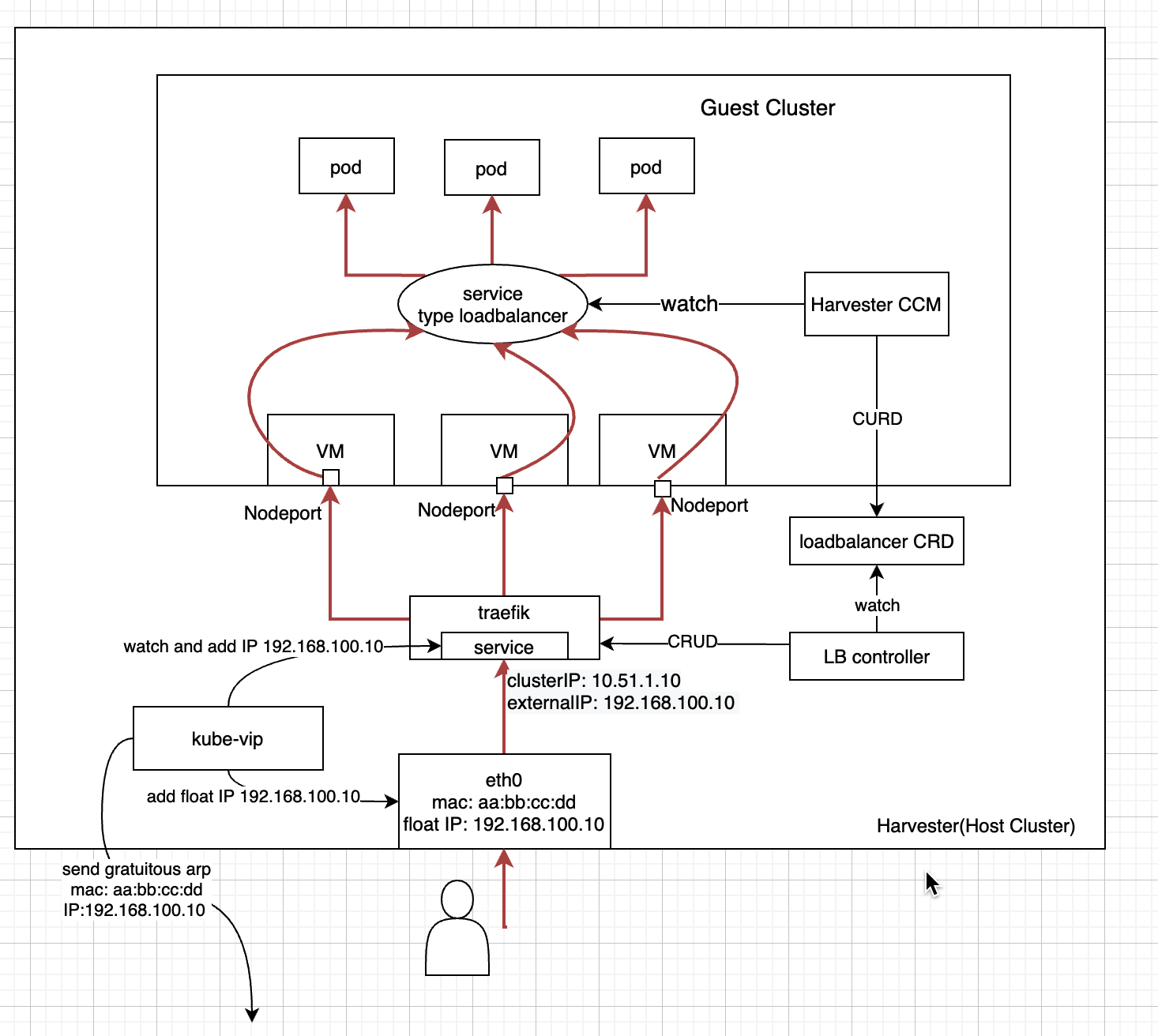
Pros:
- Better forwarding performance compared with Kube-vip.
- Support both layer 4 and layer 7 protocol.
- Support TLS.
- Support dynamic reload.
- Support health check.
Cons:
- Custom development and future maintenance of LB controller and Traefik configurations.
type LoadBalancer struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec LoadBalancerSpec `json:"spec,omitempty"`
Status LoadBalancerStatus `json:"status,omitempty"`
}
type LoadBalancerSpec struct {
// +optional
Description string `json:"description,omitempty"`
// +optional
Listeners []Listener `json:"listeners"`
}
type Listener struct {
Name string `json:"name"`
EntryPort int `json:"entryPort"`
Protocol string `json:"protocol"`
// +optional
BackendServers []BackendServer `json:"backendServers"`
// +optional
HeathCheck HeathCheck `json:"healthCheck,omitempty"`
// +optional
// TODO TLS
// +optional
// TODO Middleware
}
type BackendServer struct {
Address string `json:"address"`
// +optional
Weight int `json:"weight,omitempty"`
}
type HeathCheck struct {
Path string `json:"path"`
Port int `json:"port"`
Interval time.Duration `json:"interval"`
Timeout time.Duration `json:"timeout"`
}
type LoadBalancerStatus struct {
// +optional
Conditions []Condition `json:"conditions,omitempty"`
}Here is the brief Development guideline in Kubernetes official website. The main task is to implement the Cloud Provider Interface, including Instance(called node in Kubernetes), LoadBalancer, Routes interface, etc. We focus on Instance and LoadBalancer interface.
// Interface is an abstract, pluggable interface for cloud providers.
type Interface interface {
// Initialize provides the cloud with a kubernetes client builder and may spawn goroutines
// to perform housekeeping or run custom controllers specific to the cloud provider.
// Any tasks started here should be cleaned up when the stop channel closes.
Initialize(clientBuilder ControllerClientBuilder, stop <-chan struct{})
// LoadBalancer returns a balancer interface. Also returns true if the interface is supported, false otherwise.
LoadBalancer() (LoadBalancer, bool)
// Instances returns an instances interface. Also returns true if the interface is supported, false otherwise.
Instances() (Instances, bool)
// InstancesV2 is an implementation for instances and should only be implemented by external cloud providers.
// Implementing InstancesV2 is behaviorally identical to Instances but is optimized to significantly reduce
// API calls to the cloud provider when registering and syncing nodes. Implementation of this interface will
// disable calls to the Zones interface. Also returns true if the interface is supported, false otherwise.
InstancesV2() (InstancesV2, bool)
// Zones returns a zones interface. Also returns true if the interface is supported, false otherwise.
// DEPRECATED: Zones is deprecated in favor of retrieving zone/region information from InstancesV2.
// This interface will not be called if InstancesV2 is enabled.
Zones() (Zones, bool)
// Clusters returns a clusters interface. Also returns true if the interface is supported, false otherwise.
Clusters() (Clusters, bool)
// Routes returns a routes interface along with whether the interface is supported.
Routes() (Routes, bool)
// ProviderName returns the cloud provider ID.
ProviderName() string
// HasClusterID returns true if a ClusterID is required and set
HasClusterID() bool
}We focus on LoadBalancer and InstancesV2 interface.
type InstancesV2 interface {
// InstanceExists returns true if the instance for the given node exists according to the cloud provider.
// Use the node.name or node.spec.providerID field to find the node in the cloud provider.
InstanceExists(ctx context.Context, node *v1.Node) (bool, error)
// InstanceShutdown returns true if the instance is shutdown according to the cloud provider.
// Use the node.name or node.spec.providerID field to find the node in the cloud provider.
InstanceShutdown(ctx context.Context, node *v1.Node) (bool, error)
// InstanceMetadata returns the instance's metadata. The values returned in InstanceMetadata are
// translated into specific fields and labels in the Node object on registration.
// Implementations should always check node.spec.providerID first when trying to discover the instance
// for a given node. In cases where node.spec.providerID is empty, implementations can use other
// properties of the node like its name, labels and annotations.
InstanceMetadata(ctx context.Context, node *v1.Node) (*InstanceMetadata, error)
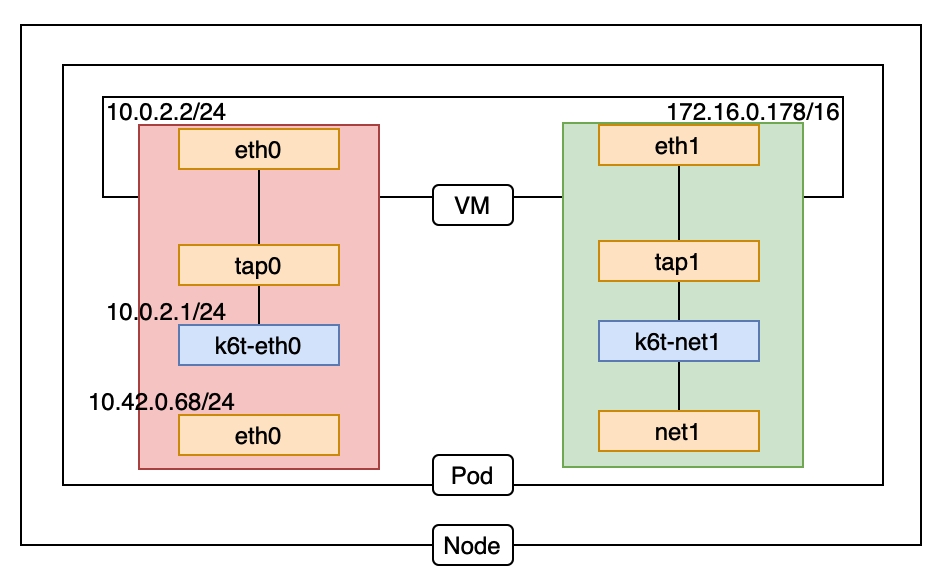
}We can fetch the instance information through the VirtualMachine and VirtualMachineInstance API of Harvester.
We may need the help of the guest agent to get the VM address.
The LoadBalancer API depends on how we implement the load balancer.
- The physical NIC can't be used by VLAN network and Kube-vip at the same time if Kube-vip gets the VIP from DHCP server.