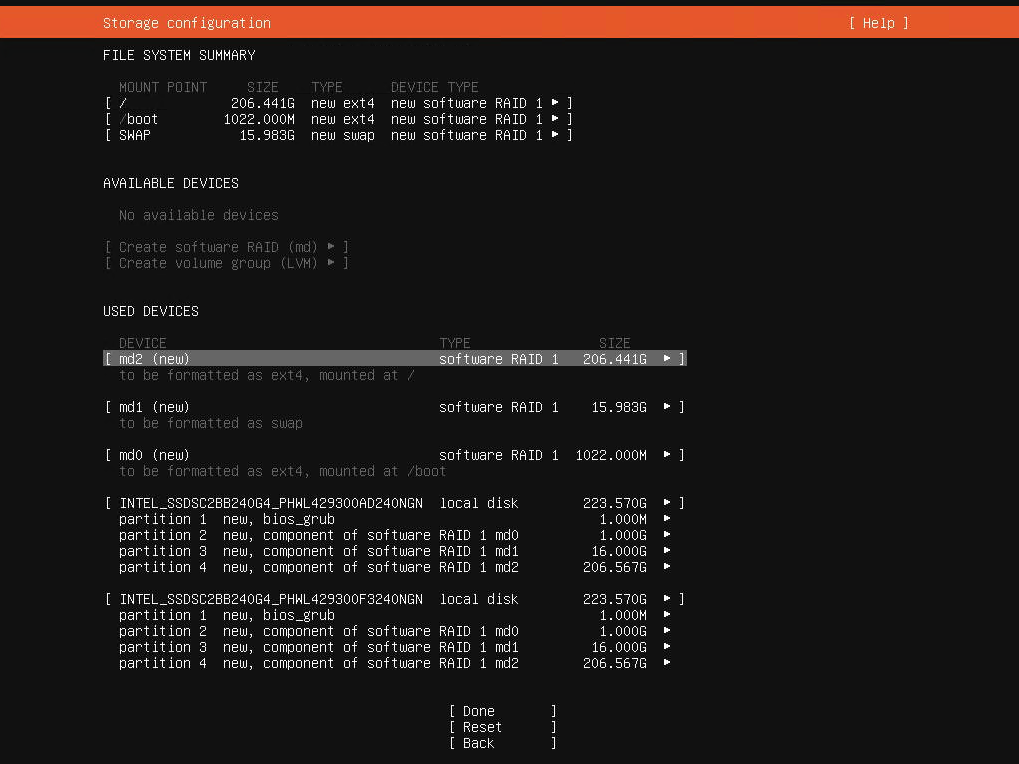
Let's start with the basics: the official guide by Ubuntu (https://ubuntu.com/server/docs/install/storage) is outdated/wrong. And as of March 2021 it's possible that there's a bug as well with how the bios_grub partitions are created when using multiple disks.
Now on to the solution:
- Select "Custom storage layout" when you reach the storage configuration step of the installer.
- If the disks have existing partitions, click on each disk under AVAILABLE DEVICES and then select REFORMAT. This will (temporarily) wipe out the partitions.