Liyi Ho
*本篇文章是閱讀GitHub's open source load balancer 並整理後的文章,附加一些粗淺心得。 之後預計閱讀gitbug內development文件後並追加內容
傳統上他們採取垂直式的擴張(增強硬體能力),Github使用一部分的haproxy並使用特殊的硬體配置去達到承受10G的連結故障轉移(link failover)。最終他們需要可擴展的解決方案,製作出一個新的load balancer方案可以運行在commodity hardware(一般規格的硬體)
- 可在一般規格硬體上運行
- 可水平擴展(scales horizontally)
- 高可效性,在故障轉移等過程中也能避免斷線
- 支援連結耗盡(connection draining)功能
- 每個服務負載均衡,每個load balancer支援多個服務
- 可像一般軟體,被迭代或發展
- 可分成每一層去test
- 為各種資料中心和機房中心(POPs)打造
- 能在傳統DDoS攻擊下迅速回復,並可發展對抗新型攻擊
Equal-cost multi-path routing(中譯:等價多路徑路由)最初被拿來被當作前往單一目的的最佳路徑選擇。但在延伸運用上,可以拿來作為負載平衡機制的一環,藉由ECMP 將各packets hasing至各路徑。
運用BGP或其他相似網路協議,使多個server能分享同一IP Address,讓連結能被多個伺服器之間分享,且router並未察覺。
然而只用ECMP來做為負載平衡有一個缺點,就是當後端server數量變動時,則該server上的連線會全部中斷,連線狀態也不會保留。
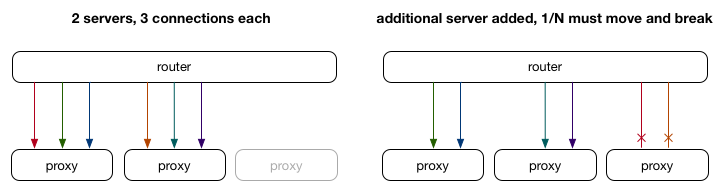
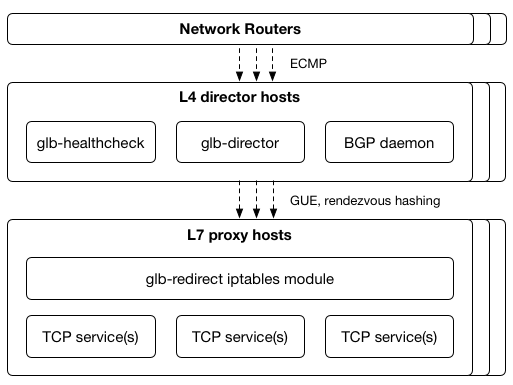
L4L7分層Load Balancer能夠改善上述單純使用ECMP作為負載平衡的缺陷。 首先在L4做一層director server(通常在上面運行LVS:Linux Virtual Server),而在L7層建置協助分流至真正Backend server的proxy
LVS director接收藉由ECMP分流的packets,此層會記錄各in-progress connections的state、嘗試修正前面ECMP hashing結果。director層數量並未變動,當proxy server更動時,此設計協助現有connections能繼續,因為Dircetor層保存了現有connections到現有proxy層的對應。
這個架構仍有缺陷,當LVS director層與proxy層的數量變動時,新的director server尚未更新到最新的connection state,會將舊的connection當作新的connection,使該connection失敗。
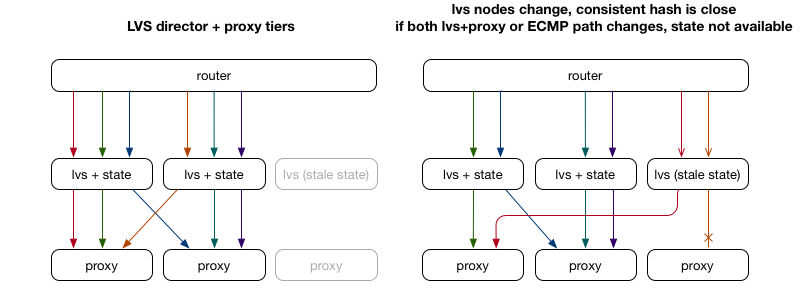
一個workaround的解決方案是使用multicast connection syncing,將connection state在LVS director層之間互相分享。
對Github而言,這個設計有三個問題: 1.他們不想在LVS之間使用Mulicast 2.在(1)之下,他們也不想接受連結失敗 3.在Director層保存connection state增加了對抗DDoS的難度。 延伸: Github使用synsanity來解決SYN Food away這種DDoS。
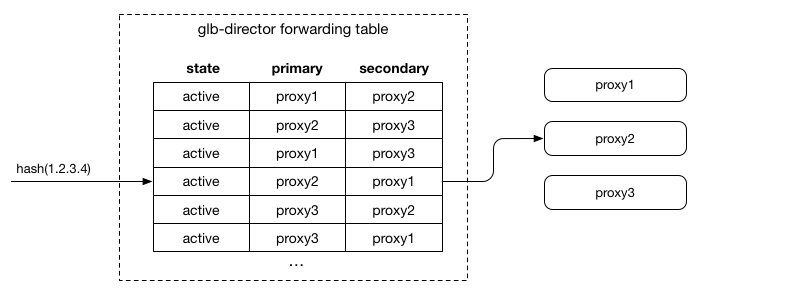
L4層設計新的director層:glb director來取代之前的LVS director。對每個連線,glb director藉由一次hashing挑選出一組代理伺服器:primary server和secondary server,packet會先前往第一組proxy server,若該proxy server非有效,則轉送至secondary server。藉由後端proxy server來協助校正,glb director本身並不儲存任何connection state,只須要維護選擇primary/secondary server的table。
為了讓glb director能依照table去選擇proxy,且能讓proxy能順利達成排放(drain)和填充(fill),github設計讓proxy各自有一state,glb director則依照這個state去做proxy server的增刪。
上述提到glb director藉由一次hashing來得出要挑選哪一組primary/secondary proxy server, 可以了解到對於如何對應下一層proxy server增刪來維護hash table會是此director主要的設計目標,table的樣式如上圖。
為了達到能讓各proxy server於primary和secondary的出現頻率彼此近似,且不會有一entry 的primary和secondary是同一個server,當加入一新server時,會把部分row的primay變成secondary,並把新server加入到空出來的primary中;針對seconday的均衡,會把部分secondary換成new server。 當移除一server的時候,則將被移除的primary用該enry的secondary代替,並補上secondary來維持均衡。
giuhub列出了他們維持hash table的主要目標:
- As we change the set of servers, the relative order of existing servers should be maintained.
- The order of servers should be computable without any state other than the list of servers (and maybe some predefined seeds).
- 每一列,每一個server只能出現一次
- 每一個server的出現數量必須在每一行保持一致
Rendezvous hashing被github視為能達成上述條件的理想選擇。
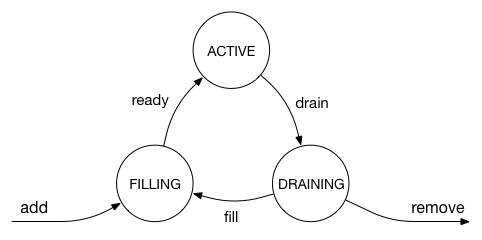
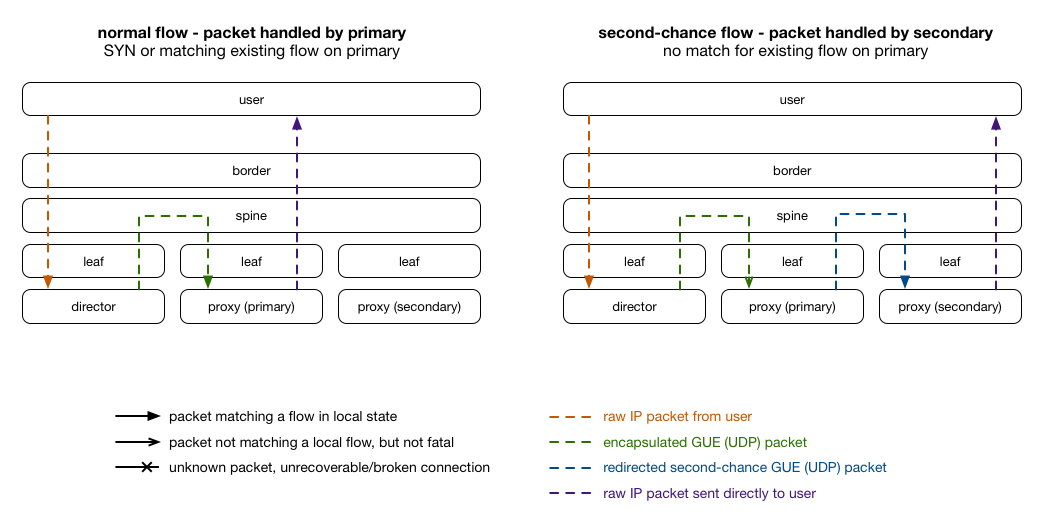
github對proxy定義了三個state: active, draining 和 filling。這都被包含在glb director forwarding table的entry中。穩定的情況下,所有proxy server都會是active,此時上述的Rendezvous hashing能將table維持在最佳的平衡:primary和secondary下的各server彼此數量一致。
當server狀態轉移到draining的時候,glb table會做對應的調整:primary為該server的entry會對調primary和secondary。
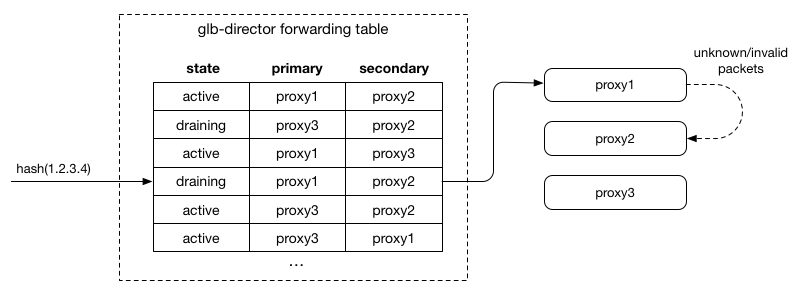
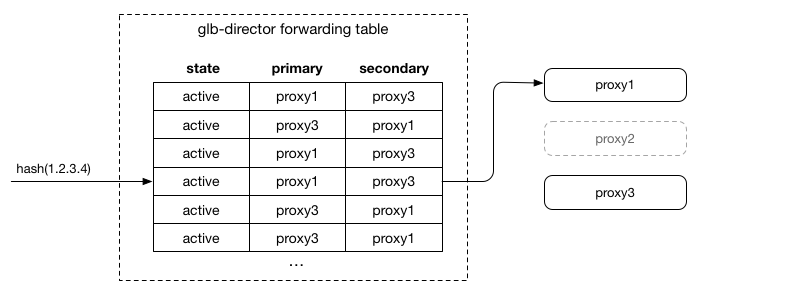
如上圖,此時proxy2會開始負責接受new connection(SYN packet),此外不了解的packet就會redirect至 proxy1(先前的primary),讓原有的connection能完成本身任務。這讓server能順利的完成原有connection且能安然移除。移除之後,重新調整secondary server:
server狀態為filling時,狀態類似active,利用本身可以再次選擇的特性維持old connections
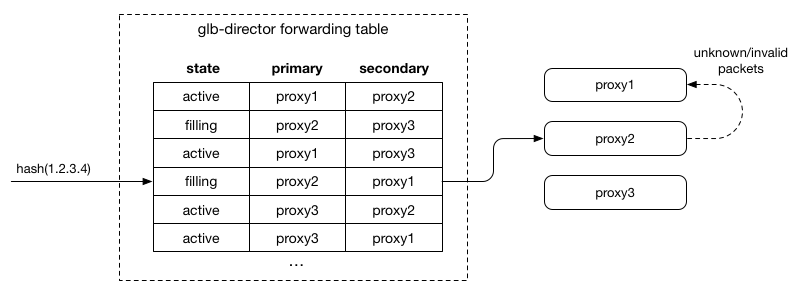
維護glb-director forwarding table,需保證同一時間只會有一個server的狀態並不是active,而這實際上在github中運作良好,state change所需時間就跟最長持續的connection一樣。
設計如何將secondary server資訊塞入封包中是個議題。 傳統LVS設定中,有IP over IP(IPIP)隧道的使用。Githib認為有兩點導致認為不符使用:
- 將額外server的metadata 編碼至IPIP packet有點難,可用的標準空間只有IP Options。
- Github的datacenter router 需將有未知IP options的 packets送至軟體處理,速度可能降至千分之一(from millions to thousands)
Github決定將資料藏在router難以知曉的地方,採用Generic UDP Encapsulation (GUE),在FOU(Foo-over-UDP)上層,而FOU是一個將IP包資訊與內容封裝在UDP包的技術。
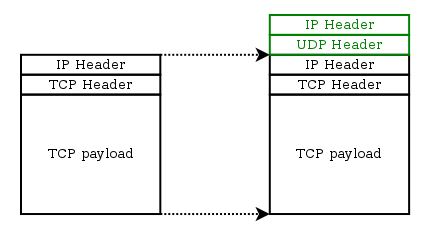
Github將secondary proxy server的IP資訊放在GUE header的private data中,此時router只會將此視為普通的UDP包在兩個一般server間傳送。 https://gist.github.com/0b7fff6fc2a5e5660bdcaf1d3b776fbd
當proxy server要回送packet給client時,他會直接送到client端,不會再進行封裝或是經過glb director層轉發。
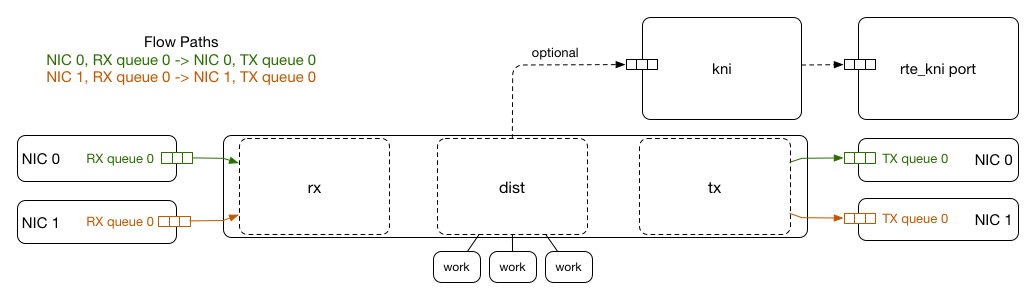
github在設計glb-director時使用DPDK,嘗試繞過linux kernal快速處理封包,這使得遇到大量請求甚至DDoS攻擊時,director不會成為系統效能的瓶頸。
利用SR-IOV(Single-root input/output virtualization),於NIC上實現flow bifurcation,將RX traffic分流,使其能依需求分別導向DPDK process和Linux kernel。
GLB director 使用DPDK Packet Distributor,來平行處理收到的封包並進行封裝,幾乎各項事stateless的關係,能高度平行處理。
GLB director會運行glb-healthcheck,不停驗證後面server的GUE隧道和HTTP port 當發現server fails時,挑出fail server是primay proxy server的entry,再將其primay和secondary調換,這提供connection能有良好的機會能故障轉移。 如果healthcheck誤認的話,原有的connection也不會中斷,因為他們會被轉到secondary proxy--他們原來的server。
Proxy server的second chance 設計是藉由Netfilter模組和iptables來實現。他們會抓出在GUR封裝封包裡面的TCP/IP封包是否有效,無效的話就不拆裝並會往後丟到secondary proxy server。
綜觀整篇文章,在L7 proxy server的工作和當proxy fail over時的處理狀況仍稍有些不明,需再找時間研究Orz。