
- Organization: International Neuroinformatics Coordinating Facility (INCF)
- Mentor: Petr Ježek
- Student: Yijie Huang
- GitHub: yijie0727
- Archive: Google Summer of Code 2019 Archive
- Previous Work: GSoC 2018 - Joey Pinto
INCF laboratory is focused on Electroencephalography (EEG) and event-related potential (ERP) experiments. In order to make the work with the processing of EEG/ERP data as much flexible as possible in the previous year of GSoC2018, a web-based GUI for designing signal processing workflows was developed. This project is a continuous work based on GSoC2018 worked by Joey Pinto. Workflows are built from component blocks that can be combined and rearranged at runtime without making any modification to code.
The previous design can only deal with the cumulative data followed the standard workflow paradigm supposing that one block starts immediately after the previous one terminates.
This year, the aim is to modify the previous cumulative workflow designer to enable also running of continuous workflows, and improve the execution efficiency.
This project consists of three parts:
- 1.WorkFlow Designer: the logical part which supports the execution continuous workflows.
- 2.WorkFlow Designer Web: the maven web application which offers the GUI for users to configure and start their own workflows.
- 3.WorkFlow Examples: the blocks samples and tests, which are mainly included in two projects: EEGWorkflow(all the EEG data processing blocks), Common(all the normal data processing blocks).
My contribution to the three parts are listed bellow.
INCF Repository. 1 WorkFlow Designer
- My Commits
- My Pull Requests
- For this part, I refactored the previous maven project, using Observer Pattern and multiple threads to make the proper cumulative blocks in the workflow execute in parallel. Also I implemented two more workflow execution modes, thus besides the cumulative data, it can deal with continuous stream data and mixed data now.
- To start this part, git clone and mvn install.
- More instruction in GSoC2019 designer README.md, and GSoC2018 designer user mannual.
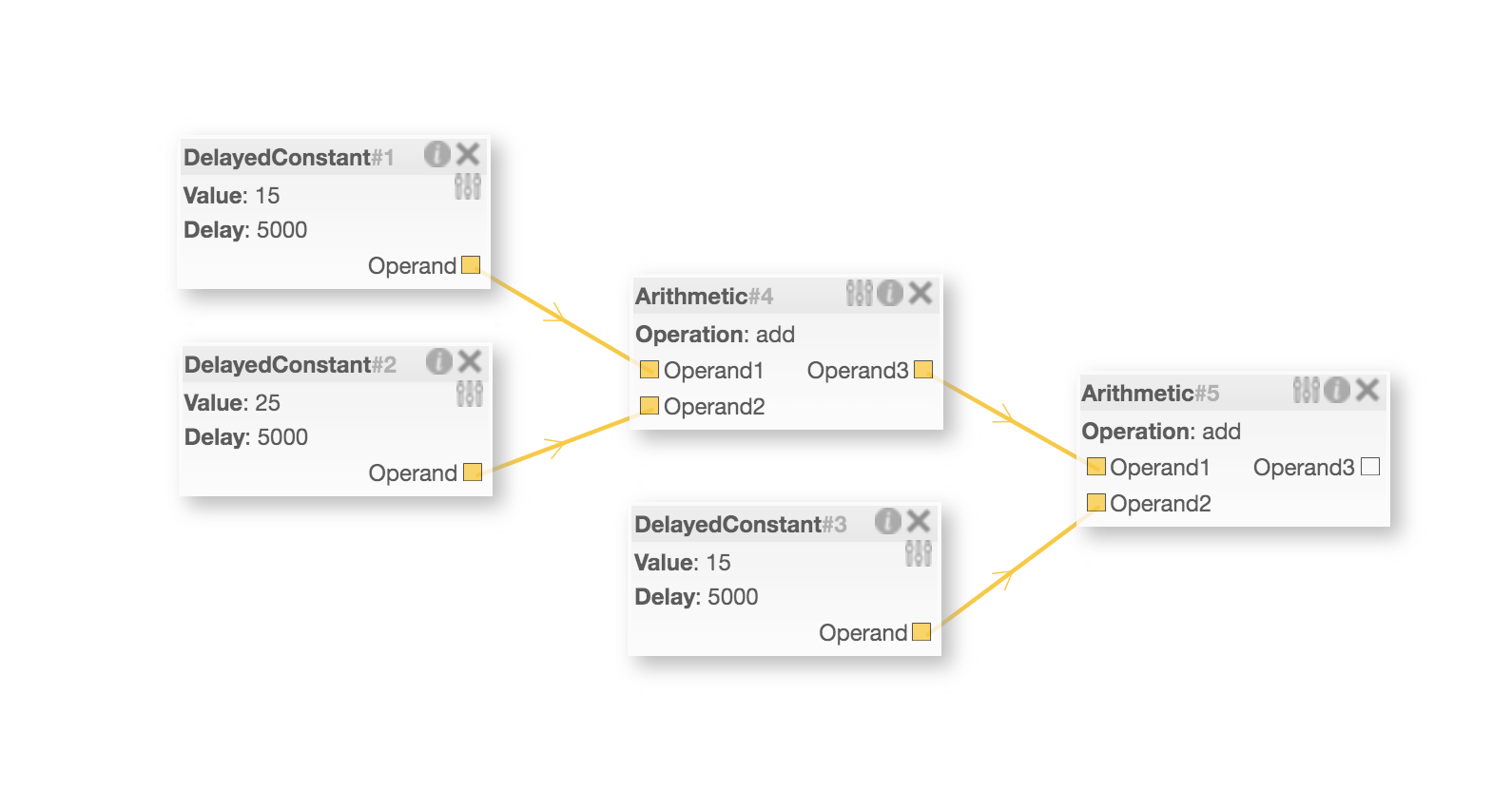
| Store Workflow in Templates, and Execute it in Parallel |
|---|
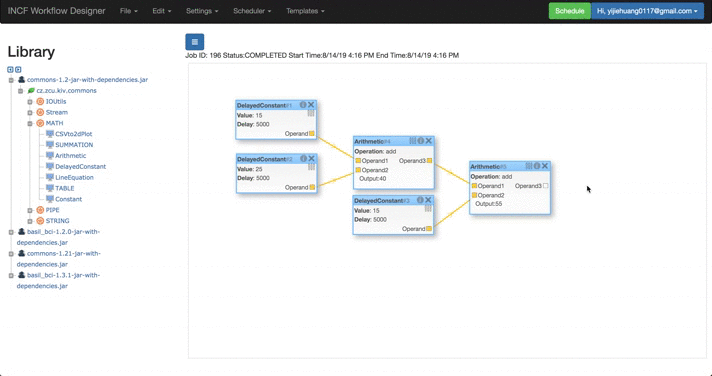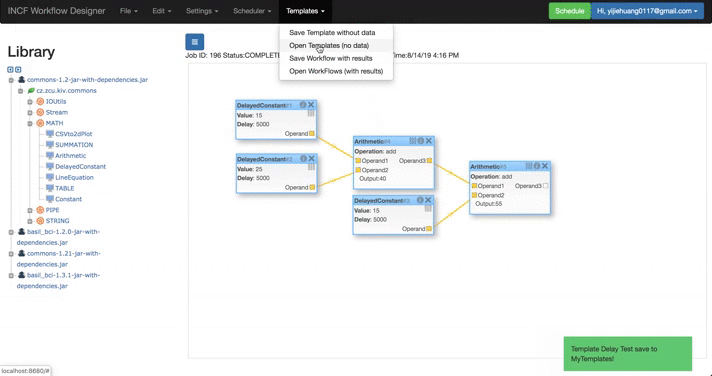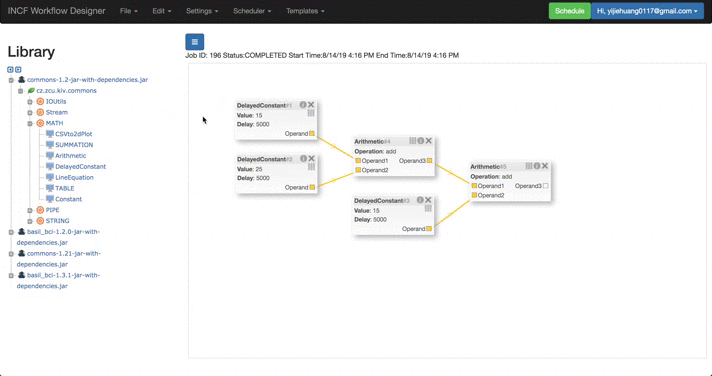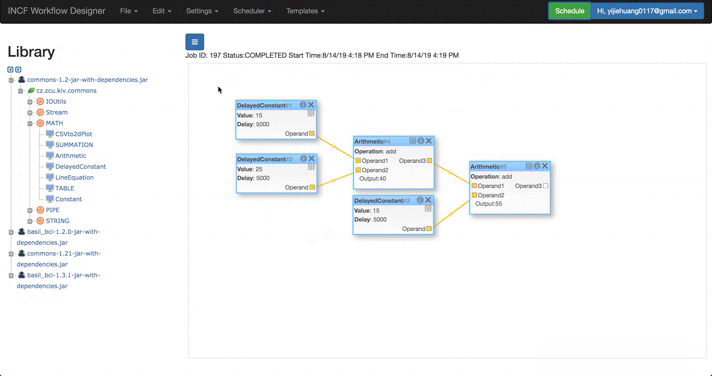 |
Compared with the previous introduction video, it is clear that delayConstant blocks with no dependencied execute at the same time instread of waiting checking one by one.
INCF Repository. 2 WorkFlow Designer Web
- My Commits
- My Pull Requests
- I mainly modified its interface connected with the WorkFlow Designer, and also add several functions in the GUI: thus users can store their own workflows with/without result to their own project user directory.
- To start this part, git clone and mvn package. Type "java -jar target/workflow_designer_server-jar-with-dependencies.jar" in the terminal, and the open localhost:8680 in the browser.
- More instruction in GSoC2019 web README.md, and GSoC2018 web user mannual.
| Templates Functions | Templates Table | Stored Template |
|---|---|---|
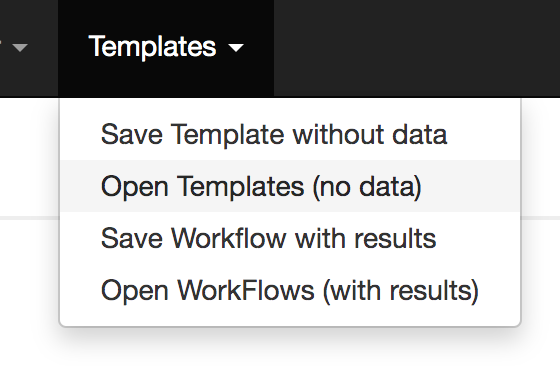 |
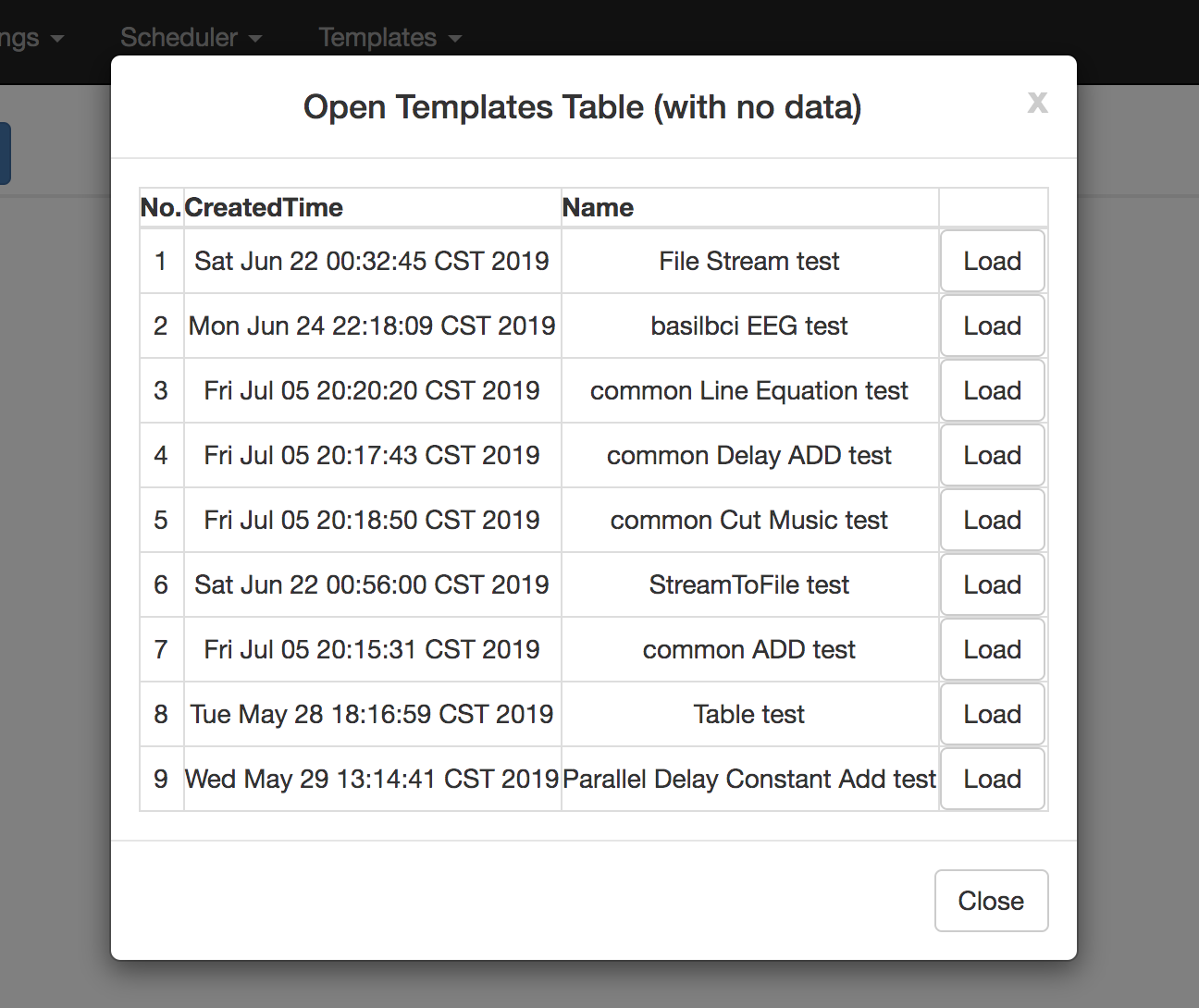 |
 |
INCF Repository. 3 WorkFlow Examples
- My Commits
- My Pull Requests
- I mainly changed the corresponding blocks in the samples from only designed for cumulative data to also for continuous stream and mined data. And I built some new blocks and new unit tests to test the new workflow execution mode.
- After the designer part is installed in maven, open one of the samples: EEGWorkflow, Common, after mvn package, import the generated jar in the targert into the open GUI(localhost:8680), then user can directly drag the blocks listed in the left blocks tree, and combine their own workflows and execute.
- More instruction in GSoC2019 sample README.md.
| Mixed Data Workflow | Complete Workflow |
|---|---|
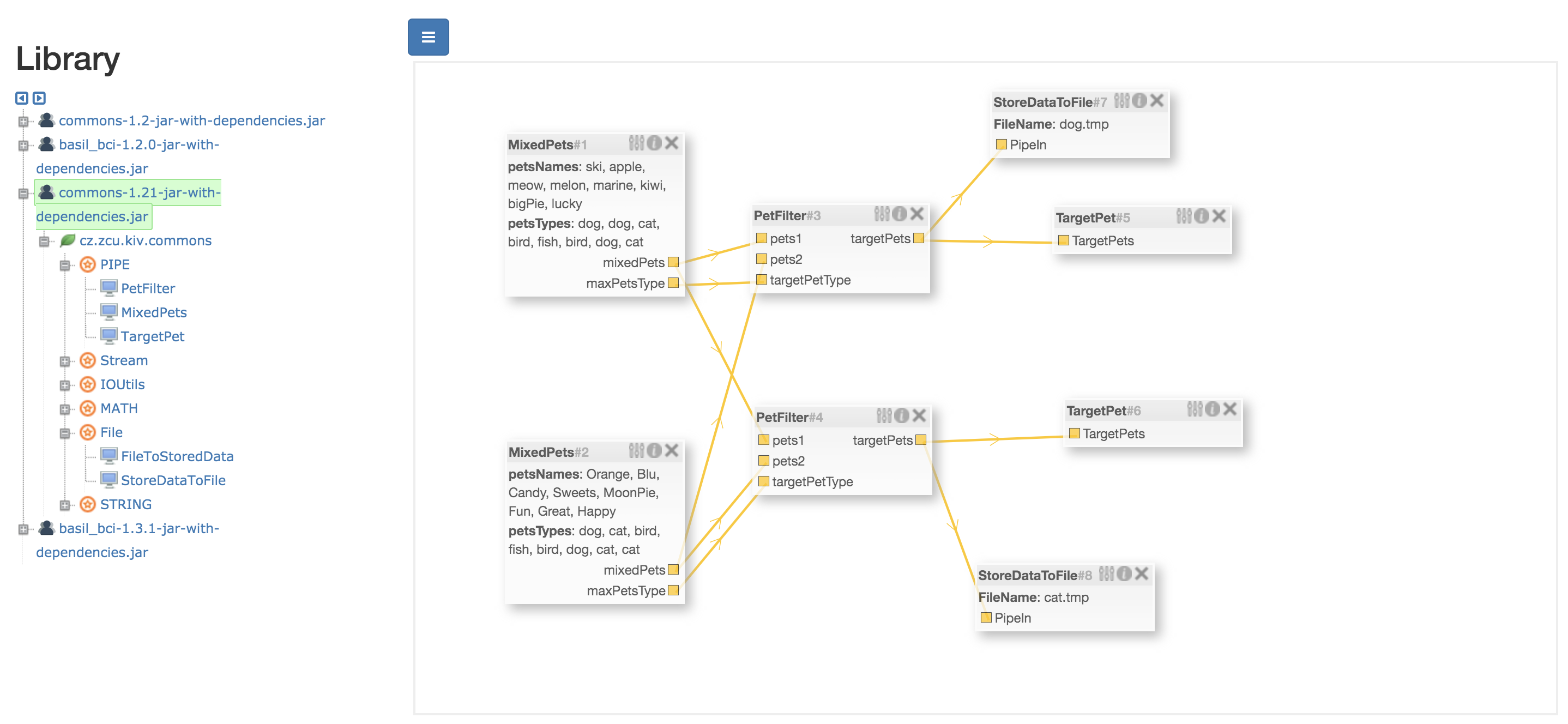 |
 |
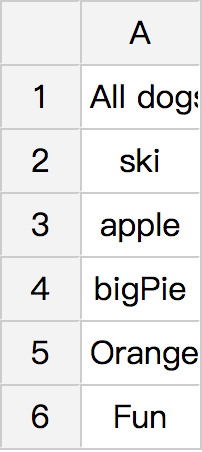
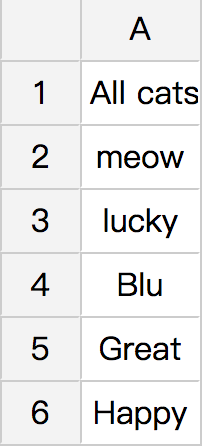
| Result Table 1 | Result Table 2 |
 |
 |
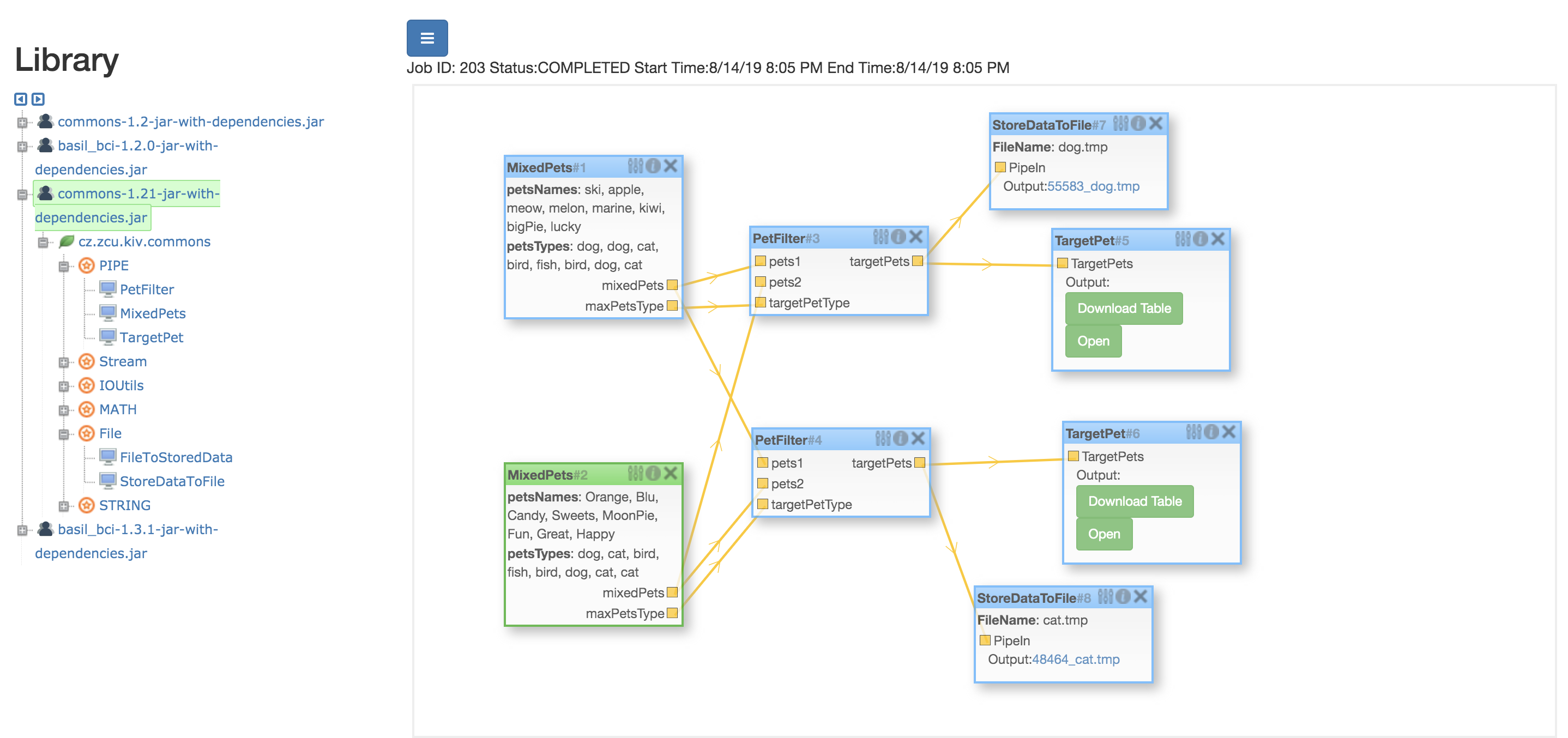
Above is a Mixed Workflow Example, below is the general comments of those blocks, and users can build their own blocks and workflows according to the examples:
Pet: Object to store the pet name and type. (Can be sent in PipedOutputStream continuously decorated by ObjectOutputStream)
/**
MixedPets(mixed block):
Use one @BlockOutput annotation in STREAM type to denote PipedOutputStream to send the continuous data:
Here Pet objects are send through it decorated by ObjectOutputStream.
Once one object is generated, it is sent immediatelt instread of waiting all the objects are generated and then use array or list to transfer data.
*/
@BlockType(type ="MixedPets", family = "PIPE")
public class MixedPets {
@BlockProperty(name = "petsNames", type = STRING, description = "Enter all the pets name, separate input pets Name with ',' (example: apple, meow, melody, marine, kiwi, bigPie, lucky)")
String petsName;
@BlockProperty(name = "petsTypes", type = STRING, description = "Enter corresponding type, separate input pets Type with ','(example: dog, cat, bird, fish, bird, dog, cat)")
String petsType;
@BlockOutput(name = "mixedPets", type = STREAM)
PipedOutputStream pipedOut = new PipedOutputStream();
@BlockOutput(name = "maxPetsType", type = STRING)
String maxPetType;
@BlockExecute
public void process() throws Exception {
// omit the block execution method that convert the two @BlockProperties into Pet Objects and sent these object
}
}/**
PetFileter(mixed block):
It use two PipedInputStream under @BlockInput annotation and one PipedOutputStream under @BlockOutput annotation.
The two PipedInputStream read Pet Objects sent from its previous two MixedPet block's PipedOutputStream and then, the method filter the target Pet Objects, send them to the next Blocks by PipedOutputStream.
*/
@BlockType(type ="PetFilter", family = "PIPE")
public class PetFilter {
@BlockInput(name = "targetPetType", type = STRING)
String petType;
@BlockInput(name = "pets1", type = STREAM)
PipedInputStream pipedIn1 = new PipedInputStream();
@BlockInput(name = "pets2", type = STREAM)
PipedInputStream pipedIn2 = new PipedInputStream();
@BlockOutput(name = "targetPets", type = STREAM)
PipedOutputStream pipedOut = new PipedOutputStream();
@BlockExecute
public void process() throws Exception {
// omit the block execution method that reads pet objects continuously from its souece blocks and filter them into the next target block
}
}/**
PetTarget(continuous block):
This block has only one PipedInputStream under @BlockInput annotation, and it reads the target pet objects.
*/
@BlockType(type ="TargetPet", family = "PIPE")
public class PetTarget {
@BlockInput(name = "TargetPets", type = STREAM)
PipedInputStream pipedIn1 = new PipedInputStream();
@BlockExecute
public Table process() throws Exception{
// omit the execution method to collect the target pet objects and list them on table
}
}/**
StoreDataToFileBlock(continuous block):
Use one PipedInputStream to collect the continous data from its previous data and store them to a file.
User can use another "FileToStoredData Block" to recover the stored continuous data, to avoid repeating jobs
*/
@BlockType(type="StoreDataToFile", family = "File" )
public class StoreDataToFileBlock {
@BlockProperty(name = "FileName", type = STRING)
private String fileName;
@BlockInput(name = "PipeIn", type = STREAM)
private PipedInputStream pipeIn = new PipedInputStream();
@BlockExecute()
public File process() throws Exception {
// omit the process to store continuous stream to a file
}
}-
Git clone the above three repositories, mvn install the workflow_designer, and then mvn package one of the samples project in workflow_designer_samples. And configure your settings by copying the config.properties.template into config.properties and add your own settings, then mvn package the workflow_designer_server, type "java -jar target/workflow_designer_server-jar-with-dependencies.jar", then open the web GUI in browser(localhost:8680).
-
After open the GUI, import the jar already mvn package in the navigation bar and drag the blocks into the canvas from the left blocks tree to build your own workflows.
-
The cumulative blocks and corresponding workflows guildines can be found in GSoC2018 user manual. The only difference is that once the cumulative blocks are chosen to execute as jar externally(the field runAsJar in annotation @BlockType is true), you can set another field jarRMI true or false, thus the data will be transfered among blocks by RMI or file serialization.
@BlockType(type ="ARITHMETIC", family = "MATH", runAsJar = true, jarRMI = true) // the @BlockExecute method will be exterally as jar and data are fetched/sent through RMI
public class ArithmeticBlock {}- To create user's own continuous or mixed block, here are some examples and guildlines:
@BlockType(type ="TargetPet", family = "PIPE")
public class PetTarget {
@BlockInput(name = "TargetPets", type = STREAM) // use STREAM to denote continuous data
PipedInputStream pipedIn1 = new PipedInputStream(); // PipedInputStream is the BlockInput, reading continuously until no data
@BlockExecute
public Table process() throws Exception{
ObjectInputStream objectInputStream = new ObjectInputStream(pipedIn1); //ObjectInputStream to decorate PipedInputStream to receive Pet object continuously
Pet pet;
String petType = null;
Table table = new Table();
List<List<String>> rows = new ArrayList<>();
List<String> colHead = new ArrayList<>();
while((pet = (Pet) objectInputStream.readObject())!= null){
rows.add(Arrays.asList( pet.getName() ));
if(petType == null){
petType = pet.getType();
colHead.add("All "+petType+ "s name:");
}
}
table.setColumnHeaders(colHead);
table.setRows(rows);
table.setCaption(petType+ "s Table");
pipedIn1.close(); //close all the stream used
objectInputStream.close();
return table;
}
} The most different part to create a new block to deal with continuous data instead of cumulative data is the @BlockInput and @BlockOutput. In cumulative blocks, these two fields can denote any primitive data or any user-defined class.The corresponding output in source blocks and inputs in destination blocks pair should be the same type. Next block will only be assigned its inputs once previous blocks are ready for their outputs.
However, in continuous block, the type of @BlockOutput to send the stream continuously can only be STREAM, and the corresponding field can only be PipedOutputStream. Similarly, the type of @BlockInput to receive the stream continuously can only be STREAM, and its corresponding field can only be PipedInputStream as shown in the above example. Since every block is executed in its own thread, then pipe communication is used to transfer continuous data.
In the method with the @BlockExecute annotation, use PipedInputStream to read data, PipedOutputStream to write data, and such reading or writing will stop once no data received or generated. Thus the block will continue to execute till the end.
- To build user's own continuous or mixed workflows, here are some guildlines: You can configure cumulative, continuous and mixed blocks in one workflow, as long as the the corresponding @BlockInput and @BlockOutput pair have the same type. And then set all the @BlockProperty value in the workflow, press the Schedule button waiting the results.
-
Cumulative Blocks which use the native library can only be executed as Jar externally if such blocks are used in Web GUI to avoid the multiple classLoader's problem, otherwise it will cause UnsatisfiedLinkError. However they can be executed internally in local without GUI.
-
Continuous/Mixed Block which use the native library can only be executed internally in local without GUI, because stream transfer between blocks cannot be done when executed as Jar.
-
Blocks dealing with the Stream cannot be set runAsJar true and jarRMI true, since stream cannot be serialized through RMI in Java.
This project allows users to create their own data processing blocks in their own project, import those blocks and configure them into different workflows in web-based GUI.
The most exsiting part is, now it can not only deal with the cumulative data, but also the continuous stream and mixed data. The pocessing blocks can execute in parallel in multiple threads immediately when they receive continuous stream and complete if no more data received, instead of waiting one by one, which greatly expand the use scope of this application and increase the execution efficiency.
The greasted challege I faced during the whole development phase was sending continuous data from multiple outputs of different blocks into different inputs belonging to different blocks, which was resolved by Pipe communication between different threads.
- More Workflow blocks used to deal with the Lab Streaming Layer data can be added.
- More languages supports are welcome.
- Improvement about the blocks with native libraries execution in GUI. Make it possible to execute the above particular blocks in GUI instead of only in local.
I want to thank my mentor Petr Ježek, and his colleagues, Lukas Vareka and Tomas Prokop, for showing great patience and professionalism to give me advice and suggestions during the three months; also Joey Pinto, in proposal application period, for helping me get familiar with his previous cumulative workflow design; and Google Summer of Code program, providing this great platform for us to have three months take part in the contribution to the open sources and enjoy the unforgettable experience.