This set of benchmarks explores the impact on a Node.js HTTP API server when some responses take more cpu than others. The requests are to a JSON page that calculates a random fibonacci sequence between 1 and 30. The server is using node-perfectapi with a feature that scales the http server across available cpus, while leaving the user's API code in the main Node.js process.
In the red series, the http server is running in the same process as the Fibonacci calculations. In the green series, the handling of all of the http web server stuff has been moved to separate node workers. In both cases, the Fibonacci calculations occur in a single thread in the main (master) Node process.
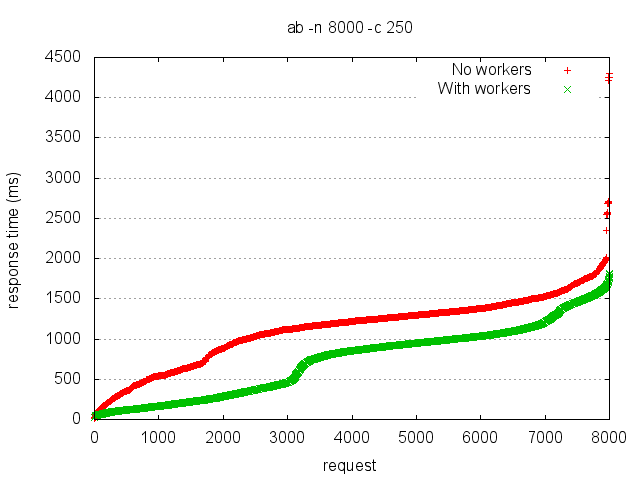
Now obviously the red series is going to be slower than the green series (because it is restricted to a single cpu for both http requests/responses and the calculation). What is interesting to me is the size of that difference. I don't think the size can be explained by just the lack of CPU power - it is also a lack of parallelism. The green series is able to parse and respond to requests independently of the Fibonacci calculation, and this results in improved response times.
Because of that, the red response times for all requests pay the cost of the slow ones (because the http server cannot process a new request until the calculation is complete on the last one). There are many ways to address this, and this set of benchmarks attempts to explore some of them.
Next, I added a single long-lived worker process just for the Fibonacci calculation. This should give the red series the parallelism it was missing before, and give both series an equivalent amount of CPU devoted to the calculation.
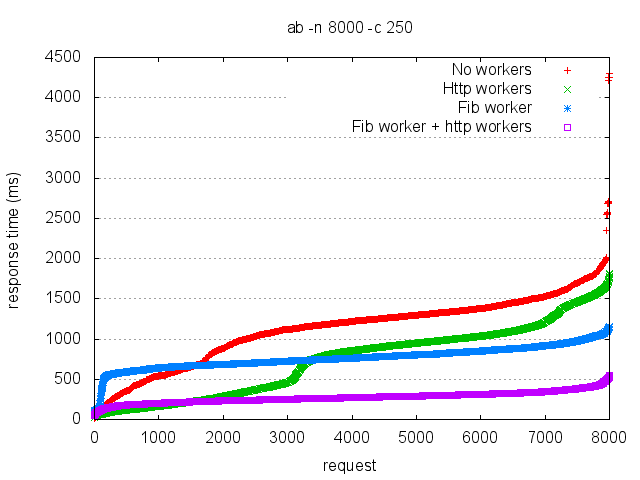
In addition to the original red and green, there are two new series in this chart. The blue series has the same code as the red, but I've given the Fibonacci calculation its own worker process. The blue line is almost flat, indicating a very consistent (but slow) response time. There are a couple of unexplained characteristics of the blue series - why does it spike so quickly in the beginning, and why is it so flat the rest of the time?
[Update: I think it spikes so quickly because the fib process quickly becomes saturated and cannot handle new requests. Once it spikes, the response time is flat because it is limited by the fib process].
The purple series adds an additional worker process for the Fibonacci calculations to the original green series. It also has an unexplained characteristic - why is it better over time than the green series? After all, the calculation was basically in its own process already (because the http was offloaded). I don't have a good answer.
Despite the unexplained pattern to the 2 new series, they do show the same relation to the original series, i.e. the one with the http workers still enjoys better response times.
Finally, for completeness I have one more set of benchmarks:
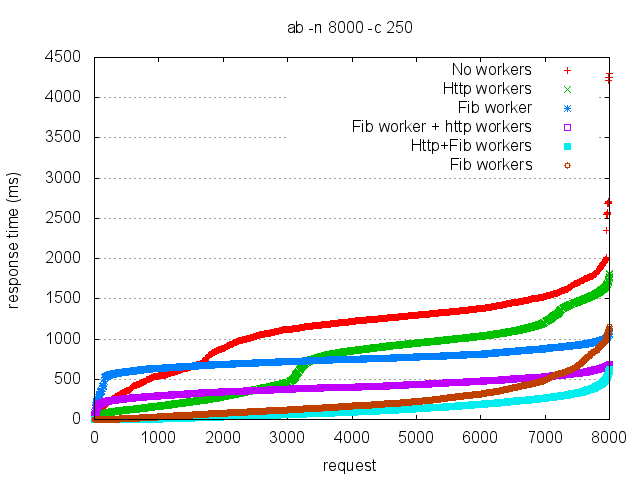
This set shows what happens when I fork 1 Fibonacci worker process for each CPU on my 8 core laptop. The brown line is 8 Fib workers with one main process handling everything else. The cyan line is 8 Fib workers + 8 http workers + a main process in the middle. Once again, the http workers have a positive impact on response time (50% within 92ms vs. 50% within 167ms).
BTW, all cores on my laptop are maxed out under both these last 2 series (none of the previous tests did that). Its kind-of fun to see that.