Scalable Vector Extensions (SVE) is ARM’s latest SIMD extension to their instruction set, which was announced back in 2016. A follow-up SVE2 extension was announced in 2019, designed to incorporate all functionality from ARM’s current primary SIMD extension, NEON (aka ASIMD).
Despite being announced 5 years ago, there is currently no generally available CPU which supports any form of SVE (which excludes the Fugaku supercomputer as well as in-preview platforms like Graviton3). This is set to change with ARM having announced ARMv9 which has SVE2 as the base SIMD instruction set, and ARM announcing support for it on their next generation cores across their entire server (Neoverse) and client (Cortex A/X) line up, expected to become generally available early 2022.
Cashing in on the ‘scalable’ moniker that drives cloud computing sales, SVE, particularly SVE2, is expected to be the future of ARM SIMD, and it’s set to gain more interest as it becomes more available. In particular, SVE addresses an issue commonly faced by SIMD developers - maintaining multiple fixed-width vector code paths - by introducing the notion of a variable (or ‘scalable’) length vector. Being SVE’s standout feature, this enables the same SVE code to run on processors supporting different hardware SIMD capabilities without the need to write, compile and maintain multiple fixed-width code paths.
ARM provides plenty of info summarizing SVE/2 and it’s various benefits, so for brevity’s sake, I won’t repeat the same content, and instead focus more on the quirks and aspects that aren’t being touted that I’ve come across, mixed in with some of my thoughts and opinions. Note that I only ever touch integer SIMD and I mostly use C intrinsics, referred to as ACLE (ARM C Language Extensions). To avoid making this article too long, I’ll focus primarily on what I’m more familiar with, which means I won’t be touching much on floating point, assembly or compiler auto-vectorization (despite how important these aspects are to SIMD). This also means I’ll be deliberately skipping over a favourite amongst SIMD examples.

Detailed information on SVE outside of core documentation is relatively scarce at the moment, as it’s largely unavailable in hardware and not yet widely coded for. As such, along with not having access to any SVE hardware, I could be wrong on a number of factors, so corrections welcome.
Note: this document was written in late 2021. ARM has since added changes to SVE which are not fully addressed in this article
Since SVE2 was announced before any SVE supporting processors have been announced by ARM, it would seem like there’s not much point in restricting yourself to just what SVE supports when writing code. And indeed, all but one of the announced cores which support SVE also support SVE2, which means you could use SVE2 as a baseline, greatly simplifying development (not to mention that ARMv9 associates with SVE2 over SVE).
The unfortunate exception here is the Neoverse V1. It’s also the only announced core (ignoring A64FX) which supports a width greater than 128 bits, so likely the only core that initially will benefit greatly from SVE (compared to NEON code). It’s unknown whether V1 or N2 will gain wider adoption in their target server market, so it’s possible that you may want to ignore specifically targeting the V1 to avoid writing separate SVE and SVE2 code paths (taking note that AWS’ Graviton3 processor is expected to be V1). As SVE2 is meant to be the more complete SIMD instruction set, and potentially a NEON replacement, I’ll largely assume an SVE2 base for the rest of this document.
On the fortunate side, there’s a good chance that your code either won’t work without SVE2, or it works with only SVE and SVE2 doesn’t provide much of a benefit, so you may not even have to worry about the distinction.
The point about V1 being the only 256-bit SVE implementation leads to the next point…
All currently announced SVE2 cores only support 128-bit vectors, which is also the minimum width an SVE vector can be. This means that you probably won’t be seeing any massive gains initially from adopting SVE2 over NEON (unless the new instructions help a lot with your problem, or enables vectorization not possible under NEON). Regardless, the point of SVE is making the adoption of wider vectors easier, so gains may eventuate in a later core, though lack of any initial gains could fail to encourage developers to port over their NEON code at first.
However, I think that we may be stuck with 128-bit for quite some time in the consumer space, whilst the next ‘large’ server core (Neoverse V2?) will probably get 256-bit SVE2 (if not wider). This is due to the popularity of heterogenous core setups (aka big.LITTLE) among consumer SKUs and SVE requiring that all cores support the same vector width. This means that CPUs will be limited to the narrowest SVE implementation amongst all cores, with the little cores likely being the limiting factor. The widest upcoming consumer core, the Cortex X2, is limited to 128-bit SVE2, possibly due to the presence of the Cortex A510 and/or A710.
Update: the Neoverse V2 reverts to a 128-bit vector width. It's unknown what width future ARM server cores adopt.
Unfortunately, ARM historically hasn’t updated their little cores as frequently as their larger cores, and with the Cortex A510 supporting a shared SIMD unit between two cores (something its predecessor doesn’t), widening SIMD doesn’t appear to be a priority there. (one possibility that could eventuate is if the little cores declare support for a wider vector width but retain narrow SIMD units - this would enable the use of wider SVE on the big cores)
{kind=link}
Servers however currently don’t have a heterogenous core setup, so being limited by a particular core type isn’t an issue yet. With that in mind, presumably, SVE isn’t about enabling 256-bit SIMD on mobile, but more about enabling the same ISA to be used in a number of different environments.
However, whilst ARM may not enable >128-bit vectors on consumer cores in the near future, it’s unknown what custom ARM cores from Apple and Qualcomm/Nuvia may bring. On the Apple side though, considering their recently announced A15 chip doesn’t support ARMv9/SVE2, which the M2 is expected to be a derivative of, and the introduction of their own AMX instruction set (in lieu of SME), it raises doubts over their interest in supporting SVE in the near future. As for Qualcomm, the first Nuvia showing is expected in 2023.
Of course, it’ll take time for developers to adopt SVE2, so it’s preferable to have a narrow implementation available, and roll out wider variants in the future.

To add a tinge of complexity, SVE and SVE2 already come with optional extensions, most of which only add a few instructions. However, SVE2’s base instruction set seems to be fairly comprehensive, so there’s a good chance you won’t have any use for these relatively application-specific extensions for many general problems.
One curiosity I have is the SHA3 extension, which only adds a single instruction, RAX1 (rotate by 1 and Xor). This is likely a holdover from the NEON SHA3 extension, which added four instructions, but transitioning to SVE, three of them have been moved to the base SVE2 set. One of the three is XAR (Xor and rotate), which now works on all element sizes. With that being present, one wonders why RAX1 couldn’t have just become as generic as XAR, and why it has to be shoved behind an extension (one can only assume it’s much simpler to Xor before rotating than go the other way around).
In terms of actual hardware support, it’s unknown what extensions CPUs will ultimately support, but from the optimization guides for Neoverse N2/V1 and Cortex A510/A710/X2, they all appear to support BFloat16 and INT8 matrix multiply, but lack the FP32/FP64 matrix multiply extension. Excluding the V1, they all also appear to support all listed SVE2 extensions (BitPerm, AES-128, SHA-3 and SM4), though BitPerm appears to be micro-coded (i.e. very slow) on the A510. Although the N2/A710/X2 listing does look like a copy/paste job from ASIMD, I presume the correct rows were copied (whilst the A510 listing seems to be somewhat confused).

Before we get any SVE2 hardware to play with, ARM keeps things exciting, having already defined their next major extension: Scalable Matrix Extensions. SME is largely considered to be a superset of SVE2, but not entirely, and is denoted as a distinct feature from SVE/2.
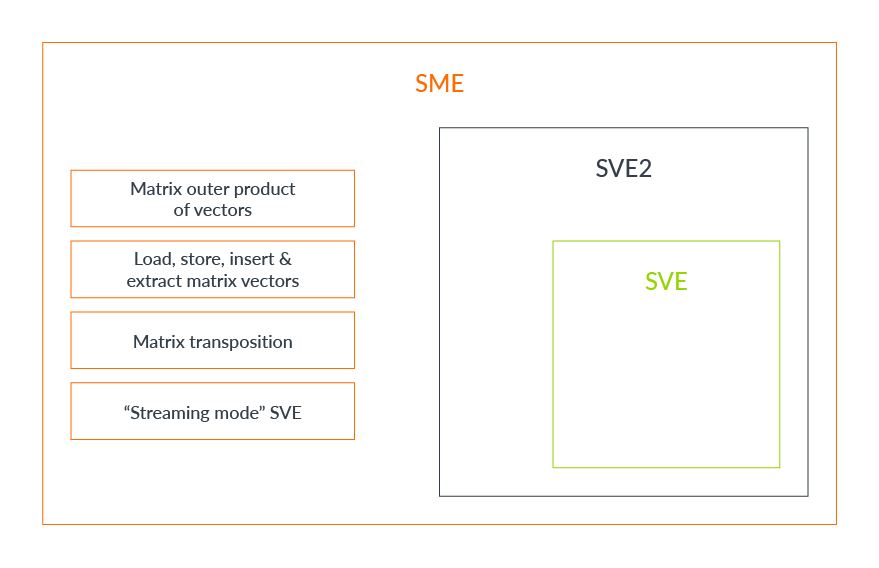{kind=link}

SME adds a ‘streaming SVE mode’ which permits the processor to have an alternative vector size. My guess is this effectively lets the processor have a latency optimised (regular) mode and a throughput optimised (streaming) mode.
From what I can tell, the following SVE2 instructions aren’t available in SME:
ADR(compute vector address)COMPACT,HISTCNT/HISTSEG,MATCH/NMATCHFADDA,FEXPAand floating point trigonometric instructions- most (all?) load, store and prefetch instructions
- FFR instructions
- anything added by an SVE extension (except some from FP64MatMul - see below)
Despite it’s aim of accelerating matrix multiplication, SME adds a few possibly useful SVE2 instructions, which are:
DUP(predicate)REVD(rotate 128-bit elements by 64)SCLAMP/UCLAMP(clamp values, i.e. combined min+max)- Quadword (128-bit)
TRN/UZP/ZIP(also available in FP64MatMul SVE extension)
SVE is defined for AArch64 only, so you don’t have to worry about supporting AArch32 + SVE (not to mention that AArch32 is being dropped on most upcoming ARM processors).
Other than offering variable length vectors, the biggest feature SVE introduces is embedded masking, aka lane-wise predication. And to ensure that knowledge of this feature spreads around, ARM makes sure that you can’t code SVE without a mask.
Consider how to add two vectors in C intrinsics for AVX512, NEON and SVE:
_mm512_add_epi32(a, b) // AVX512
vaddq_u32(a, b) // NEON
svadd_x(svptrue_b32(), a, b) // SVE
// ( svptrue_bX() sets all predicate lanes to be active )The thing to take note is the required svptrue_b32() part in the SVE code - this is a mask (or predicate) where all values are set to true (if any element in the mask were to be false, it would ‘deactivate’ the corresponding lane during the operation - the all-true mask is required when no masking is desired).
If you write a lot of code which doesn’t use predication (as I do), ARM makes you atone for such sins by requiring a svptrue_bX() for every violation (or if you’re a rebel, macro the thing away).
As for assembly, ADD actually has an unpredicated form due to the predicated version being destructive, but this isn’t available to all instructions, so you may want to keep an ‘all-true’ predicate register handy.
For reference, AVX512 makes predication optional for both intrinsics and assembly. I feel it would’ve made sense to do the same for SVE, just like they do for instructions which don’t support predication...
Despite being a major feature, there’s quite a number of instructions which don’t support predication. Anything which takes 3 vector inputs, or involves swizzling data, seem to commonly lack support for predication, in addition to instructions such as PMULL or EORBT. Also, there are some instructions that support a choice of predication or being destructive (possibly due to a limitation of coding space), although this is abstracted away in ACLE.
Many instructions which do support masking only support one type (merging or zeroing). ACLE allows zeroing on many merge-only instructions by merging into a zeroed vector, but because of this, zeroing predication may, in some cases, be less efficient than merging predication (despite what one might assume for a modern OoO processor).
This ACLE emulation of predication type doesn’t exist for a small number of cases. Most (but not all) instructions returning a predicate only support zeroing (e.g. NMATCH) whilst others only support merging (e.g. pairwise reductions).
In addition to zeroing and merge predication, ACLE has a “don’t care” _x predication variant on most instructions. As there is no equivalent in assembly, this is purely an ACLE feature.
It’s curious as to what purpose this serves, as it could be achieved by simply ignoring predication altogether. As such, why not drop the predicate argument, since it ultimately doesn’t matter?
The few instructions where you actually may want predication, but don’t care about masked out lanes (e.g. loads/stores, COMPACT etc), don’t support “don’t care” predication anyway.
On the other hand, instructions like ADDP only support merge masking, have a “don’t care” variant despite compilers having no choice in masking mode.
Perhaps it’s for instructions which require predication, but for which you may have an appropriate predicate register handy. If there were only unpredicated intrinsics, the compiler may be forced to have an all-true predicate handy when it’s strictly unnecessary. It may also be to make it easier for programmers to not have to remember what’s supported, when they ultimately don’t care.
Predicate operations seem limited to in-place bitwise logic (AND, ORR etc), NEON inherited swizzles (ZIP, TRN etc), testing and some count/propagation operations (CNTP, BRKB).
Unfortunately, operations like bitwise shift are missing, which may force you to reinterpret the predicate as a vector, operate on that, then move back to a predicate.
Shifting out all but one bit may be simulated via BRKN, for example, mask >> (svcntb()-1) (logical right shift) can be implemented with svbrkn_z(svptrue_b8(), mask, svptrue_pat_b8(SV_VL1)).
SVE provides a number of instructions to manipulate predicates, but if you’re doing something special, you may want to apply integer/vector operations to them. Unfortunately, there’s no instruction to move a predicate to a different register set - the only solution is to go through memory.
SVE provides LDR/STR instructions for spilling predicates onto the stack, however you don’t have access to these from ACLE - the manual of which mentions:
No direct support, although the compiler can use these instructions to [refill/spill] registers [from/to] the stack.
Thus you’ll have to coerce the compiler into doing what you want (unions don’t work, neither does typecasting, however you can reinterpret a pointer).
int f(svbool_t mask) {
uint8_t maskBytes[256/8]; // max predicate width is 2048/8 = 256 bits
//union { svbool_t p; uint8_t b[256/8]; } maskBytes; -- illegal
*(svbool_t*)maskBytes = mask; // pointer casting seems to be the only option
//memcpy(maskBytes, &mask, svcntd()); // very poorly optimised on current compilers
// do something unique with the predicate
int value = 0;
for(int i=0; i<svcntd(); i++) {
value += lookup_table[maskBytes[i]];
}
return value;
}NEON famously lacks an equivalent to x86’s handy PMOVMSKB instruction, often requiring several instructions to emulate. Now that SVE has predication, this becomes much more straightforward. Unfortunately, as there’s no direct predicate to integer instruction, this will need to go through memory (as described above), and you’ll need to at least consider cases where the predicate could be > 64 bits.
I don’t recall the NEON intrinsics documenting how to construct vector tuples (e.g. uint8x16x2_t type) or how to access elements within (all compilers seem to have adopted the tuple.val[] access method). SVE has documented svcreateX, svgetX and svsetX to handle this.
Another thing lacking in NEON intrinsics is the ability to specify uninitialized vectors, which is now available in SVE. There doesn’t seem to be a way to explicitly specify uninitialized predicates, though I feel that they’re less useful than uninitialized vectors.
NEON required vectors to be typed, as well as the intrinsic functions. SVE makes the latter optional via function overloading.
svuint32_t a, b;
svadd_u32_x(svptrue_b32(), a, b); // the `_u32` part can be omitted because we know a and b are u32
svadd_x(svptrue_b32(), a, b); // ...like thisACLE introduces _n_ forms to a number of intrinsics, which could cut down on a bit of boilerplate. Some instructions do support embedding immediate values, but many with _n_ forms don’t (and this doesn’t limit you to immediates), so essentially this saves you specifying svdup_TYPE(...) whenever you use a scalar value that you want broadcasted into a vector.
The functions are overloaded, so you don’t even need to specify the _n_ part, however this does require also dropping the type specifier:
svadd_u32_x(svptrue_b32(), a, svdup_u32(5)); // instead of writing this...
svadd_n_u32_x(svptrue_b32(), a, 5); // ...you can now use this...
svadd_x(svptrue_b32(), a, 5); // ...or even this
//svadd_u32_x(svptrue_b32(), a, 5); // but not thisCurrent GCC (v11) / Clang (v13) doesn’t like dealing with arrays/unions/structs/classes containing SVE types, and refuses to do any pointer arithmetic (including indexing) on them.
This includes cases where no arithmetic would be necessary in optimised code, due to all vectors fitting within addressable registers, and can be an annoyance if you need to pass around multiple vectors (e.g. in some sort of ‘state’ variable) to functions. It can also be problematic if you’re trying to do some generic templating of a common vector type for different ISAs. You could pass around a pointer instead, but this will likely require specifying explicit loads/store intrinsics, and compilers may be less willing to optimise these out.
There are vector-tuple types (note: unrelated to std::tuple), but are limited to 2, 3 or 4 vectors of the same element type. Otherwise, there doesn’t seem to be any way to create any ‘packaged type’ containing vectors unfortunately.
// invalid - cannot use a sizeless type in an array
svuint32_t tables[8];
init_tables(tables);
// correct way to do it
svuint32_t table0, table1, table2, table3, table4, table5, table6, table7;
init_tables(&table0, &table1, &table2, &table3, &table4, &table5, &table6, &table7);
// alternatively, save some typing by using tuples
svuint32x4_t table0123, table4567;
init_tables(&table0123, &table4567);Here’s an example of a templated design where SVE may seem somewhat awkward:
// example processing functions for NEON/SVE
static inline void process_vector(uint8x16_t& data) {
data = vaddq_u8(data, vdupq_n_u8(1));
}
static inline void process_vector(svuint8_t& data) {
data = svadd_x(svptrue_b8(), data, 1);
}
// this concept doesn't work particularly well for SVE
template<typename V>
struct state {
unsigned processed;
V data;
};
template<typename V>
void process_state(struct state<V>* s) {
s->processed += sizeof(V);
process_vector(s->data);
}
// explicitly instantiate NEON version
template void process_state<uint8x16_t>(struct state<uint8x16_t>* s);
// or SSE, if compiling for x86
//template void process_state<__m128i>(struct state<__m128i>* s);
// perhaps you could do this for SVE...
template<>
struct state<svuint8_t> {
unsigned processed;
uint8_t data[256]; // size of largest possible vector
};
template<>
void process_state<svuint8_t>(struct state<svuint8_t>* s) {
s->processed += svcntb();
// the following requires an explicit load/store, even if this function is inlined and the state could be held in registers; the compiler will need to recognise the optimisation
svuint8_t tmp = svld1_u8(svptrue_b8(), s->data);
process_vector(tmp);
svst1_u8(svptrue_b8(), s->data, tmp);
}I personally don’t use SIMD abstraction libraries or layers, but I imagine not being able to embed a vector within a class/union may cause issues with some existing designs.
I don’t know enough about compilers to really understand the fundamental limitations here, but it’s possible that this is just something current compilers have yet to tackle. If so, it could mean a future compiler won’t require programmers deal with this constraint.
I suppose the feature is less useful with variable length vectors, but SVE does guarantee that at least 128 bits exist in a vector, so it’d be nice if at least those could be directly accessed.
// NEON: direct indexing works
int get_third_element(int32x4_t v) {
return v[2];
}
// SVE: requires explicit intrinsics
int get_third_element(svint32_t v) {
return svlasta(svptrue_pat_b32(SV_VL2), v);
}Due to its unknown vector length, ARM doesn’t recommend loading vector/predicate constants, instead providing instructions like INDEX encouraging you to construct the appropriate vector at runtime.
However, since there’s a defined maximum length, it should theoretically be possible to define a 2048-bit vector, or 256-bit predicate and load as much as the hardware supports.
ACLE doesn’t provide direct support for this idea unfortunately (as in, similar to svdup functions).
Although NEON and SVE registers map onto the same space, ACLE provides no way to typecast a NEON vector to an SVE vector, or vice versa. I’m not sure how useful the feature may be, but it perhaps it could be useful if you have some code which only needs 128-bit vectors, or may help with gradually transitioning a NEON codebase. Under ACLE, NEON ↔ SVE value transfer must go through memory.
Interestingly, full vector reduction instructions (such as UADDV) write to a vector register, but the ACLE intrinsics give back a scalar (i.e. they include an implicit vector → scalar move).
SVE maintains AArch64’s fixed-length 32-bit instructions. Whilst a fixed-length ISA greatly helps with designing the front-end of a CPU, trying to support up to 3x 32 registers along with 8 or 16 predicate registers per instruction, and maintaining compatibility with AArch64, can lead to some unexpected contortions in the ISA which may initially confuse developers.

Despite the assembly for various instructions, that produce an output from three inputs (such as BSL), looking like they accept four registers, the first two must be identical. This basically means that the instruction only really accepts three registers, where the first input must be overwritten.
BSL z0, z1, z2, z3 # illegal - first two operands must be identical
BSL z1, z1, z2, z3 # okayThe manual mentions this naming convention was chosen to make it easier for readers, though this may initially surprise those writing assembly.
In addition, a number of SVE instructions provide the option of either allowing predication or being non-destructive, but not both.
SVE does provide a ‘workaround’ for destructive instructions - the MOVPRFX instruction, which must be placed directly before a destructive instruction (presumably to enable the decoder to implement macro-op fusion, which should be cheaper than relying on move-elimination). In my opinion, it’s a nice idea, allowing the microarchitecture to determine whether SVE should be treated as a fixed or variable length instruction set, whilst keeping defined instructions to 4 bytes. Requiring an extra 4 bytes just to work around the destructive nature of instructions does feel rather wasteful, but given the options SVE provides, I suspect this not to be too common of a problem to really matter.
In terms of actual implementation of MOVPRFX, the Neoverse V1/N2 and Cortex A510/A710/X2 optimization guides don’t list support for fusing MOVPRFX, list non-zero latency figures and don’t list it as a zero-latency instruction, so the optimisation may be unavailable on these initial SVE implementations.
It’s also interesting to note that it appears MOVPRFX can’t be paired with instructions which are ‘defined as destructive’ like SRI or TBX - it only works for instructions that are destructive as a result of limited encoding space, meaning that ‘defined as destructive’ instructions are likely to incur a move penalty if you need to retain the inputs (unless a future processor introduces zero-latency MOVs on vector registers).
Despite there being 16 predicate registers, most instructions only designate 3 bits for the predicate, only allowing P0-7 to be used for predication. P8-15 is generally only accessible to instructions which directly work with predicates (such as predicate AND), or those that yield a predicate (such as compares).
SIMD programmers maintaining fixed width or width specific problems may be concerned with the applicability of an unknown vector length system to their problem. Vector based designs, such as SVE, work well for problems like SAXPY, but if your problem involves fixed width units, or even requires different algorithms depending on the width, how feasible is an SVE implementation when you don’t know the vector width?

Some problems may be solvable with some rethinking, others may be frustrating to deal with, and others just may not work well at all (for example, the despacer problem may not scale well under SVE, at least without non-trivial redesign). In general, you may need to accept some level of inefficiency (in terms of performance and implementation complexity), but in the worst case, you may be stuck with only using the bottom 128 bits of the vector, or need to code specifically for each width you wish to support.
Given that SVE requires vector widths to be a multiple of 128 bits, it may be worth thinking about the problem in terms of 128-bit units, if possible. For example, when processing an image in terms of 8x8 pixel blocks, instead of trying to fit a block in a vector, consider processing multiple blocks, 128 bits at a time, across each ‘128-bit segment’.
This also fits in nicely with a number of SVE2 instructions, such as MATCH/NMATCH, using a ‘128-bit segment’ concept for their operation. Sadly, many instructions (such as gather, broadcast etc) don’t have the notion of a 128-bit element size, which would’ve helped, efficiency-wise, with adopting such a strategy.
Whilst there’s instructions such as ZIP1.Q and co, these require SME or the FP64 matrix multiplication extension (which don’t appear to be available on upcoming CPUs, based on Neoverse/Cortex optimisation guides). Similarly, SME adds the potentially useful REVD instruction, but support for that will be non-existent for a while.
It’s interesting to note that it’s possible to broadcast an element within each 128-bit segment, but this comes in the form of a multiply instruction, and doesn’t work with 8-bit elements.
Update: ARM has added Hybrid Vector Length Agnostic instructions as a part the SVE2p1 extension, which includes a bunch of handy 128-bit element instructions
A problem that crops up in a number of places (such as AoS ↔ SoA): you have N vectors, each containing N elements, and you with to transpose this data (i.e. take the first element of these N vectors and put them in a single vector, the next element of these N vectors into another, and so on). Consider an example where we have N streams of 32-bit words - if we have a 128-bit vector length, we can fit up to 4 words from each stream in a vector (i.e. N=4). To process these 4 streams concurrently, we read in one vector from each of the 4 streams, then transpose these 4 vectors so that we have the first 32 bits of each data stream in one vector, the next 32 bits in another, and so on.

(note: the streams may be longer than shown and exist in non-consecutive memory locations, so LD4 cannot be used here)
If the vector length was 256-bit instead, we’d ideally be processing 8 streams at a time.
This raises an issue: reading N vectors requires knowing N in advance, as you need to allocate the appropriate number of registers. Traditional transposition algorithms (transpose halves, then transpose quarters etc) are width specific, and are designed for power-of-2 vector widths, which doesn’t translate well to variable length vectors.
The other option is to ditch the transposition idea and instead rely on gather, which would allow one implementation to work on all vector sizes. Whilst likely simpler to implement, performance may be a concern, particularly as the vectors get longer.
A compromise could be made:
- implement 5 power-of-2 variants, using traditional transposition, and a gather variant for other sizes. This still requires you to write 6 implementations however
- Considering limitations on number of available registers, you may not need an implementation for every power-of-2. Alternatively, you can choose to ignore the larger vector sizes (focusing primarily on 128, 256 and 512-bit) and only optimise for 1024/2048 bit when such a machine eventuates
- use 64-bit element gathers (unfortunately an ideal 128-bit element gather doesn’t exist) and transpose down to the element size you desire. This is obviously more expensive than traditional transposition, but cheaper than a full gather, whilst enabling you to stick to one implementation
- If you have separate 64-bit pointers, a 64-bit gather would be your only choice as a 32-bit gather may be unable to reference all sources
- Since gather can only be done with 32 or 64-bit elements, if your element size is smaller (i.e. 8/16-bit), you’ll also need to take this approach over a pure gather

Trying to shuffle data around in a vector becomes a lot more difficult when you don’t know where the boundaries (length) lie. This will likely cause complications with algorithms which heavily depend on data swizzling/permutation.

Despite offering just enough tools to get the job done (i.e. the TBL instruction), SVE2 does little to help on this front, and swizzling seems to be an aspect not well considered. Particularly egregious is that a number of SVE extensions (e.g. FP64MatMul, SME) add new swizzling instructions to cater for the narrow use case the extension is targeting, as clearly the ones included in the base SVE2 instruction set aren’t considered sufficient.
NEON had a number of useful swizzling instructions, and I think makes it overall fairly good ISA at swizzling. SVE2 inherits many of these, often with little change, and because of that, it’s much more problematic. To provide an example, let’s take a look at the EXT instruction, which fits this description:
NEON forgoes byte level shifting instructions (such as those in x86’s SSE2) in favour of the EXT instruction, which can be used for both left and right shifts, given appropriate inputs. Note that EXT naturally shifts a vector to the right, but left shift can be done by subtracting the desired shift amount from 16 (the byte width of NEON vectors).
SVE2 carries over this instruction with the same functionality, which makes right shifting just as trivial. However, left shifting now becomes more difficult as you don’t know the vector length in advance (so a 16-n approach doesn’t work), and the shift amount must be an immediate value (so a svcntb()-n solution isn’t possible).
To do a left byte shift, your options may be limited to:
- write a version of this instruction for every possible vector width, and switch() on the vector width - this may be sensible if this is a critical instruction in a hot loop, where you may want to implement 16 copies of the loop and select the version based on vector width
- write vectors out to memory, then load it back with an appropriate offset
- reverse (
REV) the vector, do a right byte shift (EXT), then reverse again - create a mask then use
SPLICE - for shifting by 1, 2, 4 or 8 bytes,
INSRis also an option
It probably would’ve made sense to include a left-shift version of EXT, or perhaps a byte shift which accepts a variable (non-immediate) shift amount.
Due to the limited number of useful swizzling instructions available, developers may be encouraged/forced into using the all-purpose TBL/TBX to get data into the correct place. The SVE manual explicitly mentions these instructions are not vector length agnostic, which can make it a little awkward to use, as well a potential source of subtle bugs.
SVE’s TBL supports non 8-bit element sizes (in contrast with NEON), and for these, the instruction is fairly straightforward.
However, for 8-bit elements, the distinction between TBL and TBX blurs a lot. In theory, the two instructions do different things, but in canonical SVE code, you can’t rely on that being the case. If the vector width is 2048-bit, both instructions do exactly the same thing, so unless you have separate code paths for different vector lengths (or some other length checking/controlling mechanism), there is no point in ever using TBX with 8-bit elements.
Similarly, you can’t rely on TBL‘s zeroing feature (e.g. by setting the bytes you want zeroed to 0xff in the index vector) as it may never be triggered with 2048-bit vectors.
Of course, I fully expect there to be software which doesn’t heed this, particularly since 2048-bit vector machines seem unlikely in the near future, leading to possible unexpected bugs on future machines.
Zeroing (and merging) via predication may have been a better approach, but why come up with some new SVE-esque way of doing things when you can just copy TBL and TBX from NEON and call it a day?
(also known as the 2 source vector TBL from SVE2, but ACLE refers to it as ‘TBL2’, so I will as well)
As with (single vector) TBL and TBX, this instruction pretty much works the same way it does in NEON, but as with EXT, it’s also much more awkward to use than the NEON version. To reference elements from the second vector, you need to know the vector length, and then add that to the indicies that refer to elements of the second vector. This means that you’ll almost always need a bunch of instructions to prepare the index vector for TBL2.
Following on from the point in the previous section, using TBL2 with 8-bit elements is completely unusable unless you have vector length checks in place. For 2048-bit vectors, TBL2 can reference none of the elements of the second vector.
It probably would’ve been better if the top bit of each element was used to indicate whether it pulls from the first or second source vector. Alternatively, predication could be used to select the source vector (similar to the SEL instruction). Both of these are likely easier than having to do a count, broadcast and or-merge to reliably select the desired elements.
ARM notes that the permutation instructions TBL, TBL2 and TBX aren’t vector length agnostic. This is understandable, particularly if you want a full vector shuffle/permute, but one does wonder whether limiting the scope may have helped with problems that scale in terms of 128-bit units (such as VPSHUFB in x86 which restricts shuffling to the 16 bytes per lane).
On the other hand, full vector permutes are certainly a boon to those used to dealing with the hassles of 128-bit lanes on x86’s AVX.
However, there’s another concern with allowing full width permutes: ARM notes in a presentation that many of the widen/narrow instructions had their behaviour changed to avoid transferring data across long distances. However the TBL family by definition must support transferring data across the entire vector, even if you’re not actually using it for that purpose. This raises a concern with potential performance penalties for using the instruction.

x86’s AVX implementations usually have cross-lane penalties with instructions that cross 128-bit lane boundaries, suggesting that this isn’t just a problem with ARM designs.
However, looking at the Neoverse V1 optimization guide (and assuming accurate figures), there doesn’t appear to be any penalty with a 256-bit (SVE) TBL over a 128-bit (NEON) one. Similarly, other instructions which may need to move data across distances, such as REV, show no penalty.
Aside: it’s interesting to note the way the ALUs are arranged - the Neoverse V1 has 4x 128-bit NEON ALUs which can be arranged into 2x 256-bit for SVE. In such a case, it appears that port V2 is folded into V0 and V3 into V1 - in other words, 128-bit instructions which can be issued to ‘V02’ (i.e. ports V0 and V2) will turn into a 256-bit instruction issued only to V0 (since V2 and V3 are ‘unavailable’ under SVE).
TBLin ASIMD is noted as V01, and is also V01 for SVE, suggesting that the Neoverse V1 actually has 2x 256-bit shuffle ports, which simply get restricted to 128-bit when executing NEON, as opposed to the more traditional 4x 128-bit → 2x 256-bit setup. Looking at the Cortex X2 optimisation guide (4x 128-bit SVE2), the ASIMDTBLoperates the same, but SVE’sTBLnow operates on all four 128-bit ports. This matches the stated Neoverse V1 behaviour, but is weird for SVE’sTBLto have double the throughput of ASIMD’sTBLdespite doing the same operation. Another interpretation is that at least some of the published figures for SVE’sTBLare incorrect.
The A64FX guide also doesn’t show a penalty for a 512-bit TBL over ASIMD, but it is noted that TBL always has a higher latency relative to other SIMD instructions on that platform.
It’s entirely possible that moving data across the entire vector just isn’t a problem at current SIMD widths, but could be problematic on wider vectors, or maybe just isn’t that much of a problem period. It’s also unknown whether TBL2 would have any penalty over TBL for width >=256-bit, but speculating from existing ARM architectures, perhaps not.
Update: ARM has now added instructions like TBLQ as part of their Hybrid Vector Length Agnostic instructions in the SVE2p1 extension
SVE adds support for gather/scatter operations, which helps vectorize a number of problems that may otherwise require a lot of boilerplate shuffling. It also can help alleviate issues with lack of good in-register swizzling, since data can be shuffled to/from memory, however it’s not without its downsides:
- limited to 32/64-bit element sizes (note that the 8/16-bit variants only support sign/zero extension to 32/64-bit)
- poor performance due to being bottlenecked by the processor’s LSU (and likely being executed as multiple µops), as it’s effectively a scalar operation in terms of performance. In other words, performance decreases linearly as the vector width increases
- still requires index generation like
TBL
Perhaps trying to swizzle data, when you don’t know the length of the vector, is all just too hard. Perhaps we can just limit the vector width instead and pretend to be using a fixed length vector ISA?
SVE does actually provide some support for operating with constrained vector sizes (such as a multiple of 3, or restricting it to a power of 2). Unfortunately, this is done primarily via predication (and support from some other instructions like INCB) and does not help with swizzling instructions (most of which don’t support predication to begin with).
There does, however, seem to be a mechanism for actually setting a vector length, but I don’t think it’s available at EL0 (user-space), so an interface must be provided by the OS (prctl(PR_SVE_SET_VL, ...) under Linux). Note that the contents of vector registers become unspecified after changing the width, and compilers are likely not expecting such changes to occur during execution, so it’s not something that can be changed on a whim. Also, you can only set a vector size smaller than, or same as, what is supported on the hardware; you can’t just set an arbitrary sized vector, such as 512-bits, and expect the hardware to magically deal with it, if the hardware only supports 256-bit vectors.
Due to the downsides and the design goal of this mechanism, it seems like this isn’t aimed at easing development, but rather, perhaps serve as a compatibility measure (e.g. allow the OS to run an application with a limited vector width if the application wasn’t designed with wider vectors in mind), or maybe for allowing live server migrations.
However, since the vector length is expected to remain constant throughout execution, you can do checks on the vector length and either have multiple code paths, and/or outright reject supporting some configurations.
Alternatively, since the register files are shared, you can use NEON instructions if you don’t need more than 128 bits, although SVE support doesn’t seem to guarantee NEON support. ACLE also doesn’t help as it doesn’t provide a mechanism to typecast between the two vector types.
Update: ARM has now disallowed non power-of-two widths in an update (see C215), which addresses a number of concerns mentioned below
SVE allows any vector width that’s a multiple of 128-bit up to 2048 bits, with no further restriction. This means that a system with 1664-bit vectors would adhere to SVE specifications. I don’t know whether anyone will ever make a machine with such an unusual width, but it undoubtedly enables such flexibility on the hardware side. Regardless, the programmer still has to ensure their code works for such cases to be fully ‘SVE compliant’ (also keep in mind that width can be adjusted down by privileged software, so a system with 512-bit vectors could be configured to operate at 384-bit width). My guess is that ARM is banking heavily on the ‘scalable’ part working well to minimise the impact this has on the programmer, whilst simultaneously maximising hardware configurability.
Unfortunately, not only is SVE not fully width agnostic, this does come with a number of caveats, particularly with dealing with non-power-of-2 widths:
- memory alignment: if you already do this, it’s probably not worth trying too hard with SVE. I guess you could choose to only bother if the vector width is a power of 2, or maybe try some alignment such that at least some fraction of loads/stores will be aligned (assuming desired alignment boundaries are always a power of 2). It’s possible that trying to cater for alignment isn’t so much of a concern with newer processors (as misalign penalty seems to be decreasing), though interestingly, the addition of memcpy/memset instructions in ARMv9.3 catering for alignment seems to suggest otherwise
- power-of-2 bit hacks: multiplication/division by vector width is no longer a bit shift away, and if you have code which computes multiples/rounding or similar, such code may need to be revised if you previously assumed vectors would always be a power-of-2 in length
(there’s an instruction to multiply by vector width though (
RDVL); it may have been handy to have an instruction which does a modulo/divide by vector width without needing to invoke a slow division instruction or resort to runtime division hacks) - divide-and-conquer strategies: algorithms such as transposition or custom reductions may require more care as you can’t always repeatedly halve the vector width
- common multiple: one cannot assume that all possible vector sizes will fit neatly into a statically-chosen smallish array (the lowest common multiple of all SVE vector sizes is 3,843,840 bytes). This can complicate some matters, such as static AoSoA setups
- bottlenecks on a 128-bit vector machine are likely very different to that of a 2048-bit vector machine. As vectors increase in size, cache/memory bandwidth can become more of a bottleneck, but this may be difficult to predict without benchmarking on a wide vector machine
Currently announced/available SVE/2 widths are 128, 256 (Neoverse V1) and 512 bits (A64FX); it’s unknown if a 384 bit SVE implementation will ever eventuate (seems unlikely to me, but ARM felt it necessary to allow it).

On the x86 side, the first AVX512 implementation had an interesting quirk: the frequency of the processor may throttle when executing ‘heavy 512-bit code’. As the vector width is programmer-selectable there, this allowed code to be either latency focused (keeping to shorter vectors) or throughput focused (using longer vectors).
SVE doesn’t readily allow the programmer to select the vector width, which means this choice isn’t available. This could limit hardware implementations to select widths that have a limited impact on frequency/latency. The Neoverse V1 optimisation guide doesn’t provide info on performance when the SVE width is restricted to 128-bit, so it’s yet to be seen if a processor would perform differently depending on the vector width set - particularly with instructions that may not scale so well with vector length (e.g. gather/scatter).
Interestingly, ARM introduces a ‘streaming mode’ as part of SME, which enables it to have a longer vector width relative to SVE, and may be a solution?
Apart from being variable length and supporting predication, many instructions in SVE2 mirror that of NEON, which makes understanding easy for anyone familiar with NEON, and helps with translating code.
ARM does highlight a key change made from NEON to SVE2 in how widening/narrowing instructions work:

Not highlighted, but another difference would be that all comparisons yield a predicate result instead of a vector; if the old behaviour is desired, it has to be constructed from the predicate.
Some NEON instructions also seem to be missing SVE2 equivalents:
ORN(bitwise or-not): replaceable withBSL2Nat the cost of being destructiveCMTST(bit-test compare): unsure why this was removed; you’ll probably need to take the manual approach (AND+CMPEQ) with this one- vector ↔ scalar moves, e.g.
SMOV/UMOVandINS: for extracting elements from a vector,LASTA/LASTBcould work. XTN:UZPwith a zero vector seems to do the same thing- 3-4 vector
TBLhas been removed, as well as multi-vectorTBX; though inconvenient to have removed, those instructions typically performed poorly, and the implementation of 2-vectorTBLin SVE2 feels somewhat iffy (at least with 8-bit elements). - multi-vector
LD1andST1: probably not enough benefit over issuing the load/store instructions individually
ARM’s own migration guide can be found here.
Some developers may be familiar with libraries like sse2neon, which can help transition code written in one ISA to another. At the moment, I don’t know of any tools which can translate intrinsics into SVE/2.
Being variable width, translating a fixed width vector ISA into SVE/2 will likely be more challenging than what a simple header library can achieve.
However, translating the other way around may eventually be possible with something like SIMDe.
I may as well make a comment about x86’s closest, very well received competing SIMD extension. The overall comparison between NEON ↔ SSE largely remains, with the ARM side feeling more orthogonal in general (with fewer odd gaps in the instruction set), but has less “Do Tons of Stuff Really Fast” style instructions that x86 has.
SVE2 ↔ AVX512 has been closing the gap however. AVX512 plugs many of the holes that SSE had, whilst SVE2 adds more complex operations (such as histogramming and bit permutation), and even introduces new ‘gaps’ (such as 32/64-bit element only COMPACT, no general vector byte left-shift, non-universal predication etc).
SVE‘s handling of predication feels more useful than AVX512’s implementation - whilst support for it isn’t as extensive, the idea of the WHILELT instruction and FFR are a great use of the feature, allowing it to be easily used for trailing element handling and even speculative loading (useful for null terminated strings, for example).
AVX512 may seem more broken up, due to all its extensions, but x86 has the benefit of there being few implementations and low variability, making this perceived fragmentation mostly illusory in practice (currently, Skylake-X and Ice Lake are the major compatibility targets; though the programmer must be aware of this). It’s unknown how SVE/2 will fare in that regard, but having a solid base instruction set makes it less likely an issue.
As for the elephant in the room, the key difference between the two is that AVX512 allows the programmer to specify the vector width (between 128/256/512 bit) but requires hardware to support all such widths, whereas SVE2 allows the hardware to dictate the width (128-2048 bit) at the expense of the programmer having less control over such.
In terms of hardware support, it’s expected all future ARM designed CPUs will support SVE2 across all A-profile products, albeit many possibly limited to 128-bit vectors, whilst AVX512 is somewhat of an unknown with Intel being uncertain about support for it in their latest client processors. AVX512 does currently have the benefit of actually being available to consumers for a few years though.
Being new, there isn’t a lot of info out there about SVE at the moment. ARM provides some documentation, including an instruction manual, as well as an ACLE PDF; the descriptions in the latter are rather spartan, so you’ll often need to refer back to the assembly manual for details.
SVE/2 has recently been added to ARM’s Intrinsics page.
The SVE documentation in Linux is worth checking out for ABI details, if Linux is your target platform.
The latest GCC and Clang/LLVM versions have support for SVE2 via intrinsics. I haven’t tested armclang (which I presume wouldn’t have any issues), but have tested GCC 10 and Clang 12 (I’ve found issues in Clang 11 that seem to be fixed in 12, so I suggest the latter). I have not tested auto-vectorization, neither have I looked at assembler support, but recent-ish GNU Binutils’ objdump handles it fine.
I don’t know about support in non C/C++ compilers, but I’d imagine it to be fairly minimal at best, at present.
Without SVE hardware available, your only option is to use an emulator. Even if you have SVE hardware, you’ll probably still want to use an emulator - just because your code works on your SVE CPU doesn’t mean it’ll work on a CPU with a different vector width. I can see this latter point being a not-unlikely source of bugs; the additional complexity of getting something to work with arbitrary sized vectors can mean unnoticed bugs if code isn’t verified against a range of vector sizes.
ARM provides their ARM Instruction Emulator, which unfortunately, isn’t open source and only released for select AArch64 Linux hosts (which shouldn’t be too surprising). This means that you’d likely have to run it on an ARM SBC (of which many aren’t particularly performant), a smartphone which can run a Linux container, or rent an ARM instance from a cloud provider (which is becoming more available these days).
One thing to note is that if you’re doing dynamic dispatch (e.g. testing SVE availability via getauxval in Linux), you’ll need to bypass the check when testing because ARM’s emulator doesn’t intercept that call.
If you need to set a vector width dynamically (i.e. via prctl)… I guess you’ll have to hope it works in practice unless you have an actual test machine.
Another option may be to use qemu, or other suggestions from ARM, but I haven’t tried these myself. It seems like ARM’s own IE doesn’t support big-endian, so you may need to use qemu to test compatibility if big-endian support is a concern.
From what I can tell:
- Linux: SVE supported in 4.15, and SVE2 supported in 5.2
- FreeBSD: in progress?
- Windows: not listed as a processor feature
- macOS: probably only supported once an Apple chip supports it; I can’t find a reference for available sysctl values
- iOS: probably similar to above; seemingly no interface to detect processor features
- Android: not documented in the NDK, however Linux’s
getauxvalcall can be used (or parse /proc/cpuinfo as Google’s cpu_features library does), so is supported as long as the kernel version is new enough. Based on version, from what I can tell, SVE may be supported on Android 10 if running Linux 4.19, whilst SVE2 may be supported on Android 11 when running Linux 5.4
Amongst popular OSes, it seems like only Linux/Android really supports SVE so far.
SIMD programmers have often been annoyed with having to deal with multiple SIMD instruction sets, not to mention multiple ISAs on the same platform (see SSE/AVX/AVX512). SVE aims to address the latter problem (at the expense of introducing yet another ISA) with a different approach, whilst providing greater flexibility to CPU implementers and new capabilities to programmers. Towards that goal, it does feel like SVE largely achieves it with a reasonable balance of concerns, despite all the compromises this entails.
To enable this, SVE has to operate at a higher level of abstraction relative to fixed length SIMD ISAs. In addition to possibly adding some overhead, it inevitably makes this ISA more opinionated, meaning that it can simplify use cases which suit its model whilst making others more challenging to deal with. And SVE does feel like it’s more focused on specific scenarios than NEON was.
Depending on your application, writing code for SVE2 can bring about new challenges. In particular, tailoring fixed-width problems and swizzling data around vectors may become much more difficult when the length is unknown. Whilst SVE2 should provide enough tools to get the job done, it’s underwhelming support for data swizzle operations feels poorly thought out and leaves much to be desired. On the other hand, SVE2 shares a lot of functionality with NEON, which greatly simplifies adopting existing NEON code to SVE2.
Unfortunately, current implementations of SVE intrinsics can make software wrappers more restricted, particularly for those hoping to use one to unify the multiple SIMD ISAs out there. I can also see subtle bugs potentially cropping up for code not tested against a variety of vector lengths, particularly since SVE allows for great flexibility in that regard, which means your development pipeline may need to incorporate an instruction emulator for testing, regardless of hardware availability/support.
Finally, SVE2’s main selling point over NEON - the ability to have >128-bit vectors on ARM - will likely not eventuate on many processor configurations for quite some time. As such, and in addition to slow software/OS adoption, it could be a while before we get to see the true extent of what SVE is capable of, and how well the ‘scalable’ aspect plays out.
Many instructions are unpredicated or have unpredicated forms. For those that require a predicate,
PTRUEbasically sets a mask appropriately, so you can get the same effect by dedicating it as a "no masking" predicate, but with more flexibility.I don't really have any objections to the choices made in assembly/machine-code regarding predication, my concern is with the weird decision to have _x in ACLE.