these commands are specific to mongo shell (mongosh command):
-
show dbs ==> shows list of all available databases
-
use flights ==> when starting to insert data in this DB, then
flightsdb will be created on the fly. -
db.flightData.insertOne({"name":"f1"})
-
db.flightData.find(); ==> shows all data
-
db.flightData.find().pretty(); ==> shows all data in pretty format
-
mongoDB uses
BSON(which is binary json) for storing data in database. -
to delete all data in
flightDatatable: db.flightData.deleteMany({}); -
to delete specific document in
flightDatatable: db.flightData.deleteOne({_id: 1})
**note: in mongoDB documents, if key has no space in it then you can omit the double quotes around the key. but value of
key always must sarround by double quotes.
-
to update specific document: db.flightData.updateOne({_id:2}, {$set: {distance: 1000}})
in
flightDatacollection(table), find the document which has_id=2and then updatedistancecolumn value to 1000. ifdistancekey does not exist, then it first create it and then assign the 1000 value to it. -
to update all documents in a collection, then: db.flightData.updateMany({}, {$set: {marker: "toDelete"}})
-
to find all flights which have distance greater than 1000 km: db.flightData.find({distance: {$gt: 1000}}).pretty()
-
to find first flight which has distance greater than 100 km: db.flightData.findOne({distance: {$gt: 100}})
-
for updating a document, use
updateOneorupdateMany. -
be careful about
update. this operator replace all keys of document with given key. -
for replacing whole content of a document with given data, it is prefered to use
replaceOne. -
db.flightData.find() ==> return cursor object with twenty documents from collection
-
db.flighData.find.toArray() ==> returns all documents which exist in collection.
-
same as
selectin mysql, in mongoDB we haveprojection; which helps us to select only specific keys(columns). for example: db.flightData.find({}, {name:1})this query fetches all documents exist in flightData collection and just return
name and _idkeys. if you want to exclude _id key, then: db.flightData.find({}, {name:1, _id:0}) -
in mongoDB we can store document in another document. we defined them as nested document.
-
in mongoDB up until 100 levels of nesting is allowed.
-
in mongoDB maximum size of each document is up to 16MB.
-
nested document === embedded document
-
suppose we have two document with this structure:
flights> db.flightData.find() [ { _id: ObjectId('6698dd248bb6ddad76149f48'), departureAirport: 'THR', arrivalAirport: 'MSHD', status: { description: 'on-time', distance: 190 } }, { _id: ObjectId('6698dd938bb6ddad76149f49'), departureAirport: 'GHT', arrivalAirport: 'LIU', distance: 1000, status: { description: 'delayed' } } ]
now we want a document which has description:delayed key. the query will be: db.flightData.find({"status.description":"delayed"})
-
the schema means the structure of each document.
-
mongoDB enforces no schema. Documents don't have to use the same schema inside of one collection. but it does not mean that you
can not use same schema. -
for dropping database:
>> show dbs
>> use test
>> db.dropDatabase
- to drop a collection entirely:
>> db.flightData.drop()
-
relationship between collections in mongoDB is in two ways:
- nested (embedded) document
- reference (id of related document defined as array in parent document)
-
when using
Referencefor relations; for merging relations it is possible to usejoining with $lookup.posts: { title: "sample title", postComments: ['id1', 'id2'] } comments: { _id: 'id1', name: 'sample comment' } posts.aggregate([ { $lookup: { from: "comments", localField: "postComments", foreignField: "_id", as: "postCommentData" } } ])
-
using reference method and then using lookup step from aggregate is one option but it is less perfomant than embedded document.
-
in mongoDB we can define schema validation.
-
important image from third season of mongo course of academind.
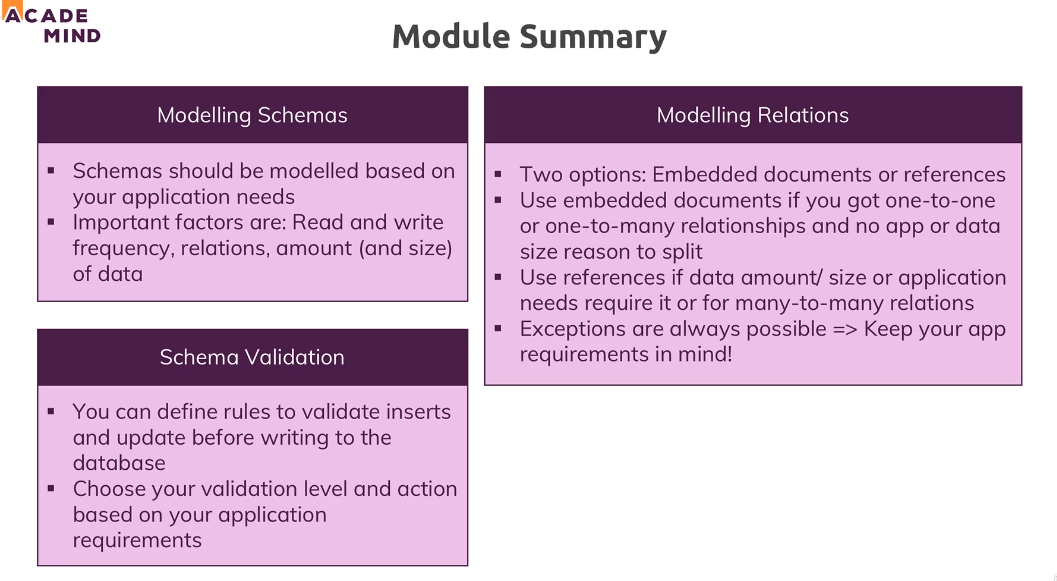
-
we can set custom path for logs and where data is stored by this options when starting mongod service:
mongod --dbpath C/users/data --logpath C/users/log/log.lognote that, log file need file name, something like: log.log
but for data, the directory name is enough. -
one of "storage options" in mongodb which is very helpful is that you can configure mongodb somehow which
consider seperate directory for each database and insert collections of each database in its subdirectory.
by default mongodb place all collections from all databases in data directory of mongodb. -
mongodb supports different storage engines, but by default it uses "wiredTiger" storage engine which is
high performant one. -
we can run mongodb as a background service by using "--fork" option. --fork is only available on mac and linux. but it is possible to run mongodb as a background service in windows also ( if when installing mongodb, you checked the option of install as service) for that run cmd as adminstrator and type:
net start mongod
in linux and macOS: mongo --fork --logpath C/users/log/log.log
note that when using --fork option, it is necessary to determine the log path.
and then how could we stop this service?
in windows -> there is two way:
way1: in cmd -> net stop mongod
way2: connect to mongodb server by shell and run these commands:
use admin db.shutdownServer()
in linux and macOS:
connect to mongodb server by shell and run these commands:
use admin db.shutdownServer()
- it is possible to define a config file for mongodb and define every possible config like
data storage path and place of log file in it. then when running mongodb you must determine the path of config file, something like:
mongod --f /{path of config file}/mongo.cfg` in this example I named this config file as "mongo.cfg" you can also name it something like: "mogo.conf" and place it anywhere you want.
38.by using "MongoDB Compass" you can explore data visually.