I've recently shifted from a straight engineering job to a job with a "dev/ops" title. What I have discovered in operations land depresses me. The shoemaker's children are going unshod. Operations software is terrible.
What's driving me craziest right now is my monitoring system.
What I have right now is Nagios.
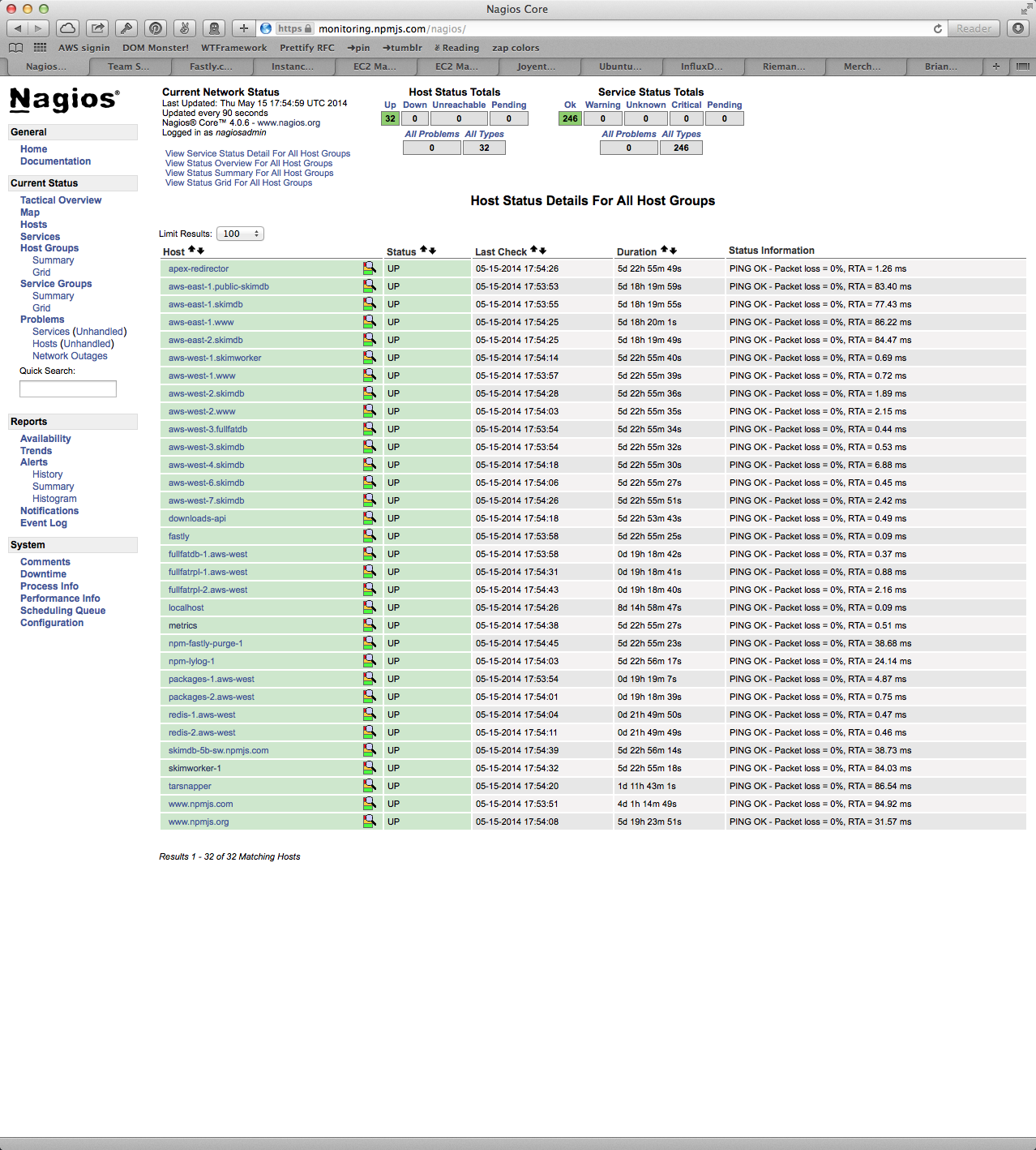
This display is intended to tell me if the npm service is running well.
Nagios works like this: You edit its giant masses of config files, adding hosts and checks manually. A check is an external program that runs & emits some text & an exit status code. Nagios uses the status code as a signal for whether the check was ok, warning, critical, or unknown. Checks can be associated with any number of hosts or host groups using the bizarre config language. Nagios polls these check scripts at configurable intervals. It reports the result of the last check to you next to each host.
- The checks do all the work.
- The latency is horrible, because Nagios polls instead of receiving updates when conditions change.
- The configuration is horrible, complex, and difficult to understand.
- Nagios's information design is beyond horrible and into the realm of pure eldritch madness.
This. This is the state of the art. Really? Really?
Nagios is backwards. It's the wrong answer to the wrong question.
Let's stop thinking about Nagios.
Are my users able to use my service happily right now?
Secondary questions:
Are any problems looming?
Do I need to adjust some specific resource in response to changing needs?
Something just broke. What? Why?
- Collect data from all your servers.
- Interpret the data automatically just enough to trigger notifications to get humans to look at it.
- Display that data somehow so that humans can interpret it at a glance.
- Allow humans to dig deeply into the current and the historical data if they want to.
- Allow humans to modify the machine interpretations when needed.
From this we get our first principle: Monitoring is inseparable from metrics.
Everything you want to monitor should be a datapoint in a time series stream (later stored in db). These datapoints should drive alerting inside the monitoring system. Alerting should be separated from data collection-- a "check" only reports data!
Store metrics data! the history is important for understanding the present & predicting the future
Checks are separate from alerts. Use the word "emitters" instead: data emitters send data to the collection system. The collection service stores (if desired) and forwards data to the real-time monitoring/alerting service. The alerting service shows current status & decides the meaning of incoming data: within bounds? out of bounds? alert? Historical analysis of data/trends/patterns is a separate service that draws on the permanent storage.
- Monitored things should push their data to the collection system, not be polled.
- Current state of the system should be available in a single view.
- Out-of-bounds behavior must trigger alerts.
- The alerting must integrate with services like PagerDuty.
- Data must be stored for historical analysis.
- It must be straightforward to add new kinds of incoming data.
- It must be straightforward to add/change alert criteria.
Another principle: build as little of this as possible myself.
- Consul: service discovery + zookeeper-not-in-java + health checking. See this description of how it compares to Nagios.
Consul looks like this:
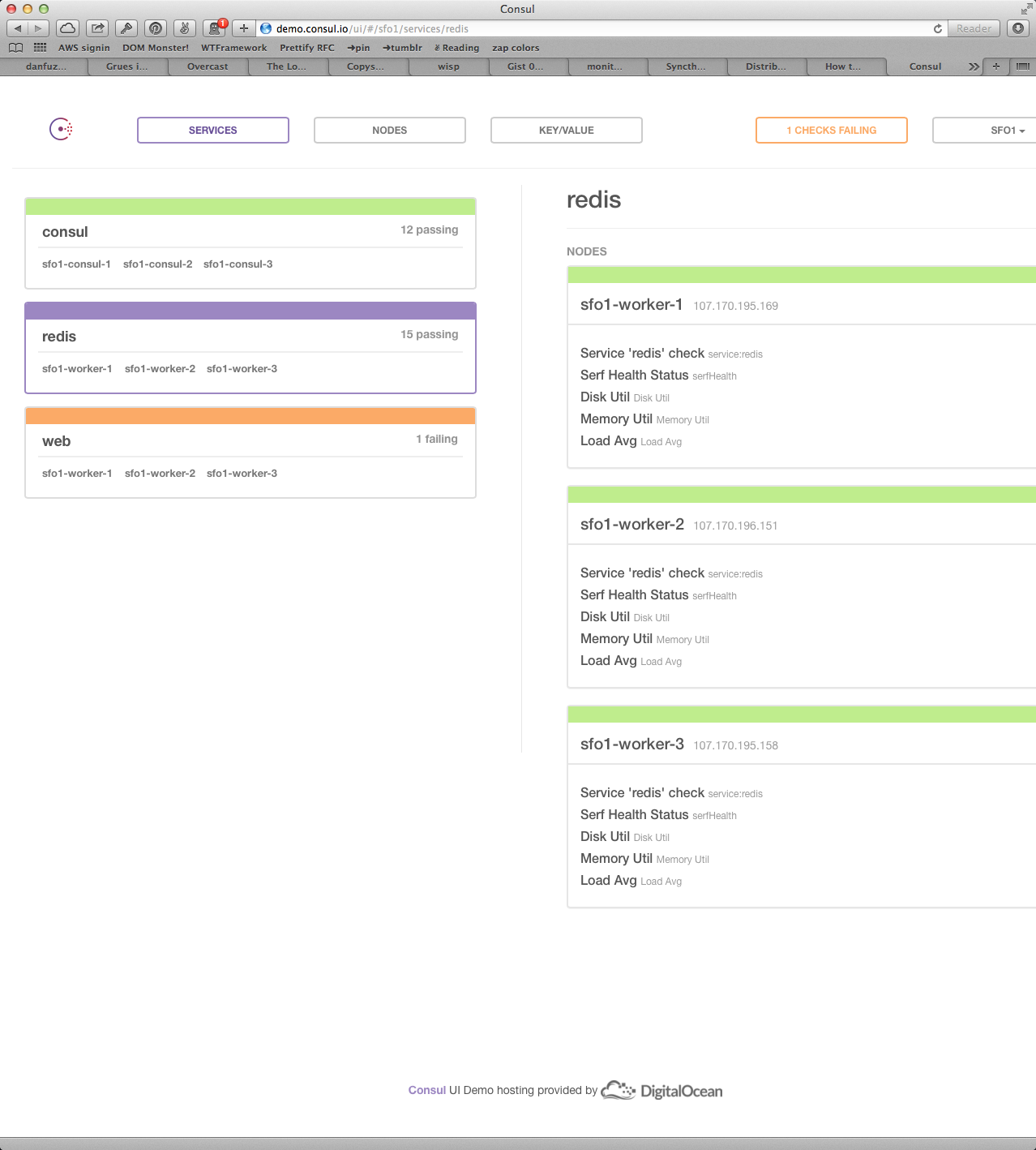
Therefore it is not acceptable as a dashboard or for analysis. In fact, I'd use this display only for debugging my Consul setup.
- Riemann: accepts incoming data streams & interprets/displays/alerts based on criteria you provide. Requires writing Clojure to add data types. Can handle high volumes of incoming data. Does not store. (Thus would provide the dashboard & alerting components of the system, but is not complete by itself.)
Riemann looks like this:
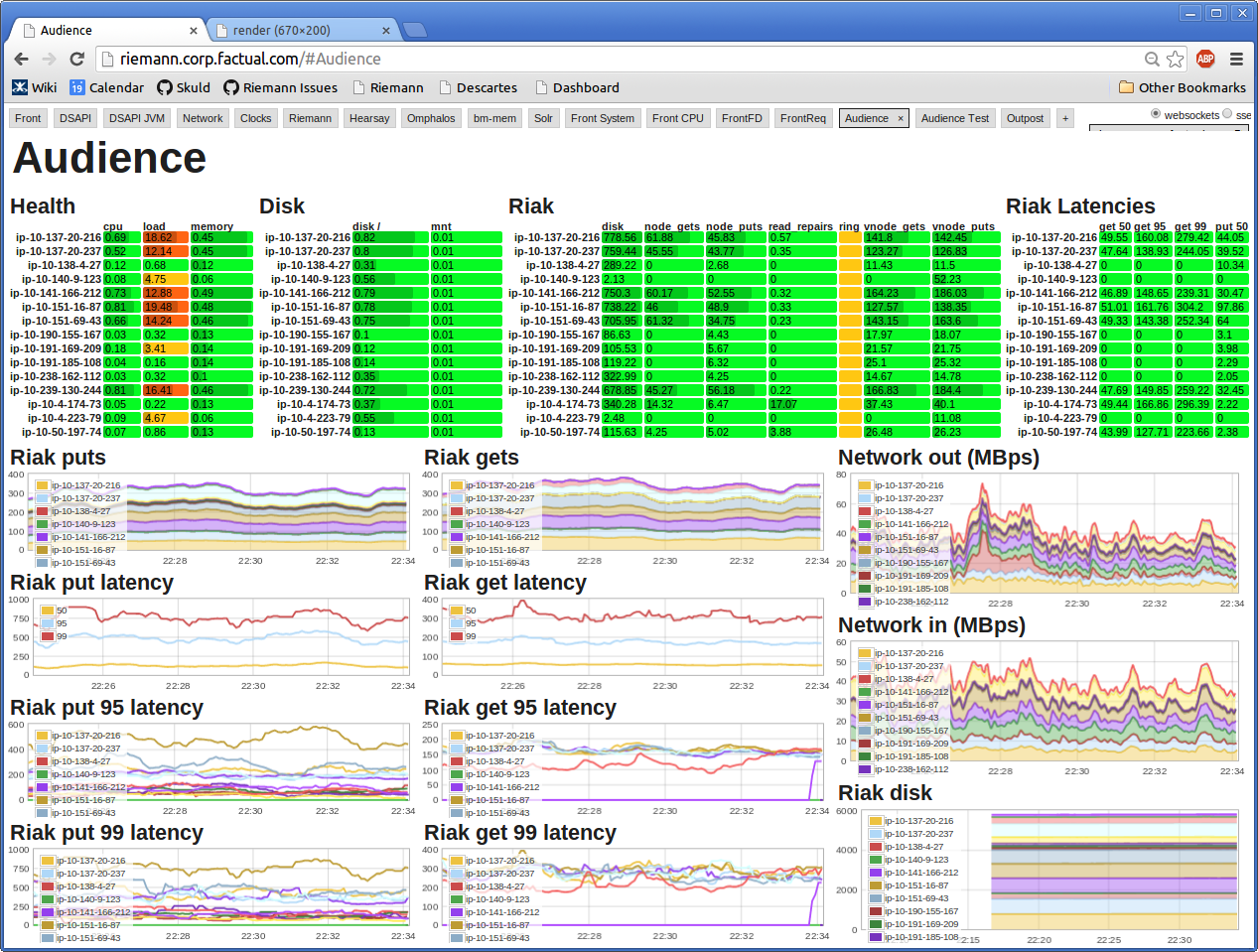
This will win no awards from graphic designers but it is a focused, information-packed dashboard. It wins a "useful!" award from me.
-
Time series database to store the metrics data. InfluxDB is probably my first pick.
-
Grafana to provide a dashboard.
- Consul as agent/collector (our ansible automation can set up consul agents on new nodes easily)
- Riemann for monitoring & alerting
- data needs to be split out of consul & streamed to riemann & the timeseries db
- build dashboarding separately or start with Riemann's sinatra webapp (replace with node webapp over time)
- Custom emitters & a collector/multiplexer (statsd-inspired)
- Riemann
- InfluxDB
- Grafana
Who needs Consul? Just write agents fired by cron that sit on each host or in each server emitting whenever it's interesting to emit. Send to Riemann & to the timeseries database. Riemann for monitoring, hand-rolled dashboards for historical analysis. (Voxer's Zag is an inspiration here, except that I feel it misses its chance by not doing alerting as well.)
Now the million-dollar question: what's the opportunity cost of this work next to, say, working on npm's features? And now we know why dev/ops software is so terrible.
But I'm going to work on this on the weekends, because I want it a lot.
I did an implementation spike with InfluxDB, Riemann, and a custom emitter/collector modules I wrote. I've rejected Riemann as unsuitable for a number of reasons (jvm, clojure to configure, fragile/poor dashboard), but InfluxDB looks great so far. Grafana also looks great for historical/longer-term dashboards. My next implementation spike will feature Mozilla's heka and an exploration of what it would take to write the short-term data flow display/alerting/monitoring piece myself.
If you'd rather not write your own collector/multiplexer check out heka. We use it for both log aggregation and stats. Its also got some basic graphing and alerting, scriptable with lua.