Blog 2019/7/1
<- previous | index | next ->
Revisiting this again with some co-workers.
This time around I've tried to split up the code into some reusable chunks.
This grammar makes sense to us as humans, but demonstrates a weakness of recursive descent: that it can't do left recursion (it leads to infinite recursion).
# grammar:
# expr: infix | num
# infix: expr op expr
# op: plus | star
# num: /\d+/
# plus: /\+/
# star: /\*/
$ echo '1+1' | ./mathterp1.py
...
File "./mathterp1.py", line 48, in parse_infix
(ltree, tokens1) = parse_expr(tokens)
File "./mathterp1.py", line 61, in parse_expr
(tree, tokens1) = parse_infix(tokens)
File "./mathterp1.py", line 48, in parse_infix
(ltree, tokens1) = parse_expr(tokens)
File "./mathterp1.py", line 61, in parse_expr
(tree, tokens1) = parse_infix(tokens)
File "./mathterp1.py", line 48, in parse_infix
(ltree, tokens1) = parse_expr(tokens)
RuntimeError: maximum recursion depth exceeded
The way to address this is by modifying the grammar. This brings up a trade-off with recursive descent: that you often end up creating an unintuitive grammar in order to satisfy the limitations of recursive descent.
This grammar avoids the infinite loop because it is right-recursive.
# grammar:
# expr: infix | num
# infix: num op expr
# op: plus | star
# num: /\d+/
# plus: /\+/
# star: /\*/
$ echo '1+1' | ./mathterp2.py --graphviz
=> 2
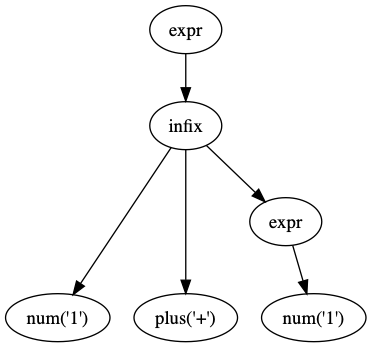
However, it can't deal with operator precedence rules (3+1 is evaluated first, which is incorrect):
$ echo '2*3+1' | ./mathterp2.py --graphviz
=> 8
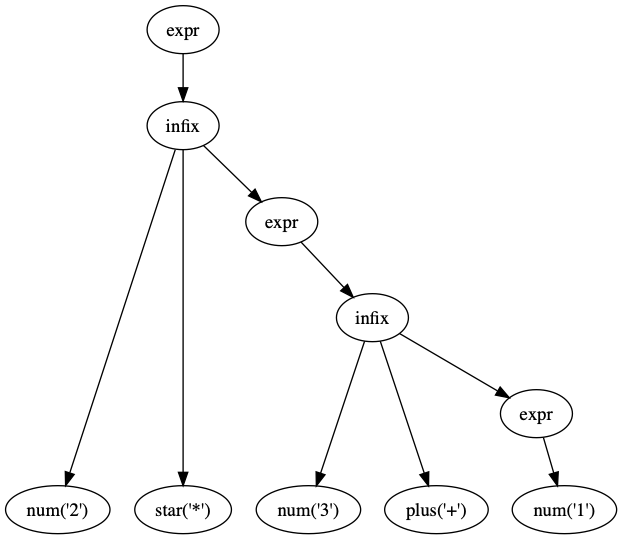
and it can't deal with associativity (2-1 is evaluated first, which is incorrect):
$ echo '3-2-1' | ./mathterp2.py --graphviz
=> 2
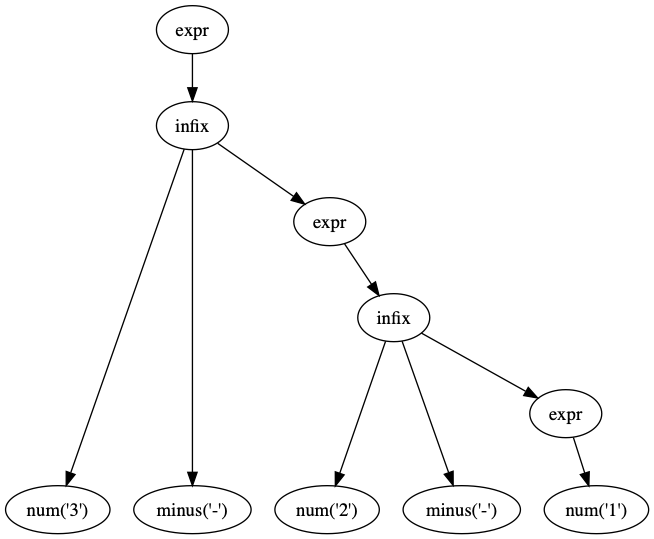
We can implement this grammar, which will address operator precedence, but still doesn't address associativity.
# grammar:
# expr: term
# term: factor plus term
# factor: num star factor
# num: /\d+/
# plus: /\+/
# star: /\*/