- 메모리란 크면 느리고, 빠르면 작을 수 밖에 없는 운명적인 한계를 갖습니다.
- 느리면 가격이 저렴하기 때문에 크게 구성할 수 있고, 빠르면 가격이 비싸기 때문에 작게 구성해야 하는 경제적인 이유가 있고
- 작은 메모리는 CPU와 가깝게 둘 수 있고, 큰 메모리는 CPU로 부터 멀리 두게 되는 지역적인 이유로 인한 속도 저하도 있을 것 입니다.
- 메모리는 위에서 설명한 것처럼 하나가 길면 다른 하나가 짧아지는 운명적인 한계를 갖습니다.
- 또한 CPU의 성능이 지수적으로 증가했음에도 메모리 Access spped는 1차함수로 증가하여 CPU의 성능과 상당한 격차가 벌어지게 됩니다.
- 하지만 우리는 크고 빠른 메모리를 원합니다.
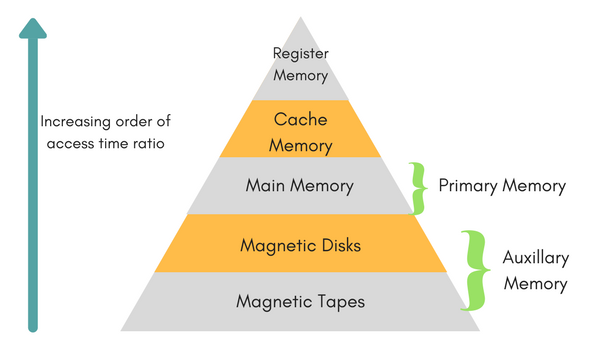
- 메모리의 한계를 극복하고 사용자에게 크고 빠른 메모리처럼 보이도록 하기 위해서 만들어 낸 것이 메모리 hierarchy입니다.
- Memory Hierarchy란 빠르고 작은 메모리와 크고 느린 메모리의 장점을 조합해서 크고 빠른 듯 행동하는 메모리를 만드는 것입니다.
- 우리는 앞으로 배울 Locality와 Cache를 사용해서 좋은 메모리 구조를 만드는 법을 배울 것입니다.
- 지역성이란 컴퓨터는 최근에 썼던 주소와 동일한 주소나 주변의 주소를 다시 참조하는 경우가 자주 있다는 의미입니다.
- Temporal Locality : 최근에 참조된 주소는 가까운 미래에 다시 쓰일 확률이 높다.
- Spatial Locality : 방금 참조된 주소의 주변 주소들은 가까운 미래에 쓰일 확률이 높다.
- Cache는 아키텍쳐 Set의 핵심 구성요소로 수나 크기를 변경하기 힘든 레지스터 메모리를 제외하고 그 다음으로 빠른 메모리입니다.
- 앞으로는 크게 Cache와 Memory라는 두 개의 계층구조로 나누어서 Cache는 작지만 빠른 메모리, SlowMemory는 크지만 느린 메모리로 약속하고 얘기하려고 합니다.
- CPU가 값을 가져오려고 할 때 Cache에 해당하는 값이 있다면 Memory까지 가지 않고 Cache까지만 가서 값을 가져올 수 있습니다. 이 경우를 Cache Hit이라고 합니다.

- 반대의 경우로 CPU가 값을 가져오려고 할 때 Cache에 해당하는 값이 없다면 Memory까지 가서 값을 가져와야 합니다. 이 경우를 Cache Miss이라고 합니다.
- 그림은 12가 cache에 없는 경우에 메모리에서 가져오는 것을 보여주고 있습니다.

- 만약 우리가 Cache메모리를 처음 고안해낸 사람이라고 생각해 봅시다. 우리가 쓰는 메모리 주소가 64비트로 이루어져 있고 각 메모리의 주소에는 1비트의 정보를 담을 수 있다고 가정해 봅시다. 한 칸의 메모리에 얼마의 정보를 담으면 효율적일지 고민하려고 합니다.
- 한 칸의 캐쉬 메모리에 1비트의 값을 저장한다면 8개의 비트의 값을 저장하기 위해서 캐시 메모리는 8개의 주소를 지니고 있는 방법을 쉽게 생각해 볼 수 있습니다.
- 그렇다면 우리는 1Byte의 정보를 저장하기 위해서 8Byte 주소가 8개 필요합니다. 즉 주소를 저장하는 데에만 64Byte의 비트가 필요합니다. 너무 비효율적이죠?
- 조금 더 발전해서 8비트씩 값을 저장하면 어떨까요. 64비트에서 끝의 3비트는 모두 0으로 생각해서 주소로 61비트만 있다면 한 칸의 캐쉬 메모리에 8비트의 정보를 저장할 수 있을 겁니다.
- 2^3 = 8이라는 걸 기억해서 64 - 3 = 61 비트가 성립했다는 것을 알면서 따라온다면 똑똑한 학생입니다.
- 왜 b라고 했을까요. 이유는 우리가 지금까지 한 칸이라고 불렀던 메모리의 한 칸을 블록(Block)이라고 하기 때문입니다.
- 하나의 블록에 2^b비트를 저장한다면 우리에게 필요한 주소 비트는 몇 비트가 될까요.
- 답은 64 - b 비트 입니다.
- 자 여기까지 하고 간단한 예를 들어서 적용해 봅시다.
- 우리가 만든 캐쉬 메모리는 한 블록에 2^b 비트를 저장할 수 있습니다. 그리고 아직 한 블록밖에 없다고 문제를 간단히 해보죠.
- CPU가 1000...001이라는 64비트의 메모리 주소에서 값을 찾아달라고 요청합니다.
- 그러면우리는 주소값에서 뒤에 b개의 비트를 제외한 64-b비트만 가져와서 우리의 캐쉬 주소와 비교해봅니다.
- 운이 좋아서 해당 주소가 우리 캐쉬 주소와 일치했다고 합니다. 그런데 우리는 2^b의 비트가 있는데 어떻게 값을 찾을 수 있을까요.
- 답은 우리가 방금 제외한 b개의 비트로 찾을 수 있습니다. b개의 비트의 값은 0..001이고 값이 1이라고 합니다. 그렇다면 우리는 0번부터 2^b번까지 가지고 있는 블록 데이터에 1번째 값을 찾으면 원하는 값입니다.
- 0번째에서 얼마나 떨어져있는지 알려주는 b개의 비트를 BlockOffset이라고 부릅니다.
- 우리는 한 칸 짜리 캐시 메모리를 만들어 보았습니다. 그런데 이제 칸을 더 늘이고 싶습니다.
- 조금 속도를 내 보겠습니다. 우리는 2^s개의 칸을 만들고 싶다고 해보죠. 그리고 이제 각각의 칸을 set이라고 부르겠습니다.
- 2^s을 표현하려면 몇 개의 비트가 필요할까요. 네 s개의 비트가 필요한데요. s개의 비트를 set의 주소를 찾는데 쓴다면 우리의 캐쉬 주소 비트 = 64 - s - b로만 구성된다는 걸 알 수 있습니다.
- 0번째 set에서 얼마나 떨어져있는지 알려주는 s개의 비트를 setOffset(index)이라고 합니다.
- 우리가 지금까지 설명했던 캐쉬 주소란 tag비트라고 부릅니다. 메모리 주소가 cache에 있는지 비교하는 가장 결정적인 Key랍니다.

- Tag bit = 64 - s - b 비트라고 했습니다. 엄밀하게 설명하면 이전까지의 설명이 맞습니다.
- 하지만 보통 캐시 메모리에 저장하는 데이터 단위를 비트가 아닌 1byte단위로 추상화를 합니다. 따라서 메모리에 값을 저장할 때 하나의 주소에 1byte씩 저장할 수 있다고 생각하면 됩니다.
- 문제를 풀 때에는 Tag bit = m - s - b 라는 점은 변함이 없습니다. 다만 이제 단위가 bit가 아닌 byte라는 점을 기억해야 합니다.
- 또한 설명을 하면서 지나친 부분이 있는데 블록 오프셋을 시작값으로 해서 얼마만큼의 데이터를 읽어올지를 결정하는 것은 시스템의 word 사이즈입니다. word 사이즈가 4bytes 인경우 4 byte를 읽어들인다고 생각하면 됩니다.

- 우리가 지금까지 배운 캐쉬 구조를 Direct Mapping이라고 합니다.
- Index는 set의 주소이고 Cache의 주소를 Tag라고 부릅니다. 여기에서는 1비트만 저장하는 캐쉬라고 보면 block Offset은 0이라고 생각해봅시다.
- Data에는 Memory(10000)에 있는 값이 저장되었다고 보면 됩니다.
- Valid가 필요한 이유는 캐쉬 블록에 값이 없는 경우에는 칸이 비어있는 것처럼 보이지만 사실 의미없는 0과 1의 값이 쓰레기값으로 들어가있습니다. 따라서 이런 값을 실제 데이터와 구분해주기 위해서 Valid를 표시하는 1비트가 필요합니다.

- 위의 그림에서 메모리 주소인 m은 5비트로 이루어져 있고, Cache의 set의 개수가 8개(8칸) 이므로 S = 2 ^ 3, s = 3비트 입니다.
- 캐시 한 칸이 차지하는 정보는 B = 1 byte= 2 ^ 0 byte 이니 Tag 비트 = m - s - b = 2bit라는 것을 알 수 있습니다.
- 그림에서 보는 것처럼 다른 Cache의 비어있는 set이 있더라도 각 메모리 주소가 들어갈 수 있는 칸이 정해져 있기 때문에 2개의 칸에만 계속해서 값이 저장되는 것을 볼 수 있습니다.
- 캐시는 공간 활용을 잘 하지 못해 miss rate이 높아질 거라고 예상할 수 있습니다.
- 이름을 듣고 어려워 보일 수 있지만 그렇지 않습니다. 이전에 배웠던 Direct Mapping Cache는 메모리의 주소에 따라서 고정적으로 set이 정해지기 때문에 공간 활용을 잘 하지 못하는 것이 단점이라고 배웠습니다.
- 그렇다면 어떻게 해결할 수 있을까요. 캐시가 값을 저장할 때 상황에 따라 값을 배정할 수 있다면 더 나을 것 같습니다.
- 그래서 이전에는 하나의 Set에 하나의 Block만 있었던 것을 여러개의 Block이 Set에 들어갈 수 있도록 늘려줍니다. set안에 있는 블록의 수를 Line이라고 합니다. 지금까지는 Line = 1인 캐쉬만 만들었다고 볼 수 있습니다.
- 그렇다면 setoffset이나 blockoffset을 만든 것처럼 lineoffset이 필요할까요?
- 아닙니다. lineoffset을 만들어준다면 lineoffset비트에 따라서 고정적으로 위치가 정해질 테니 만들어준 의미가 없겠죠. 그래서 tag bit = m - s - b라는 공식은 변하지 않습니다.
- 이제 같은 set에 메모리 값이 여러개가 저장되려고 할 때 우리는 하나의 set안에 복수의 line을 넣음으로써 캐시에게 같은 set안에서 어떤 위치에 값을 저장할 지 자율성을 선사한 셈입니다.
- 자 설명이 길었는데 그림으로 보겠습니다.

- Direct Mapping과 비교해서 Cache의 자율권이 늘어난 것이 보이시나요. 자율성이 늘어나면서 캐시는 정책이 필요해졌습니다. 어떻게하면 cash miss를 줄일 수 있을까요?
- 연속적으로 같은 set에 서로 다른 값들이 저장되려고 할 때 새로 들어온 값을 어디에 배치할 것인지에 대한 문제는 기존의 저장되있던 어떤 캐시의 값을 삭제할 것인지와 필연적으로 맞닿아 있습니다.
- 또한 cpu가 보내준 주소값의 cache hit을 확인하려고 할 때 set안에 여러개의 block이 있고 주소를 가지고는 그 중 어떤 블록에 값이 담겨있을지 전혀 예측할 수 없다는 단점도 생기게 되겠죠. 그래서 해당 set안의 모든 block(line개수와 같겠죠)에 대해서 tag를 비교해서 값을 찾아내야 합니다.
- Full associate cache는 한 줄로 설명할 수 있습니다.
- set이 감소하고 line이 늘어나던 associate cache가 최대로 팽창한 1개의 set안에 모든 블록이 들어있는 cache입니다.
- 어떤 캐쉬값을 삭제할 것인가.
- 일부러 C로 앞글자를 맞추었는지 모르겠지만 모두 다 C로 시작한다.
- Compulsory Miss : Cash가 채워지지 않아서 발생하는 Miss
- Block Size를 크게 함으로서 줄일 수 있다
- Block Size를 크게 함으로써 Miss penalty가 커질 수 있다.
- Conflict Miss : Cash의 같은 블록에 서로 다른 값이 충돌할 수 있어서 발생하는 Miss
- set Associate를 늘임으로써 어느정도 해결이 가능하다.
- set이 증가하면서 Access time(hit time)이 증가하게 된다.
- Capacity Miss : 프로그램에서 필요한 메모리의 크기가 Cache의 용량보다 크기 때문에 발생하게 되는 MISS
- 당연히 캐쉬의 용량의 크기를 키우면 해결된다.
- 큰 캐쉬는 Access time(hit time)을 증가시킬 수 있다.
- Store instruction은 CPU에서 계산한 값을 메모리의 해당 주소에 저장하는 기능을 수행합니다.
- 이 경우 Cache에 해당 주소가 있을 경우와 없는 경우로 나눌 수 있습니다.
- Write-through : 캐쉬에도 쓰고 메모리에도 쓰는 방법입니다. 이 경우 매번 메모리에 쓰는 작업은 큰 비효율을 초래하기 때문에 Write buffer라는 공간에 모아두었다가 Write buffer가 꽉 차면 한번에 업데이트합니다.
- Write-back : 캐쉬에만 써두었다가 나중에 캐쉬에서 밀려날 때 마지막 값을 메모리에 저장을 하는 방식입니다.
- Write allocation : 메모리 값에 값을 저장한 후에 캐쉬에도 가져옵니다.
- no Write allocation : 메모리에만 값을 저장합니다.
- Intel Architecture는 하나의 Cache로 존재하는 것이 아니라 L1, L2, L3와 같이 여러개의 세부 Cache들로 구성된다.
- L1, L2, L3 순으로 Cache에서 가까운데 L1, L2 Cache의 역할은 hit time을 줄이는 것이다. 대부분이 hit이 되기 때문에 hit time이 줄어드는 것이 중요하다.
- L3의 역할은 어느정도 hit time이 느려지더라도 Memory까지 내려가는 걸 필사적으로 막아야한다. miss rate시에 Memory를 참조하는 penalty가 상당히 크기 때문에 따라서 miss rate을 줄이는 것을 핵심 목표로 한다.
- 따라서 Set Associate의 way개수를 살펴보면 L1, L2는 8way, L3는 16way인 것을 알 수 있다.

Cache의 성능은 Access Time으로 평가한다.
- Access Time = Hit Time + Miss rate * Miss penalty
- Hit time이 1 Cycle, Memory Access Time이 100 Cycle 이라고 할 때 hit rate가 97%, 99%인 두 개의 Cache의 성능을 비교해보자.
- 97% Cache Access Time = 1 + 0.03 * 100 = 4 Cycle
- 99% Cache Access Time = 1 + 0.01 * 100 = 2 Cycle
- hit rate만 보았을 때는 비슷할 것 같았는데 실제 계산해보면 99% Cache가 97% Cache보다 두 배가 빠르다.
- 따라서 Cache의 성능을 말할 때는 보통 Miss rate으로 얘기한다.