-
-
Save MichelleDalalJian/453c68e7fde2b2996c8b598c988c09d3 to your computer and use it in GitHub Desktop.
| from bs4 import BeautifulSoup | |
| import urllib.request, urllib.parse, urllib.error | |
| import ssl | |
| import re | |
| ctx = ssl.create_default_context() | |
| ctx.check_hostname = False | |
| ctx.verify_mode = ssl.CERT_NONE | |
| url = "http://py4e-data.dr-chuck.net/known_by_Bryce.html" | |
| #to repeat 7 times# | |
| for i in range(7): | |
| html = urllib.request.urlopen(url, context=ctx).read() | |
| soup = BeautifulSoup(html, 'html.parser') | |
| tags = soup('a') | |
| count = 0 | |
| for tag in tags: | |
| count = count +1 | |
| #make it stop at position 3# | |
| if count>18: | |
| break | |
| url = tag.get('href', None) | |
| print(url) |
thanks. this is very helpful
I wanted to ask you something. I could not understand the phrase 'scan for a tag that is relative to the first name in the list and repeat the number of times'.
Does this 'first name' keeps on changing with every 'count' till a particular 'position'?
I'm new to Python HTML portion. Can someone please help me?
I didnt understand the step to make it stop at position 3
who can run it at position 18 ?
Probably my code almost does according to the instructions
import urllib.request, urllib.parse, urllib.error
import ssl
from bs4 import BeautifulSoup
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter URL -')
repeat = int(input('Enter number of repeatations: '))
position = int(input('Enter the link position: '))
#to repeat desired times
for i in range(repeat):
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
tags = soup('a')
count = 0
for tag in tags:
count = count +1
#stopping at desired position
if count>position:
break
url = tag.get('href', None)
name = tag.contents[0]
print(name)it was helpful
Probably my code almost does according to the instructions
import urllib.request, urllib.parse, urllib.error import ssl from bs4 import BeautifulSoup ctx = ssl.create_default_context() ctx.check_hostname = False ctx.verify_mode = ssl.CERT_NONE url = input('Enter URL -') repeat = int(input('Enter number of repeatations: ')) position = int(input('Enter the link position: ')) #to repeat desired times for i in range(repeat): html = urllib.request.urlopen(url, context=ctx).read() soup = BeautifulSoup(html, 'html.parser') tags = soup('a') count = 0 for tag in tags: count = count +1 #stopping at desired position if count>position: break url = tag.get('href', None) name = tag.contents[0] print(name)
you've done a wonderful job brother
Probably my code almost does according to the instructions
import urllib.request, urllib.parse, urllib.error import ssl from bs4 import BeautifulSoup ctx = ssl.create_default_context() ctx.check_hostname = False ctx.verify_mode = ssl.CERT_NONE url = input('Enter URL -') repeat = int(input('Enter number of repeatations: ')) position = int(input('Enter the link position: ')) #to repeat desired times for i in range(repeat): html = urllib.request.urlopen(url, context=ctx).read() soup = BeautifulSoup(html, 'html.parser') tags = soup('a') count = 0 for tag in tags: count = count +1 #stopping at desired position if count>position: break url = tag.get('href', None) name = tag.contents[0] print(name)you've done a wonderful job brother
I'm glad that it helped you guys
Probably my code almost does according to the instructions
import urllib.request, urllib.parse, urllib.error import ssl from bs4 import BeautifulSoup ctx = ssl.create_default_context() ctx.check_hostname = False ctx.verify_mode = ssl.CERT_NONE url = input('Enter URL -') repeat = int(input('Enter number of repeatations: ')) position = int(input('Enter the link position: ')) #to repeat desired times for i in range(repeat): html = urllib.request.urlopen(url, context=ctx).read() soup = BeautifulSoup(html, 'html.parser') tags = soup('a') count = 0 for tag in tags: count = count +1 #stopping at desired position if count>position: break url = tag.get('href', None) name = tag.contents[0] print(name)
Amazing, thank you so much
Probably my code almost does according to the instructions
import urllib.request, urllib.parse, urllib.error import ssl from bs4 import BeautifulSoup ctx = ssl.create_default_context() ctx.check_hostname = False ctx.verify_mode = ssl.CERT_NONE url = input('Enter URL -') repeat = int(input('Enter number of repeatations: ')) position = int(input('Enter the link position: ')) #to repeat desired times for i in range(repeat): html = urllib.request.urlopen(url, context=ctx).read() soup = BeautifulSoup(html, 'html.parser') tags = soup('a') count = 0 for tag in tags: count = count +1 #stopping at desired position if count>position: break url = tag.get('href', None) name = tag.contents[0] print(name)
You're really awesome, thank you!!
Probably my code almost does according to the instructions
import urllib.request, urllib.parse, urllib.error import ssl from bs4 import BeautifulSoup ctx = ssl.create_default_context() ctx.check_hostname = False ctx.verify_mode = ssl.CERT_NONE url = input('Enter URL -') repeat = int(input('Enter number of repeatations: ')) position = int(input('Enter the link position: ')) #to repeat desired times for i in range(repeat): html = urllib.request.urlopen(url, context=ctx).read() soup = BeautifulSoup(html, 'html.parser') tags = soup('a') count = 0 for tag in tags: count = count +1 #stopping at desired position if count>position: break url = tag.get('href', None) name = tag.contents[0] print(name)
This is crazy man, wonderful.
I've was wondering how to code this, but your code helped me a lot.
I understood each and every line.
Thank you.
thank you - Your code helps me also a lot to find the right finetuning issues for my code.
showing error at bs4
i got a question for the line url = tag,get ('href', None)
if i put a different value like x = tag.get ('href', None)
i get a totally different answer, do you why this is?
showing error at bs4
Can you please share your error?
i got a question for the line url = tag,get ('href', None)
if i put a different value like x = tag.get ('href', None) i get a totally different answer, do you why this is?
If you want to use any other variable name, then you have to change all 'url' to the variable name of your choice. In your case if you change only that line, that line will be inside for loop and for next iteration it can not fetch reference from previous url. for better understanding please check the first line inside the for loop once.
@supriyoss
why the code always show the trackback like" line 16, in , soup=BeautifulSoup(html, 'html.parser')?
thank you
@Blake8296 It can be a variety of things, check your import, installed parser and if possible post the whole error line here, I'll be happy to help.
I am getting this error
File "bs4/element.py", line 1565, in _normalize_search_value
if (isinstance(value, str) or isinstance(value, collections.Callable) or hasattr(value, 'match')
AttributeError: module 'collections' has no attribute 'Callable'
please help with this. many thanks
@Oberoi321 Callable() is a method not a property. You missed parenthesis. Try - collections.Callable()
@supriyoss - thank you, but 1) this is the code in the bs4 package, not my code, that seems to throw an error. I would imagine everybody who uses bs4 would get this error? 2) i made your change in the element module of the installed bs4 package as suggested and the error is still as below
File "/Users//Documents/bs4/element.py", line 1565, in _normalize_search_value
if (isinstance(value, str) or isinstance(value, collections.Callable()) or hasattr(value, 'match')
AttributeError: module 'collections' has no attribute 'Callable'
I'm confused, it seems to be a problem with the bs4 package rather than my code ...?
@Oberoi321 Ok now I understand, actually I missed it first time, sorry for that. In element.py try changing collections.callable to collections.abc.callable , sorry for my negligence.
Otherwise you can degrade your bs4 package and the previous code will run flawlessly, it is a bug in new bs4 package. Sorry again.
@supriyoss thank you ! to be sure, i downloaded the latest package from the pypi org site and it works :)
Can anyone assist me, my code for the assignment works but does not produce the correct result? Can anyone point me in the right direction? Am I missing something in my code?
Start at: http://py4e-data.dr-chuck.net/known_by_Summer.html
Find the link at position 18 (the first name is 1). Follow that link. Repeat this process 7 times. The answer is the last name that you retrieve.
Hint: The first character of the name of the last page that you will load is: N
#!/usr/bin/env python3
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
import ssl
Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter URL - ')
count = int(input('Enter Count: '))
position = int(input('Enter Position: '))
for name in range(count):
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
tags = soup('a')
count = 0
link = list()
for tag in tags:
urll = tag.get('href', None)
link.append(urll)
count = count +1
if count > position:
break
print(urll)
i also want to share my code as i was finally able to write correct code. it took me while to understand the question so i felt great after seeing positive result an getting this assignmnt done.
import re
import ssl
import urllib.request
from bs4 import BeautifulSoup
lst1 = list()
name_lst = list()
url_lst = list()
url1 = input('enter first url:')
url_lst.append(url1)
repeat = input('enter no of repeats:')
position = int(input('enter url position:')) - 1
count = 0
while count < int(repeat):
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
html = urllib.request.urlopen(url_lst[int(count)], context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
tags = soup('a')
for tag in tags:
x = tag.get('href', None)
lst1.append(x)
url_lst.append(lst1[int(position)])
lst1.clear()
count += 1
for url in url_lst:
y = re.findall('_([a-zA-Z]+).html', url)
name_lst.append(y[0])
print(name_lst)
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
import ssl
lst=[]
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter URL - ')
pos= int(input(' Enter position: '))
for i in range(7):
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
tags = soup('a')
for stuff in tags:
x=stuff.get('href', None)
lst.append(x)
url=lst[pos]
print(url)
lst.clear()
Start at: http://py4e-data.dr-chuck.net/known_by_Kedrick.html
Find the link at position 18 (the first name is 1). Follow that link. Repeat this process 7 times. The answer is the last name that you retrieve.
Hint: The first character of the name of the last page that you will load is: L
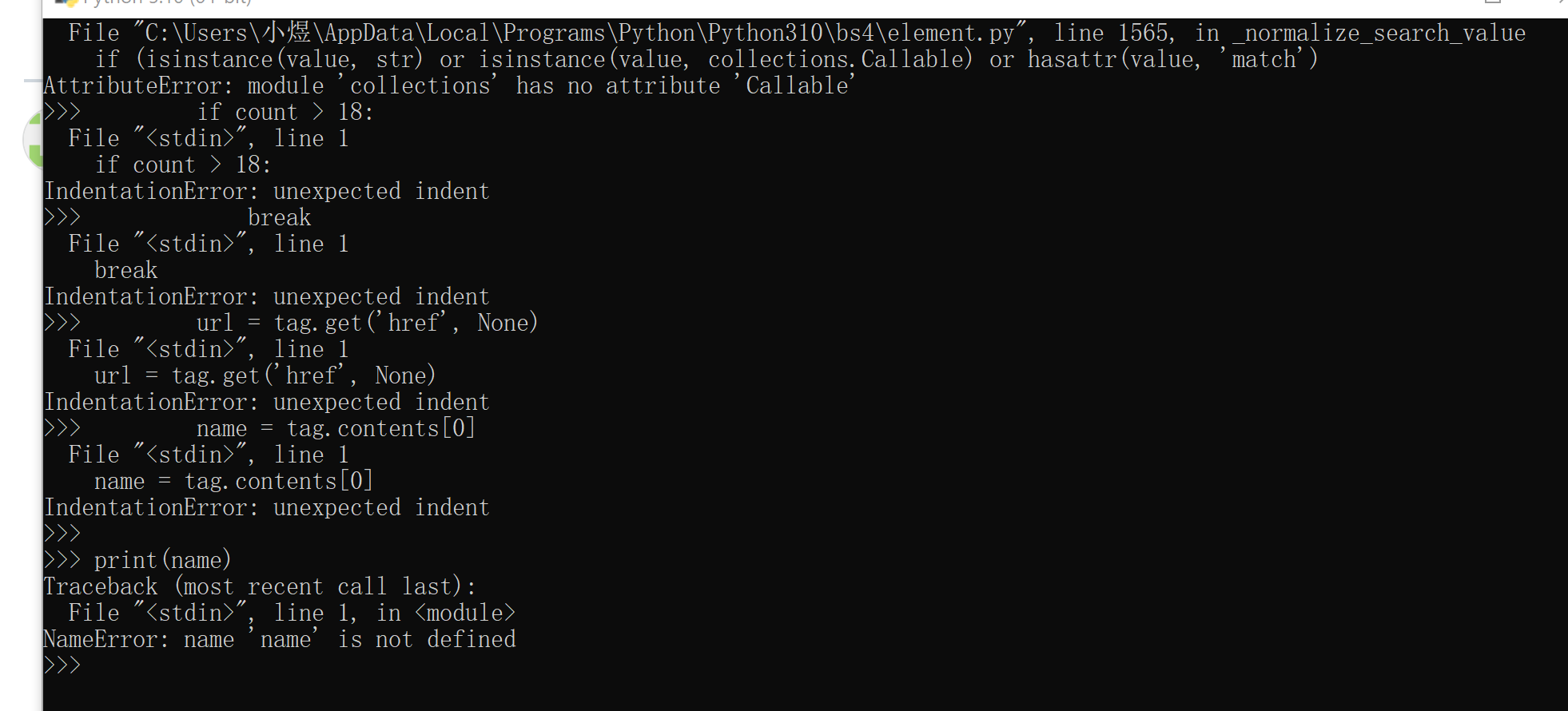
please help me, I don't know what the problem is!!!! here is my code:
import urllib.request, urllib.parse, urllib.error
import ssl
from bs4 import BeautifulSoup
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = "http://py4e-data.dr-chuck.net/known_by_Kedrick.html"
for i in range(7):
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
tags = soup('a')
count = 0
for tag in tags:
count = count +1
if count > 18:
break
url = tag.get('href', None)
name = tag.contents[0]
print(name)
The instructions for this assignment were poorly written and vague. Thank you for the help in clarifying the assignment a bit.
In case of some people if the above code does not work, try the following
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
url = input('Enter URL - ')
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
Find all the tags with class="comments"
span_tags = soup.find_all('span', class_='comments')
count = 0
total_sum = 0
for span in span_tags:
# Extract the text content of the span tag and convert to an integer
count += 1
total_sum += int(span.contents[0])
print("Count", count)
print("Sum", total_sum)
Here's how the code works:
It takes the URL as input from the user.
It retrieves the HTML content from the specified URL using urllib.request.urlopen.
It uses BeautifulSoup to parse the HTML and find all the tags with the class "comments" using soup.find_all.
It initializes two variables count and total_sum to keep track of the number of comments and the sum of the comments, respectively.
It iterates through each tag, converts the text content of the tag to an integer using int(span.contents[0]), and adds it to the total_sum.
Finally, it prints the total count and sum of the comments.
When you run the script, it will prompt you to enter the URL (e.g., http://py4e-data.dr-chuck.net/comments_42.html) and then display the count and sum of the comments in the given URL.
That's very helpfull. tysm 👍