Last active
August 6, 2021 11:07
-
-
Save NatureGeorge/62cdb644154fb11f3fa73f02dbcf2b9b to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # Copyright (C) 2002, Thomas Hamelryck (thamelry@binf.ku.dk) | |
| # | |
| # This file is part of the Biopython distribution and governed by your | |
| # choice of the "Biopython License Agreement" or the "BSD 3-Clause License". | |
| # Please see the LICENSE file that should have been included as part of this | |
| # package. | |
| """Turn an mmCIF file into a dictionary.""" | |
| from Bio.File import as_handle | |
| class MMCIF2Dict(dict): | |
| """Parse a mmCIF file and return a dictionary.""" | |
| def __init__(self, filename): | |
| """Parse a mmCIF file and return a dictionary. | |
| Arguments: | |
| - file - name of the PDB file OR an open filehandle | |
| """ | |
| self.quote_chars = ["'", '"'] | |
| self.whitespace_chars = [" ", "\t"] | |
| with as_handle(filename) as handle: | |
| loop_flag = False | |
| key = None | |
| tokens = self._tokenize(handle) | |
| try: | |
| token = next(tokens) | |
| except StopIteration: | |
| return # for Python 3.7 and PEP 479 | |
| self[token[0:5]] = token[5:] | |
| i = 0 | |
| n = 0 | |
| for token in tokens: | |
| if token.lower() == "loop_": | |
| loop_flag = True | |
| keys = [] | |
| i = 0 | |
| n = 0 | |
| continue | |
| elif loop_flag: | |
| # The second condition checks we are in the first column | |
| # Some mmCIF files (e.g. 4q9r) have values in later columns | |
| # starting with an underscore and we don't want to read | |
| # these as keys | |
| if token.startswith("_") and (n == 0 or i % n == 0): | |
| if i > 0: | |
| loop_flag = False | |
| else: | |
| self[token] = [] | |
| keys.append(token) | |
| n += 1 | |
| continue | |
| else: | |
| self[keys[i % n]].append(token) | |
| i += 1 | |
| continue | |
| if key is None: | |
| key = token | |
| else: | |
| self[key] = [token] | |
| key = None | |
| # Private methods | |
| def _splitline(self, line): | |
| # See https://www.iucr.org/resources/cif/spec/version1.1/cifsyntax for the syntax | |
| in_token = False | |
| # quote character of the currently open quote, or None if no quote open | |
| quote_open_char = None | |
| start_i = 0 | |
| for (i, c) in enumerate(line): | |
| if c in self.whitespace_chars: | |
| if in_token and not quote_open_char: | |
| in_token = False | |
| yield line[start_i:i] | |
| elif c in self.quote_chars: | |
| if not quote_open_char and not in_token: | |
| quote_open_char = c | |
| in_token = True | |
| start_i = i + 1 | |
| elif c == quote_open_char and ( | |
| i + 1 == len(line) or line[i + 1] in self.whitespace_chars | |
| ): | |
| quote_open_char = None | |
| in_token = False | |
| yield line[start_i:i] | |
| elif c == "#" and not in_token: | |
| # Skip comments. "#" is a valid non-comment char inside of a | |
| # quote and inside of an unquoted token (!?!?), so we need to | |
| # check that the current char is not in a token. | |
| return | |
| elif not in_token: | |
| in_token = True | |
| start_i = i | |
| if in_token: | |
| yield line[start_i:] | |
| if quote_open_char: | |
| raise ValueError("Line ended with quote open: " + line) | |
| def _tokenize(self, handle): | |
| empty = True | |
| for line in handle: | |
| empty = False | |
| if line.startswith("#"): | |
| continue | |
| elif line.startswith(";"): | |
| # The spec says that leading whitespace on each line must be | |
| # preserved while trailing whitespace may be stripped. The | |
| # trailing newline must be stripped. | |
| token_buffer = [line[1:].rstrip()] | |
| for line in handle: | |
| line = line.rstrip() | |
| if line.startswith(";"): | |
| yield "\n".join(token_buffer) | |
| line = line[1:] | |
| if line and not line[0] in self.whitespace_chars: | |
| raise ValueError("Missing whitespace") | |
| break | |
| token_buffer.append(line) | |
| else: | |
| raise ValueError("Missing closing semicolon") | |
| yield from self._splitline(line.strip()) | |
| if empty: | |
| raise ValueError("Empty file.") |
Author
NatureGeorge
commented
Sep 4, 2020
- https://github.com/pdbxmmcifwg/carbohydrate-extension
- https://github.com/pdbxmmcifwg/carbohydrate-extension/blob/master/Carbohydrates.md
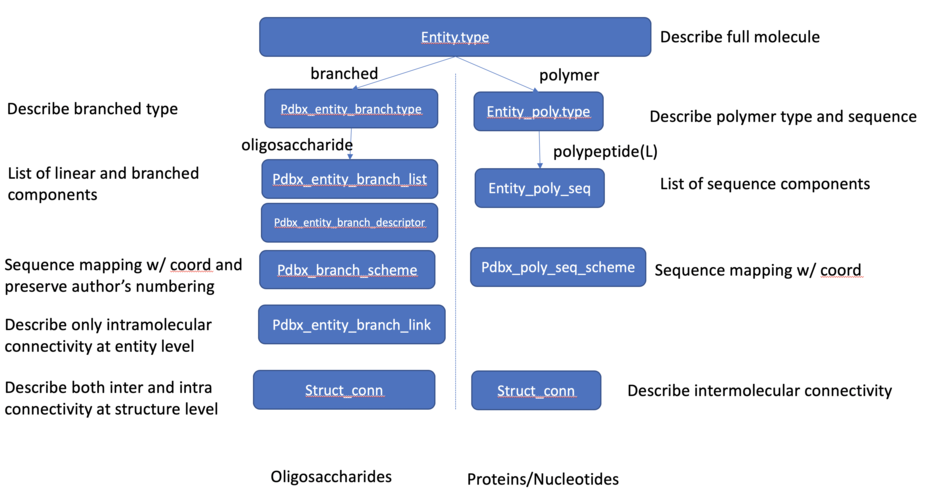
TODO (2020-09-11)
Plan to implement lark-parser to rewrite MMCIF2DictPlus.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment