vi /etc/init.d/networking
on start handler.
start)
echo -n "Configuring network interfaces... "
sysctl -e -p /etc/sysctl.conf >/dev/null 2>&1| #!/bin/bash | |
| sudo mv /var/lib/dpkg/info /var/lib/dpkg/info.bk | |
| sudo mkdir /var/lib/dpkg/info | |
| sudo apt-get update | |
| sudo apt-get install -f |
在read/write/ioctl等系统调用里,经常需要从用户空间读取数据,或者向用户空间的地址写入数据。如果应用程序传入了一个参数user_arg,指向的是用户空间的地址。那么我们在内核态里能否直接从这个地址读取数据呢?答案是肯定的,因为内核能够看到进程的整个地址空间,属于这个进程的所有page在此进程的page table里,内核函数当然可以访问那个指针user_arg。那么既然内核态可以访问任意的虚拟地址空间,为什么一定要用copy_from_user/copy_to_user,而不是直接用memcpy或者直接dereference那个地址?
我们可以提出以下问题:
内核很多地方都要跟踪记录C语言中结构体的实例。尽管这些对象用法不太一样,但各个子系统的操作都非常类似,例如引用计数。这导致了代码的复制。由于这个是个糟糕的问题,因此内核采用了一种通用的方法来管理这个行为和内核对象。引入这个框架的目的是为了防止代码复制,同时也为内核不同部分管理的对象提供了一些视图,在内核的许多部分可以有效的使用相关信息,例如电源,例如驱动。一般性内核对象机制可以用于执行下列对象操作:
本文整理范本[^1][^2]
通常的进程发起申请内存的动作之后,会在系统的空闲内存区寻找合适大小的内存块(底层分配函数__alloc_node_mask),如果满足就直接分配,如果不满足就会向上查找。如果过大就会进行分裂,一部分分给申请进程,一部分放入空闲区。释放时需要找到这个块对应的伙伴,如果伙伴也为空闲,就进行合并,放入高阶空闲链表,如果不空闲就放入对应链表。同时对于多线程申请和释放内存,需要加锁。这样的默认的分配方式考虑到了系统中的大部分情况,具有通用性,但是无可避免的会产生内部碎片,而且加锁,解锁的开销也很大。程序可以通过系统的内存分配方法预先分配一大块内存来做一个内存池,之后程序的内存分配和释放都由这个内存池来进行操作和管理,当内存池不足时再向系统申请内存。
我们通常使用malloc等函数来为用户进程分配内存。它的执行过程通常是由用户程序发起malloc申请内存的动作,在标准库找到对应函数,对不满128k的调用brk()系统调用来申请内存(申请的内存是堆区内存),接着由操作系统来执行brk系统调用。
我们知道malloc是在标准库,真正的申请动作需要操作系统完成。所以由应用程序到操作系统就需要3层。内存池是专为应用程序提供的专属的内存管理器,它属于应用程序层。所以程序申请内存的时候就不需要通过标准库和操作系统,明显降低了开销。
援引Linux应用调试(一)方法、技巧和工具 - 综述.md :软件工具->Linux User-> 动态 -> valgrind。
C/C++相比其他高级编程语言,具有指针的概念,指针即是内存地址。C/C++可以通过指针来直接访问内存空间,效率上的提升是不言而喻的,是其他高级编程语言不可比拟的;比如访问内存一段数据,通过指针可以直接从内存空间读取数据,避免了中间过程函数压栈、数据拷贝甚至消息传输等待。指针是C/C++的优势,但也是一个隐患,指针是一把双刃剑,由于内存交给了程序员管理,这是存在隐患的;人总会有疏忽的时候,如果申请了内存,一个疏忽忘记释放了,未释放的内存将不能被系统再申请使用,即是一直占用又不能使用,俗称内存泄露;久而久之,系统长时间运行后将申请不到内存,系统上所有任务执行失败,只能重启系统。内存交给了程序员管理,除了内存泄露的情况外,还可能引起其他的问题,总结起来包括如下几点:
援引Linux应用调试(一)方法、技巧和工具 - 综述.md :软件工具->Linux User-> 动态 -> Coredump。
Valgrind的作用性体现更多在于“内存泄露”检查,因为空指针、野指针的访问,会引发程序段错误(segment fault )而终止,此时可以借助linux系统的coredump文件结合gdb工具可以快速定位到问题发生位置。此外,程序崩溃引发系统记录coredump文件的原因是众多的,野指针、空指针访问只是其中一种,如堆栈溢出、内存越界等等都会引起coredump,利用好coredump文件,可以帮助我们解决实际项目中的异常问题[^3]。
coredump对于分析程序异常的作用是不言而喻的。以前我们学习ARM 32位MCU为例(STM32),由于初学过程,代码质量参差不齐,经常引起硬件错误中断(Hard Fault)。面对这种情况,我们是束手无策的,一方面是程序发生错误后没有记录到有参考意义的信息(当然,可以通过仿真器实时获取堆栈信息,但对于实际产品不现实);另一方面是问题复现概率比较低,复现条件不确定。linux系统是一个“考虑周全”的操作系统,应用程序发生异常,会记录一些关键的信息,已便于我们分析。coredump的意义就在于此[^3]。
分析core dump是Linux应用程序调试的一种有效方式,core dump又称为“核心转储”,是该进程实际使用的物理内存的“快照”。分析core dump文件可以获取应用程序崩溃时的现场信息,如程序运行时的CPU寄存器值、堆栈指针、栈数据、函数调用、等内存信息、寄存器状态、堆栈地址、函数调用上下文,开发人员通过分析这些信息,确定程序异常发生时的调用位置,如果是堆栈溢出,还需分析多层函数的调用信息。
如果把调试系统化,截止到目前可以总结为:

搞电子都知道,电路不是焊接出来的,是调试出来的。程序员也一定认同,程序不是写出来的,是调试出来的。那么调试工具就显得尤为重要,linux作为笔者重要的开发平台,在linux中讨论调试工具主要是为那些入门者提供一些帮助。调试工具能让我们能够监测、控制和纠正正在运行的程序。我们在运行一些程序的时候,可能被卡住或出现错误,或者运行过程或结果,没能如我们预期,此时,最迫切需要明白究竟发生了什么。为了修复程序,剖析和了解程序运行的细节, 调试工具就成为了我们的必备工具,工于善其事,必先利其器。在Linux下的用户空间调试工具主要有系统工具和专门调试工具:print 打印语句,这是新手最常用的,也是最不提倡使用的;查询 (/proc, /sys 等)系统的虚拟文件查看,这个方法有局限性;跟踪 (strace/ltrace)工具使用这个比较普遍,值得提倡;Valgrind (memwatch)内存排除工具,在内存排除方面比较独到,是内存排错的法宝;GDB大名鼎鼎的程序调试工具,这个是个全能的工具,没有完不成的,只有你不知道的。
然动态内存存在隐患,但有时候又不得不使用,内存泄露也就成为一个必须杜绝的敏感问题;有需求就会有相应的解决方法,目前已存在许多优秀的内存泄露检测工具,除了我们常用的Valgrind外,还有mtrace、dmalloc、memwatch等优秀工具。
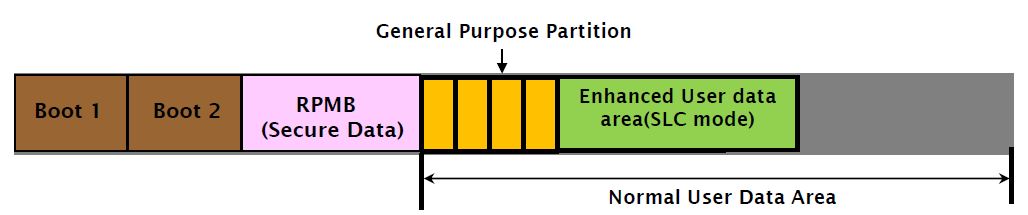
家所最为熟知的分区方式同时也是最主流的主要有两种:MBR(Master Boot Record)和GPT(GUID Partition Table)。前者应用于绝大多数使用BIOS引导的PC设备(苹果使用EFI的方式),而后者主要是针对MBR的一些缺点进行了改进同时还可以兼容MBR并且支持2TB以上的存储(MBR不支持2TB以上的存储设备)。Android 2.x.x 版本上使用的是MBR,4.0版本以后就是使用的GPT分区方式。EMMC的分区有一些是AP不能修改的(如BOOT1、BOOT2和RPMB分区),有一些是可以通过特定的命令和寄存器就可以修改的(如Enhanced Partition和GPAP)。
eMMC 标准中,可将内部的 Flash Memory 划分为 4 类区域,最多可以支持 8 个硬件分区,如下所示: