援引Linux应用调试(一)方法、技巧和工具 - 综述.md :软件工具->Linux User-> 动态 -> Coredump。
Valgrind的作用性体现更多在于“内存泄露”检查,因为空指针、野指针的访问,会引发程序段错误(segment fault )而终止,此时可以借助linux系统的coredump文件结合gdb工具可以快速定位到问题发生位置。此外,程序崩溃引发系统记录coredump文件的原因是众多的,野指针、空指针访问只是其中一种,如堆栈溢出、内存越界等等都会引起coredump,利用好coredump文件,可以帮助我们解决实际项目中的异常问题1。
coredump对于分析程序异常的作用是不言而喻的。以前我们学习ARM 32位MCU为例(STM32),由于初学过程,代码质量参差不齐,经常引起硬件错误中断(Hard Fault)。面对这种情况,我们是束手无策的,一方面是程序发生错误后没有记录到有参考意义的信息(当然,可以通过仿真器实时获取堆栈信息,但对于实际产品不现实);另一方面是问题复现概率比较低,复现条件不确定。linux系统是一个“考虑周全”的操作系统,应用程序发生异常,会记录一些关键的信息,已便于我们分析。coredump的意义就在于此1。
分析core dump是Linux应用程序调试的一种有效方式,core dump又称为“核心转储”,是该进程实际使用的物理内存的“快照”。分析core dump文件可以获取应用程序崩溃时的现场信息,如程序运行时的CPU寄存器值、堆栈指针、栈数据、函数调用、等内存信息、寄存器状态、堆栈地址、函数调用上下文,开发人员通过分析这些信息,确定程序异常发生时的调用位置,如果是堆栈溢出,还需分析多层函数的调用信息。
Core dump是Linux基于信号实现的。Linux中信号是一种异步事件处理机制,每种信号都对应有默认的异常处理操作,默认操作包括忽略该信号(Ignore)、暂停进程(Stop)、终止进程(Terminate)、终止并产生core dump(Core)等。
| ignal | Value | Action | Comment |
|---|---|---|---|
| SIGHUP | 1 | Term | Hangup detected on controlling terminal or death of controlling process |
| SIGINT | 2 | Term | Interrupt from keyboard |
| SIGQUIT | 3 | Core | Quit from keyboard |
| SIGILL | 4 | Core | Illegal Instruction |
| SIGTRAP | 5 | Core | Trace/breakpoint trap |
| SIGABRT | 6 | Core | Abort signal from abort(3) |
| SIGIOT | 6 | Core | IOT trap. A synonym for SIGABRT |
| SIGEMT | 7 | Term | |
| SIGFPE | 8 | Core | Floating point exception |
| SIGKILL | 9 | Term | Kill signal, cannot be caught, blocked or ignored. |
| SIGBUS | 10,7,10 | Core | Bus error (bad memory access) |
| SIGSEGV | 11 | Core | Invalid memory reference |
| SIGPIPE | 13 | Term | Broken pipe: write to pipe with no readers |
| SIGALRM | 14 | Term | Timer signal from alarm(2) |
| SIGTERM | 15 | Term | Termination signal |
| SIGUSR1 | 30,10,16 | Term | User-defined signal 1 |
| SIGUSR2 | 31,12,17 | Term | User-defined signal 2 |
| SIGCHLD | 20,17,18 | Ign | Child stopped or terminated |
| SIGCONT | 19,18,25 | Cont | Continue if stopped |
| SIGSTOP | 17,19,23 | Stop | Stop process, cannot be caught, blocked or ignored. |
| SIGTSTP | 18,20,24 | Stop | Stop typed at terminal |
| SIGTTIN | 21,21,26 | Stop | Terminal input for background process |
| SIGTTOU | 22,22,27 | Stop | Terminal output for background process |
| SIGIO | 23,29,22 | Term | I/O now possible (4.2BSD) |
| SIGPOLL | Term | Pollable event (Sys V). Synonym for SIGIO | |
| SIGPROF | 27,27,29 | Term | Profiling timer expired |
| SIGSYS | 12,31,12 | Core | Bad argument to routine (SVr4) |
| SIGURG | 16,23,21 | Ign | Urgent condition on socket (4.2BSD) |
| SIGVTALRM | 26,26,28 | Term | Virtual alarm clock (4.2BSD) |
| SIGXCPU | 24,24,30 | Core | CPU time limit exceeded (4.2BSD) |
| SIGXFSZ | 25,25,31 | Core | File size limit exceeded (4.2BSD) |
| SIGSTKFLT | 16 | Term | Stack fault on coprocessor (unused) |
| SIGCLD | 18 | Ign | A synonym for SIGCHLD |
| SIGPWR | 29,30,19 | Term | Power failure (System V) |
| SIGINFO | 29 | A synonym for SIGPWR, on an alpha | |
| SIGLOST | 29 | Term | File lock lost (unused), on a sparc |
| SIGWINCH | 28,28,20 | Ign | Window resize signal (4.3BSD, Sun) |
| SIGUNUSED | 31 | Core | Synonymous with SIGSYS |
应用程序发生异常时,会产生coredump文件记录,这些异常几乎都与内存相关,总结起来包括几点。以下情况会出现应用程序崩溃导致产生core dump:
- 内存访问越界
- 数组下标越界
- 超出动态(malloc/new)内存申请范围
- 字符串没有结束符,一些函数依赖于字符串结束符,如 strcpy、strcmp、sprintf
- 访问非法指针
- 空指针(未申请内存)
- 野指针(已释放内存)
- 重复释放指针(内存)
- 指针强制转换,指针强制转换需特别谨慎,
- 可能因为对齐、起始地址等问题引起内存访问错误
- 堆栈溢出
- 分配大量局部变量
- 多重函数调用
- 较深的函数递归等可能导致堆栈溢出
- 多线程访问
- 调用不可重入函数
- 共享数据未互斥访问
系统默认不开启coredump记录功能,执行"ulimit -c"查看是否开启,返回0表示未开启coredump记录功能。Linux提供了一组命令来配置core dump行为:
ulimit –c 查看core dump机制是否使能,若为0则默认不产生core dump,可以使用ulimit –c unlimited使能core dump

可以使用“ulimit -c [size]”命令指定记录coredump文件的大小,即是开启coredump记录。需要注意的是,单位为block,1block=512bytes。
ulimit -c 1024
万一程序比较糟糕,指定的coredump文件大小限制,导致文件记录不到或者缺失怎么办。此时,一劳永逸的办法就是不限制coredump文件大小;执行“ulimit -c unlimited”设定,设置时需要root权限。
以上方式都是在终端临时设置开启coredump记录功能,系统重启后失效,很显然这不是理想的方法。理想的方法是修改配置文件,使得系统一直开启coredump记录功能,至少在项目开发测试阶段是需要开启的。原则上,软件发布后也应该记录,出现问题后能够有追溯和分析问题的依据。
在"/etc/profile"文件增加" ulimit -c unlimited "。
注:ulimit 命令是一个设置资源限制的命令,除了coredump外,还可以设定其他资源限制
-a:查看当前资源限制信息 -c <core最大值>:设定core文件的最大值,单位为块(block) -d <数据节段大小>:进程数据段最大值,单位为KB -f <文件大小>:进程可创建最大文件值,单位为块(block) -H:设置资源的硬性限制,设置后不可更改 -l <内存大小>: 可加锁内存大小,单位 为KB -m <内存大小>:指定可使用内存的上限,单位为KB -n <文件数目>:进程最大可打开的文件数(文件描述符数目) -p <缓冲区大小>:管道缓冲区的大小,单位为KB -s <堆栈大小>:线程最大堆栈大小,单位为KB -S:设置资源的弹性限制,不可超过硬性资源限制 -t <cpu时间>:cpu最大占用时间,单位为秒 -u <进程数目>:用户可创建的最大进程数 -v <虚拟内存大小>:进程最大可用虚拟内存,单位为KB
除此之外,还有可以通过在代码中设定开启coredump。然而一般不推荐该方式, 因为如果代码中没有增加开启功能,而应用程序又发生了异常,系统将无法记录coredump。建议在系统配置文件设置开启。
#include <sys/resource.h>
int getrlimit(int resource, struct rlimit *rlim);/* 获取coredump 文件限制大小 */
int setrlimit(int resource, const struct rlimit *rlim);/* 设置coredump 文件限制大小 */- 功能,获取(设置)系统资源限制,coredump只是系统资源的一种,如虚拟内存大小、进程堆栈、最大进程数等等
resource,系统资源标识,对于coredump,为RLIMIT_CORErlim,资源限制数据结构,即是限制值struct rlimit { rlim_t rlim_cur; rlim_t rlim_max; };
- 返回:成功返回0,失败返回-1,错误码存于
error中。
例子:
#include <sys/resource.h>
int main(int argc, char * argv [ ])
{
struct rlimit rlmt;
rlmt.rlim_cur = (rlim_t)1024;
rlmt.rlim_max = (rlim_t)1024;
if (-1 == setrlimit(RLIMIT_CORE, &rlmt)) {
perror("setrlimit error");
return -1;
}
}coredump文件默认存储于应用程序执行目录下,文件名称为“core”。使用默认文件名称显然不是一个好的方式,如果有多个应用程序异常终止,将覆盖core文件;或者同一个应用程序,在异常终止后被守护进程重新启动运行,再次异常时导致core文件被覆盖。
文件名称带进程id(PID)
修改"/proc/sys/kernel/core_uses_pid"文件,可以将进程的id作为作为扩展名,文件内容为1表示使用扩展名,默认为0;使用进程id扩展名时,生成的core文件格式为"core.xxx",xxx为进程id。
更详细的名称以及存储位置
修改"/proc/sys/kernel/core_pattern"文件可以设置coredump文件的存储位置和更详细的文件名称。默认位置和名称信息如下:
echo "core_%e_%t_%p" > /proc/sys/kernel/core_pattern
会在和执行文件同一个目录下生成coredump。扩展字符含义:
%p - 扩展进程id(pid)
%P - 与%p作用相同
%u - 扩展用户id(uid)
%g - 扩展组id(gid)
%s - 扩展产生信号
%t - 扩展当前时间,从1970-01-0100:00:00开始的秒数
%h - 扩展主机名
%e - 扩展应用程序文件名称
%E - 扩展应用程序文件名称,包括文件绝对路径
coredump存储目录不变(存储于当前应用程序目录下),文件扩展名称增加应用程序文件名称、进程id、当前时间,这是实际场景常用的基本用法,能否适用绝对部分场合。可以用vi直接打开文件编辑,也可以使用echo修改文件内容,前提都是必须以root权限修改。
编写一个“非法”程序,让系统记录coredump,结合gdb来分析过程;编译时需加入"-g",保留调试信息。我们在ARMv7架构的linux上进行调试和运行coredump。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
int a, b, result;
a = 2;
b = 0;
result = a/b;
return 0;
}编译执行该程序,由于除0,程序异常退出,将产生一个coredump文件。
✗ arm-linux-gnueabihf-gcc -g test_coredump.c
没有-g也是可以的,但是没有symbol信息,需要自己去核对变量地址。
运行之后,发生coredump。

源文件a.out,core文件core_a.out_1649453886_718
- 通过
file查看coredump文件类型
- 可以在host端使用
readelf -h core_a.out_1649453886_718查看coredump信息。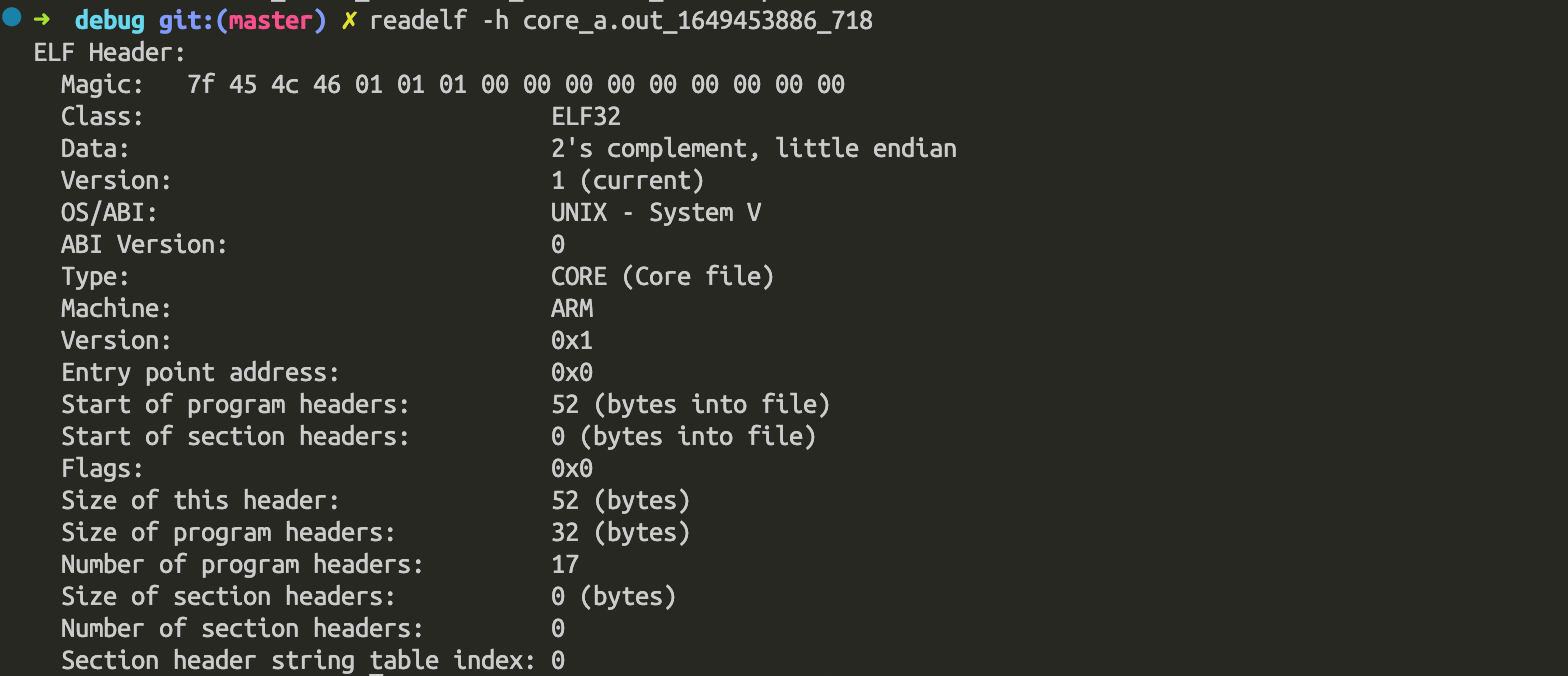 coredump文件本质上是一个ELF二进制文件。
coredump文件本质上是一个ELF二进制文件。 - 可以使用
arm-linux-gnueabihf-objdump查看反汇编信息arm-linux-gnueabihf-objdump -d core > coredump_assembly.txt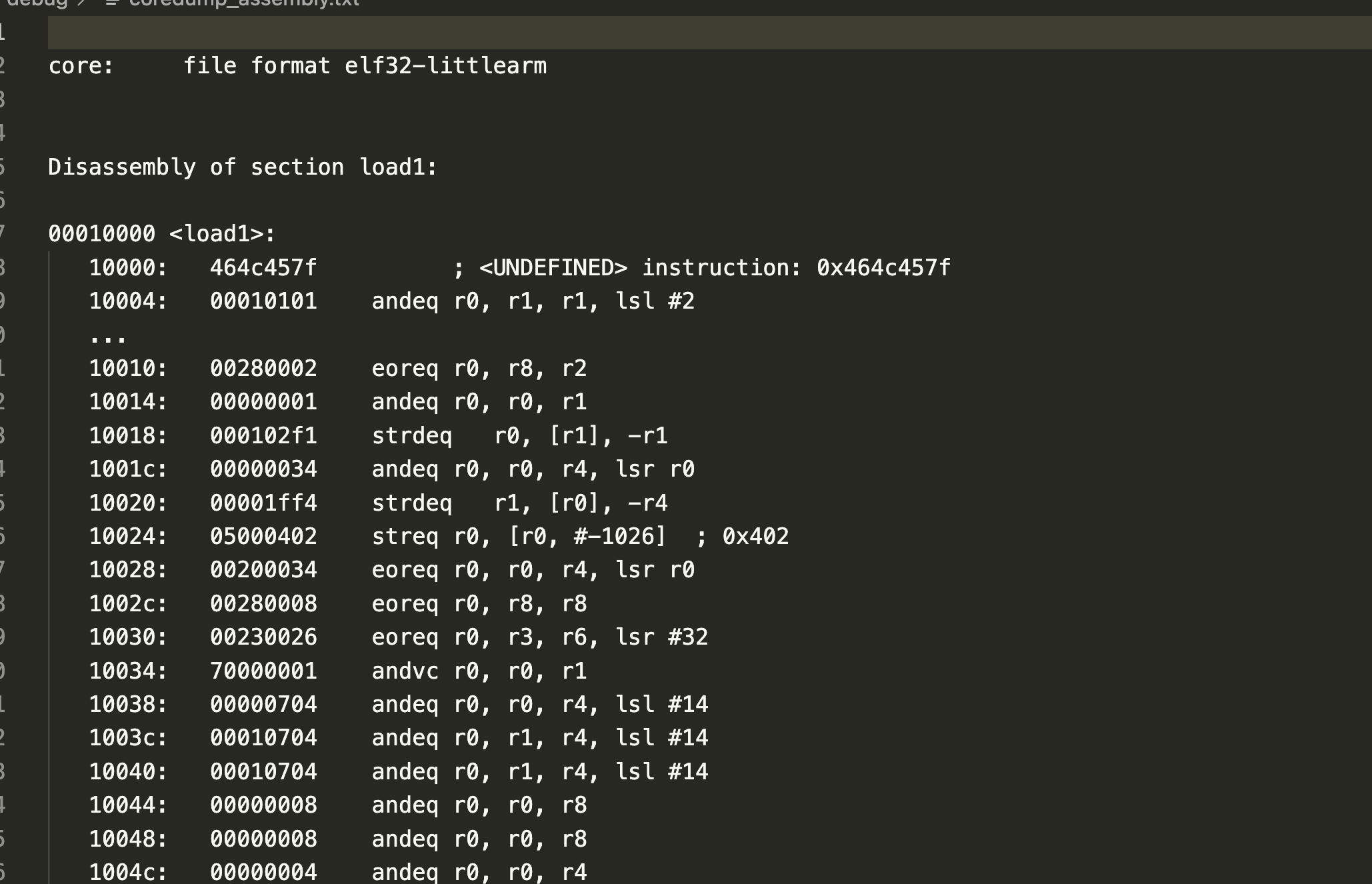
启动gdb 调试命令,可以在device端直接启动gdb调试$> gdb exe_file core_file,或者在host端也可以,需要借助arm-linux-gnueabihf-gdb工具来完成。
host的gdb工具需要下面的库依赖:
sudo apt install lib32ncurses5sudo apt install libpython2.7-dev
gdb调试$> gdb exe_file core_file
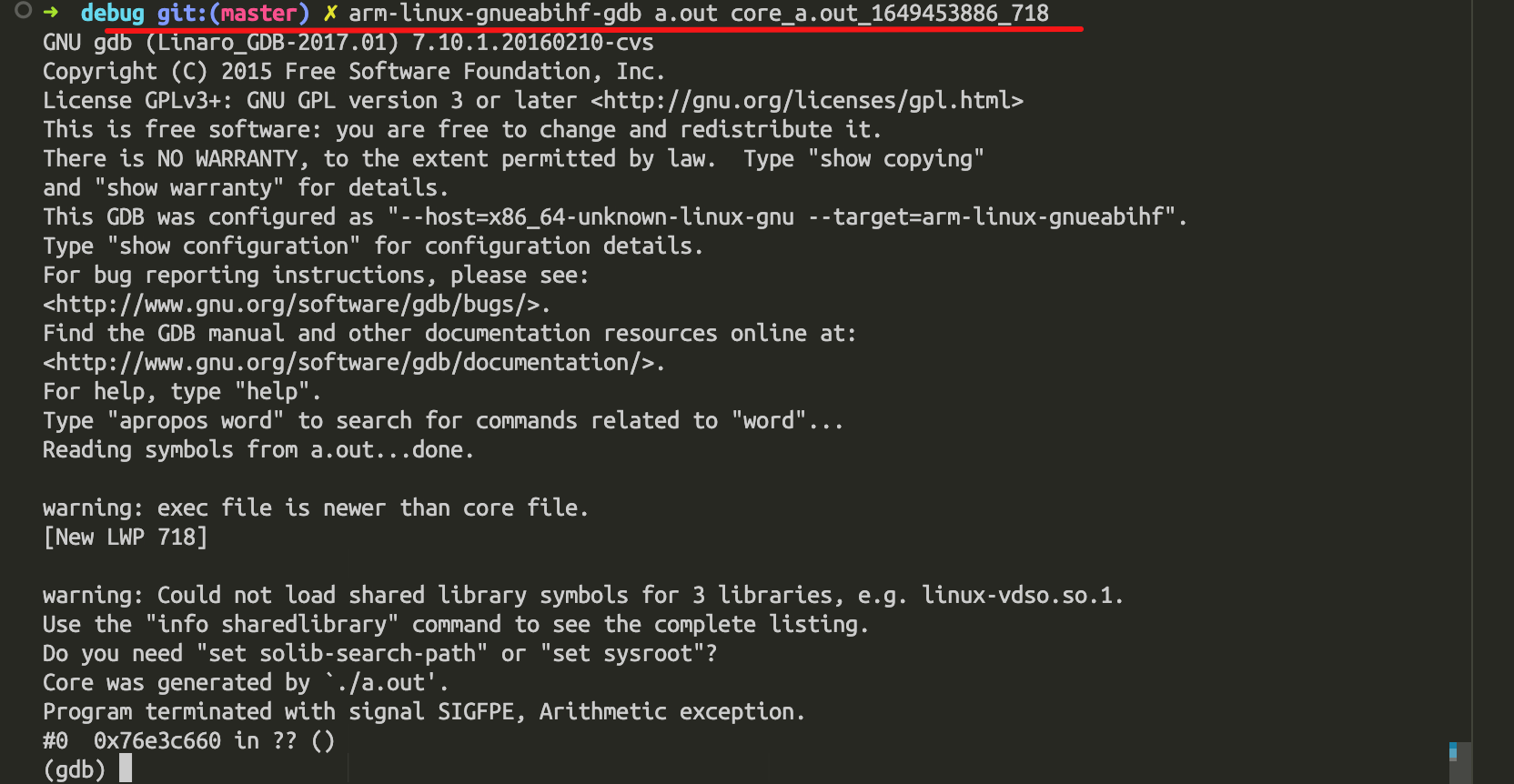
gdb打开core文件时,有的显示没有调试信息(no debugging symbols found),因为之前编译的时候没有带上-g选项,没有调试信息是正常的,实际上它也不影响调试core文件。因为调试core文件时,机器依的符号信息都依赖于符号表,用不到调试信息,调试信息是给人看的。
进入的时候coredump就给出了内存炸了原因:program terminated with signal SIGFPE, arithmetic exception,来自于浮点运算。
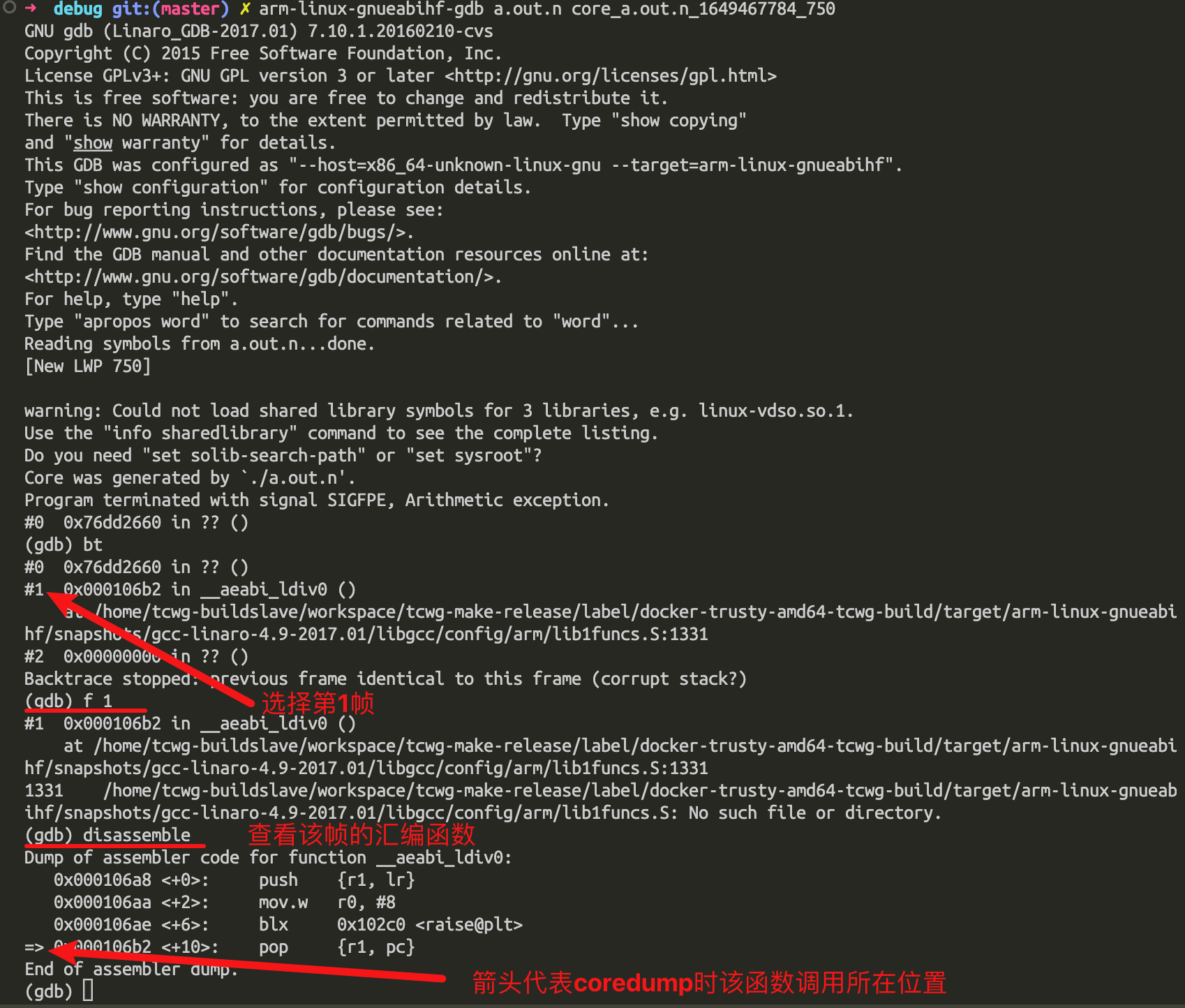
查看堆栈使用bt或者where命令:
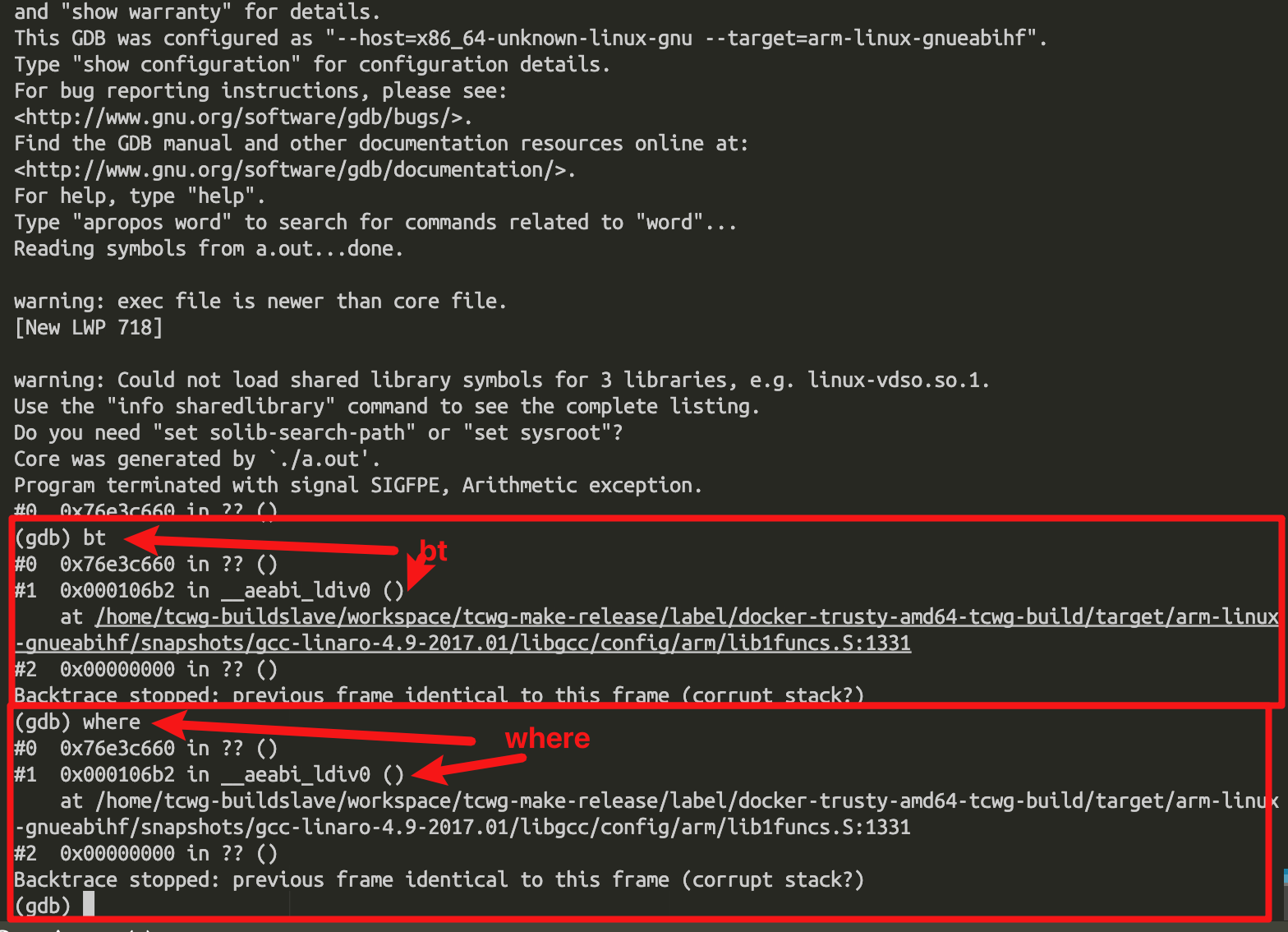
从图中使用bt和where都可以调出堆栈线程的调用情况,最后程序死在哪里。前面带#叫做帧。如上,在带上调试信息的情况下,我们实际上是可以看到core的地方和代码行的匹配位置。但往往正常发布环境是不会带上调试信息的,因为调试信息通常会占用比较大的存储空间,一般都会在编译的时候把-g选项去掉。没有调试信息的情况下找core的代码行,此时,frame addr(帧数)或者简写如上,f 1 跳转到core堆栈的第1帧。因为第0帧是libc的代码,已经不是我们自己代码了。disassemble打开该帧函数的反汇编代码。
我们也可以使用info reg来查看当前寄存器的现场。
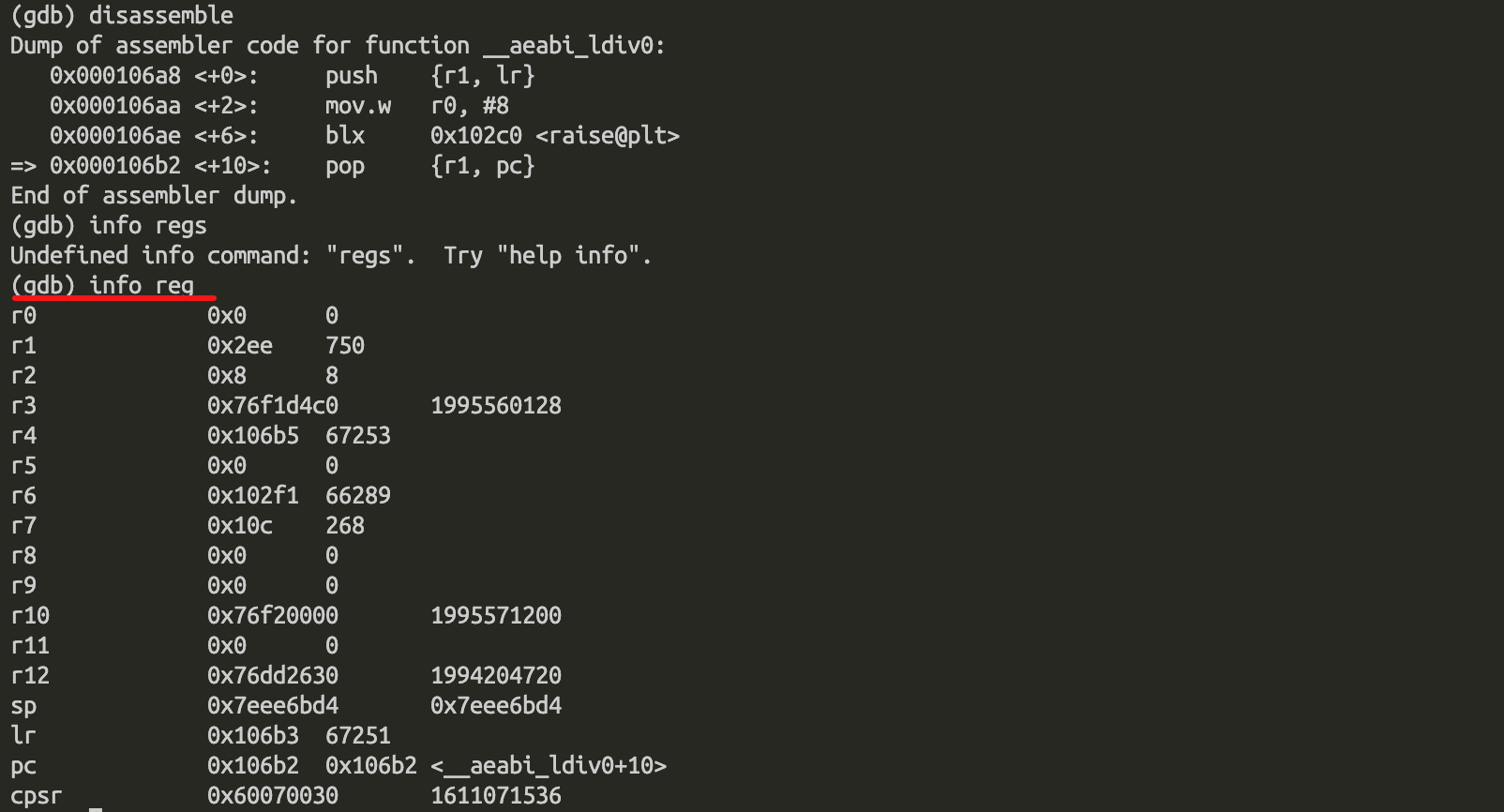
如此,我们就能知道我们coredump的位置,从而进一步能推断出coredump的原因。当然,现实环境中,coredump的场景肯定远比这个复杂,都是逻辑都是一样的,我们需要先找到coredump的位置,再结合代码以及core文件推测coredump的原因。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
#define NUM_THREADS 5 //线程数
int count = 0;
// arm-linux-gnueabihf-g++ -g test_core_thread.cpp -o a.thread.out -lpthread
void* say_hello( void *args )
{
while(1)
{
sleep(1);
cout<<"hello..."<<endl;
if(NUM_THREADS == count)
{
char *pStr = "";
delete pStr; // 多线程非法释放删除字符串区域的数据
}
}
} //函数返回的是函数指针,便于后面作为参数
int main()
{
pthread_t tids[NUM_THREADS]; //线程id
for( int i = 0; i < NUM_THREADS; ++i )
{
count = i+1;
int ret = pthread_create( &tids[i], NULL, say_hello,NULL); //参数:创建的线程id,线程参数,线程运行函数的起始地址,运行函数的参数
if( ret != 0 ) //创建线程成功返回0
{
cout << "pthread_create error:error_code=" << ret << endl;
}
}
pthread_exit( NULL ); //等待各个线程退出后,进程才结束,否则进程强制结束,线程处于未终止的状态
}编译arm-linux-gnueabihf-g++ -g test_core_thread.cpp -o a.thread.out -lpthread
运行之后出现:

由于上面代码里在count等于5的时候,会delete一个未初始化的指针,肯定会coredump。
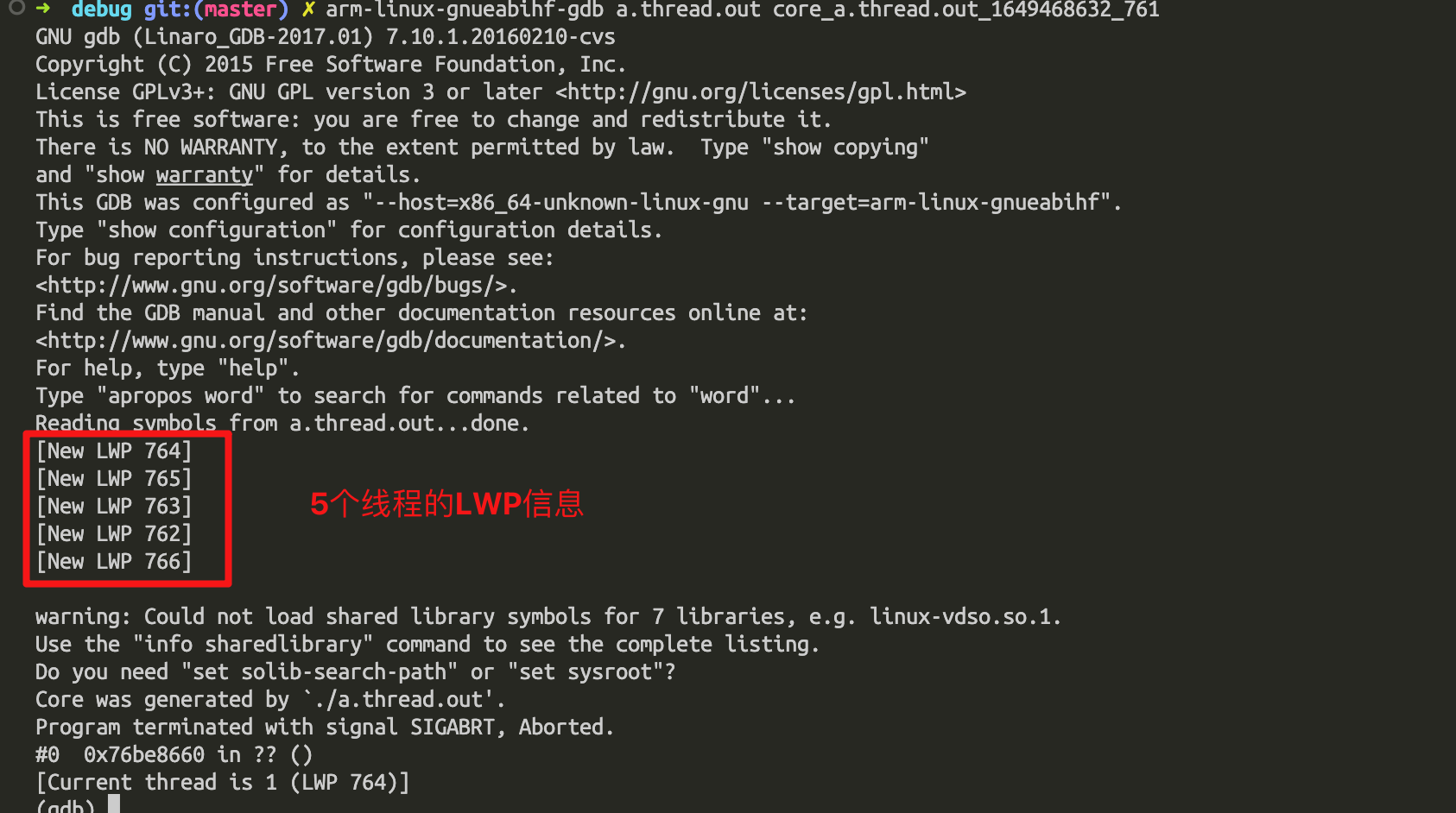
如何,查看每个线程的堆栈信息呢?首先,info threads查看所有线程正在运行的指令信息:

thread apply all bt打开所有线程的堆栈信息:
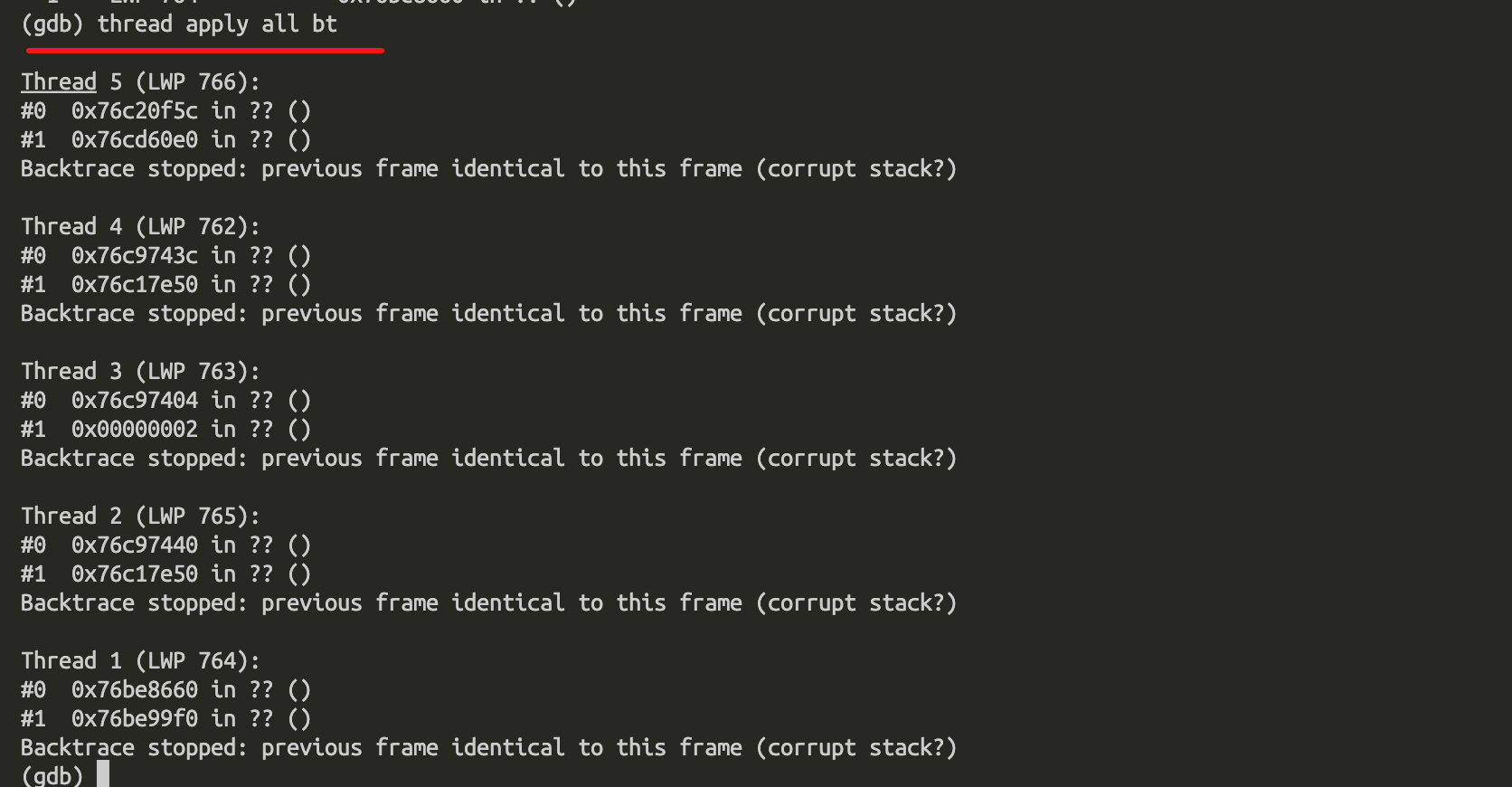
查看指定线程堆栈信息:threadapply threadID bt,如:

进入指定线程栈空间:
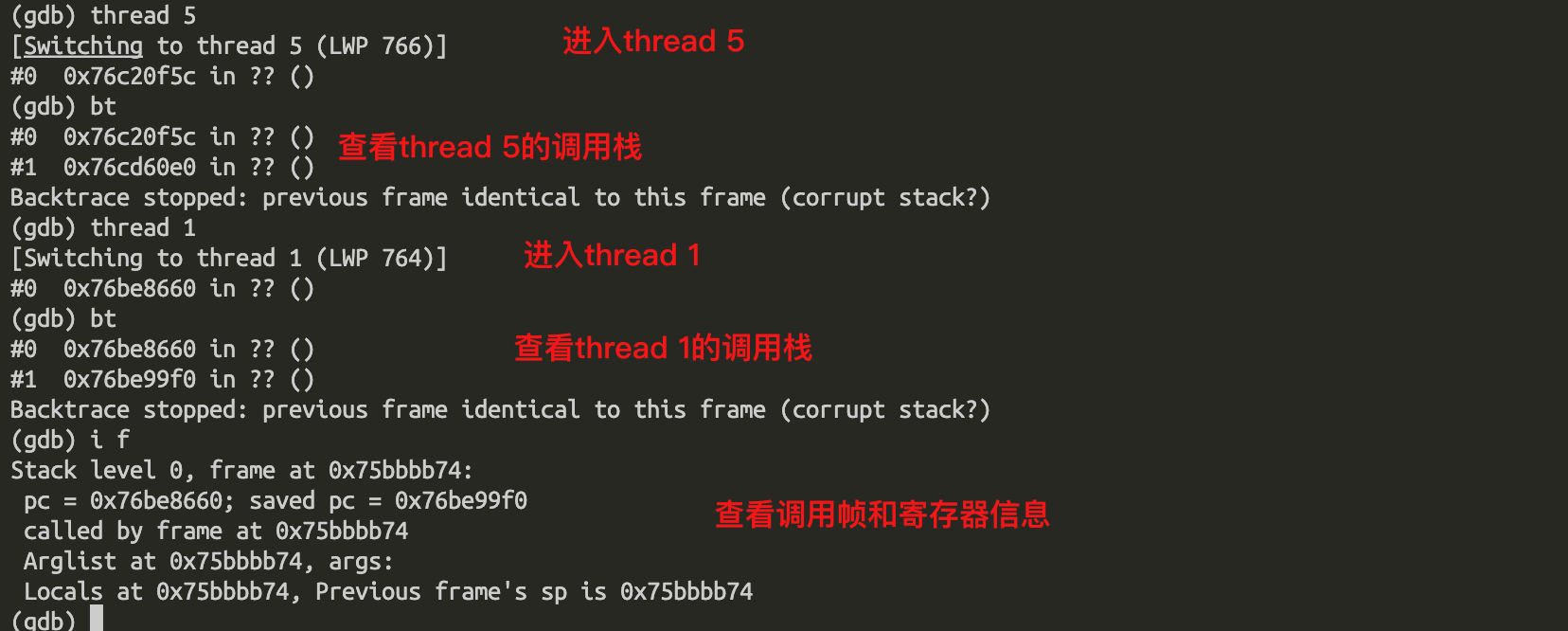
如上截图所示,可以跳转到指定的线程中,并查看所在线程的正在运行的堆栈信息和寄存器信息。
如上,简单介绍了3种不同情况下的gdb调试coredump文件的情况,基本涵盖了调试coredump问题时的大部分会用到的gdb命令。
gdb调试coredump,大部分时候还是只能从core文件找出core的直观原因,但是更根本的原因一般还是需要结合代码一起分析当时进程的运行上下文场景,才能推测出程序代码问题所在。
因此gdb调试coredump也是需要经验的积累,只有有一定的功底和对于基础知识的掌握才能在一堆二进制符号的core文件中找出问题的所在。23145
code:
https://github.com/carloscn/clab/tree/master/arm/debug