-
100%の時間 利用可能なサービスはない
- 配慮のないクライアント
- 50倍の要求
- (訳注: 上記2つはPokemon Goのことでもある)
- スラフィックのスパイク
- 海底ケーブルの切断
-
私達のサービスに依存するユーザーがいる
- 可能な限り信頼性を高めるにはどうすればよいのか?
-
この11章ではGoogleのトラフィック管理方法について説明
-
(訳注: 前半はGoogleのロードバランサの仕組みを説明しており、その部分は直接SREに役立つ)
- 最近の多くの企業は自社で独自のロードバランサを開発・メンテしていない
- 大手クラウドプロバイダーのものを使うことを選択している
- ここではGoogleのGCLB(Google Cloud Load Balancing)について説明
- 紹介するベストプラクティスは他のクラウドプロバイダーのものでも適用可能
- 18年間に渡り、サービスを高速かつ信頼性の高いものにするためのインフラを構築してきた
- YouTube, Googleマップ, Gmail, Google検索 等々でこれらのシステムを使用している
- GCLBは社内で開発したシステムを外部向けに公開したものの一つ
- DNSロードバランシング
- 前SRE本の19章では、DNSベースの負荷分散が、ユーザーの接続が開始する前に負荷を分散するシンプルかつ効果的な方法として説明
- 固有の問題として、DNSレコードをうまく期限切れにして再取得するにはクライアント側との協力に基づいてしまう
- GCLBではこの問題のためDNSロードバランシングを使用しない
- 代わりにエニーキャストを使用
- 前SRE本の19章では、DNSベースの負荷分散が、ユーザーの接続が開始する前に負荷を分散するシンプルかつ効果的な方法として説明
- エニーキャスト
- DNSの地理情報に頼らずに、最も近いクラスタへ送信する方法
- GCLBはクライアントの場所を知っていて、最も近いWebサービスへパケットを転送する
- 単一のVIP(仮想IP)を使用しながら低レイテンシ
- 単一のVIPはDNSレコードのTTLを長くすることができ、レイテンシをさらに低くできる
-
エニーキャスト
- ネットワークアドレス指定とルーティングの方法
- 単一の送信者からのデータグラムを、トポロジ的に最も近いノードへルーティングする
- 全て同じ宛先IPアドレスとして識別される
- GoogleはそのIPアドレスをGoogleのネットワーク内複数の地点からBGP経由でアナウンスしている
- ユーザーから最も近いフロントエンドへパケットを伝送するのにBGPルーティングメッシュを使用している
- フロントエンドではTCPセッションを終わらせることができる
- 以下の2つの問題を解決できる
- ユニキャストIPの急増
- ユーザーに最も近いフロントエンドの発見
- しかし2つの大きな問題が残っている
- 近くのユーザーが多すぎる際に、フロントエンドを過負荷にしてしまう可能性
- BGPルート計算によってコネクションがリセットされる可能性
- 例えば頻繁にBGPルートを再計算するISPがあると...
- 例えば、2つのフロントエンドサイトの内、1ユーザーについてどちらかのフロントエンドを優先させるため
- BGPルートが「フラップ」する度に、通信途中のTCPストリームがリセットされてしまう
- TCPセッション状態が無い状態で新しいフロントエンドに転送されるため
- (訳注: 参考 Qiita - TCPの状態遷移 )
- これらの問題に対処するために、Googleでは後に説明するMaglevを使用
- コネクションレベルのロードバランサ
- ルートフラップが起きてもTCPストリームは一貫して続く
- この手法を Stabilized エニーキャスト と呼んでいる
-
(訳注: 参考 IP anycastについて 頑張れIP anycast)
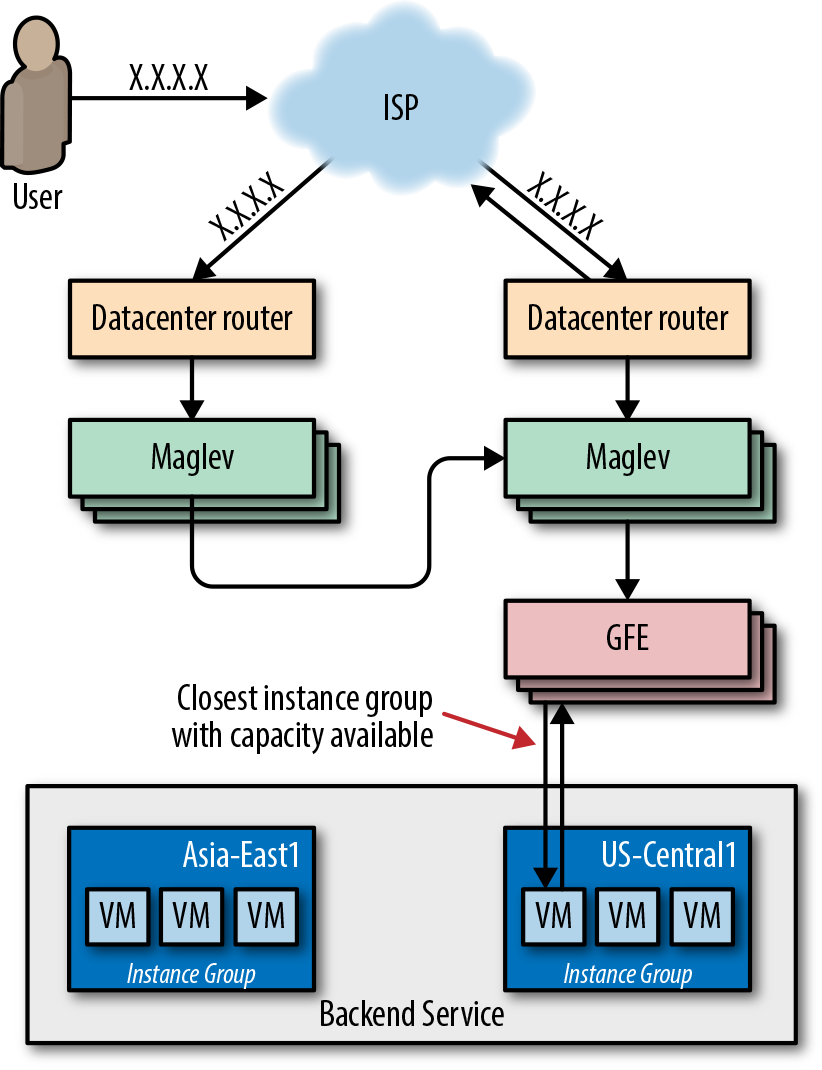
- Googleは独自のロードバランサであるMaglevを使用してstabilizedエニーキャストを実装
- (図11-1を参照)
- エニーキャストを安定化させる
- 各Maglevマシンに対して、クライアントIPアドレスを最も近いGoogleフロントエンドサイトへとマッピングさせる方法を提供
- MaglevはエニーキャストVIP宛てのパケットについて、他のフロントエンドサイトに近いクライアントの場合
- Maglevはそのパケットを、より近いフロントエンドサイトの別のMaglevへと転送する
- 最も近いフロントエンドサイトのMaglevマシンはそのパケットを通常のパケットと同じように扱い、ローカルのバックエンドへとルーティングする

-
MaglevはGoogle独自の分散型パケットレベルロードバランサ
- (図11-2を参照)
- クラスタの受信トラフィックを管理
- フロントエンドサーバーに対してステートフルなTCPレベルのロードバランシングを提供
-
いくつかの点で従来のハードウェアロードバランサと異なる
-
特定のIPアドレス宛の全パケットは、ECMP経由でMaglevマシンプール全体に均等に分散可能
- プールにサーバーを追加するだけでMaglevの容量を増やすことができる
- パケットの分散によりMaglevの冗長性をN+1としてモデル化することも可能になり、可用性と信頼性が従来よりも向上する
- 冗長性について、N+1は予備の機器が1個ある状態、2Nはアクティブ機とスタンバイ機が同じ数ある状態
-
Google独自のソリューションなので、エンドツーエンドで制御可能で、迅速に実験のPDCAが回せる
-
GoogleのiDC上のコモディティハードウェア上で稼働しており、デプロイが非常にシンプルになる
-
-
Maglevではコンシステントハッシュ法とコネクショントラッキングをパケット配信に使用
- TCPセッションを終了させるHTTPリバースプロキシ(= GFS | Google Front Ends)でTCPストリームを結合させる
- Maglevはパケット単位(≠ 接続数)でスケールするためコンシステントハッシュ法とコネクショントラッキングが重要
- ルーターは、MaglevのVIP宛てのパケットを受信すると、そのパケットをECMP経由でクラスタ内のMaglevマシンへ転送する
- Maglevはパケットを受信すると、パケットの5タプル ハッシュ1のハッシュ値をコネクショントラッキングテーブルでルックアップする
- 5タプルは IPヘッダ上の SourceIP, SourcePort, DestinationIP, DestinationPort, プロトコル, の5つの要素
- コネクショントラッキングテーブルには最近の接続ルーティング結果が含まれている
- もしマッチする結果があり、そのバックエンドサービスが正常であればその接続を再利用する
- それ以外の場合はコンシステントハッシュ法で選択したバックエンドへフォールバックする
- Maglevはパケットを受信すると、パケットの5タプル ハッシュ1のハッシュ値をコネクショントラッキングテーブルでルックアップする
- これらの手法によって個々のMaglev間で接続状態を共有する必要がなくなる
-
(訳注)

- GSLB
- Googleのグローバルソフトウェアロードバランサ
- サービスのキャパシティに合わせて、クラスタ間でライブユーザーのトラフィックのバランシングを行うことができる
- ユーザーには透過的なので、サービス障害に対応可能
- GFEへの接続とバックエンドサービスへのリクエストの両方を制御する
- (図11-3を参照)
- フロントエンドとバックエンド間の負荷分散だけではなく、サービスの健全性も理解している
- 障害時には自動でそのクラスタからトラフィックを逃がす
- (訳注)
- 各社LBの比較: ロードバランサのアーキテクチャいろいろ

- GFE
- Googleのサービス(Gmail, Web検索等)と外部との間に存在する
- 大抵の場合、クライアントのHTTP(S)の要求を最初に受け付けるGoogleのサーバー
- (図11-4を参照)
- クライアントのTCP, SSLのセッションを終了させる
- HTTPヘッダーとURLパスをチェックしてどのバックエンドサービスが適切かを判断する
- バックエンドのヘルスチェックも担当している
- ネガティブな応答("NACKs")やタイムアウトになったバックエンドには、トラフィックを送信するのを止める
- ユーザーからのリクエストを止めることなく、GFEバックエンドをサービスから適切に削除できる
- "lame duck" モード
- (指定ポートでリッスンしており機能するが、リクエスト送信を止めるようにクライアントに明示的に要求している状態)
- 直近でアクティブなバックエンドへの永続セッションを維持している
- リクエストが到着するとすぐに接続が利用可能
- 特にGFEとバックエンド間でSSLを使用している場合はレイテンシを減らすことができる
- Googleのサービス(Gmail, Web検索等)と外部との間に存在する
- Googleのネットワーク戦略ではエンドユーザーのレイテンシを減らすことを目標にしている
- HTTPS経由でのセキュアな接続を行うにはクライアントとサーバー間で2往復のネットワークトリップが必要
- (訳注: TLS1.2以下の場合は2往復, TLS1.3では1往復になるらしい)
- そのため、エッジネットワークを拡張し、MaglevとGFEをホストするようにした
- ユーザーにできるだけ近いところでSSLを終了させ、再暗号化してネットワークの奥にあるバックエンドサービスへ転送
- HTTPS経由でのセキュアな接続を行うにはクライアントとサーバー間で2往復のネットワークトリップが必要
- GCLB
- Maglev/GFEで拡張されたエッジネットワークの上に構築した
- 顧客がロードバランサを作成する際には、エッジネットワーク上のGFE間でグローバルに負荷分散するようにエニーキャストVIPとMaglevを配置している
- GFEの役割
- SSLを終了させる
- HTTPリクエストを受け付けてバッファに入れる
- リクエストを顧客のバックエンドサービスへ転送し、ユーザーへレスポンスを戻すようにプロキシする
- GSLBは各レイヤ間の接着剤となる
- このおかげでMaglevは、利用可能なキャパシティがあって最も近いGFEのロケーションが分かる
- GFEは、利用可能なキャパシティをあって最も近いVMインスタンスグループへリクエストをルーティングできる
- GCLBは99.99%のSLAの高い可用性を提供している
- 便利なサポートツールも提供
- ロードバランサをトラフィック管理システムと考えると便利
- GCLBは利用可能なキャパシティがあり最も近いバックエンドへルーティングする
- サービス中に失敗したインスタンスがある場合には、GCLBはその失敗を検知し正常なインスタンスへとルーティングする
- カナリアリリースと段階的ロールアウト
- カナリアリリース
- 極少数のサーバーにデプロイしてから徐々にトラフィックを増やしていき、システムの動作を監視して未知のバグが出ていないか確認する
- 新バージョンがクラッシュしたりヘルスチェックに失敗している場合は、ロードバランサはそのバージョンを使わない
- 軽微なバグの場合でも、ロードバランサからそのインスタンスグループを削除可能
- Pokémon GO
- Nianticが2016年夏にローンチ
- ローンチ前にトラフィック見積もりの5倍までは負荷テストをしていた
- 実際のRPS(Request per sec)は見積もりの50倍だった
- Nianticのエンジニアリングチームの努力とGoogle全体の援助によってスケールできた
- GCLBに移行後、ポケモンGOは他のトップ10GCLBサービスと同等規模で、最大の単一GCLBサービスとなった
- NLB時代
- Googleのリージョナルロードバランサ
- (図11-5参照)
- NLBを使用してKubernetesクラスタ全体の受信トラフィックをロードバランシングしていた
- 各クラスタにはNginxのポッドがある
- SSLの終了, HTTPリクエストのバッファリング、L7リバースプロキシとして動作
- NLBはIP層でのロードバランシングを担当するため、NLBにうまくマッチするサービスはMaglevのバックエンドになるもの
- ポケモンGOでは次の3つの影響があった
- NginxがSSLを終了させる責任があるため、クライアントからNginxまでの2回のラウンドトリップが必要となる
- クライアントからのHTTPリクエストをバッファする必要があり、特にクライアントの通信速度が遅い場合にプロキシ層でリソースが枯渇していた。
- SYNフラッドのような低レベルのネットワーク攻撃に対して、パケットレベルのプロキシではうまく対処できなかった
- うまくスケールさせるためには大規模なエッジネットワーク上で動作する高レベルのプロキシが必要
- NLBではこれは不可能

- NLBからGCLBへ
- 大規模なSYNフラッドが原因でGCLBへの移行の優先度が高くなった
- NianticとGoogle CREチーム, SREチームの共同作業
- 最初の移行はピークではない時に行われ、特に何もなかった
- しかしトラフィックがピークに達するにつれ、NianticとGoogleに予期せぬ問題が発生した
- ポケモンGOの実際のクライアントのリクエストはこれまでに把握していたよりも200%高かった
- Nianticのフロントエンドプロキシは非常に多くのリクエストを受信したせいで、全ての受信接続を捌ききれなかった
- 拒否された接続は受信リクエストの監視には現れず、バックエンドまで到達しなかった
- このトラフィックの急増のせいで、いくつもの障害が発生した
- クラウドデータストア、ポケモンGOのバックエンド、ロードバランサはNianticのクラウドプロジェクトのキャパシティを超えた
- 過負荷により、Nianticのバックエンドはリクエストを拒否せずに極端に遅くなったため、ロードバランサ層でタイムアウトした
- この状況でロードバランサはGETリクエストを再試行したため、システム負荷を増加させた
- 超大量のリクエストと再試行の組み合わせによって、GFEのSSLクライアントコードにこれまでにないレベルで負荷がかかり、無応答のバックエンドに再接続をしようとしていた
- このせいでGFEのパフォーマンスが低下し、GCLBの世界全体のキャパシティが実質的に50%落ちた
- クライアントの再試行
- ポケモンGOアプリは失敗したリクエストをユーザーの代わりに再試行していた
- すぐに1回再試行し、その後に一定のバックオフとともに再試行
- サービス停止状態が続くと、サービスから大量のクイックエラーが返却された
- 例: 共有バックエンドの再起動時
- これらのエラーのせいでクライアントの再試行が同期してしまう
- Thundering Herd問題を引き起こす
- 同時リクエストのスパイクによって、グローバルRPSのピークは20倍まで急激に増加した
- (図11-6参照)
- ポケモンGOアプリは失敗したリクエストをユーザーの代わりに再試行していた

- リクエストのスパイクとGFEキャパシティの低下によって、全てのGCLBサービスがキューイングと長いレイテンシをもたらした
- オンコールのトラフィック担当SREチームは、次の方法で他のGCLBユーザーの被害を軽減した
- メインのロードバランサプールからGFEを隔離させ、ポケモンGOのトラフィックを処理するようにした
- ピーク時のトラフィックをさばけるようになるまで、パフォーマンス低下が起きても隔離されたポケモンGOプールを拡大した
- キャパシティのボトルネックはGFEからNiantic側へと移動
- サーバーはまだタイムアウトしていた。特にクライアントの再試行が同時発生しスパイクし始めた時
- トラフィック担当SREは、ポケモンGOの代わりにロードバランサが受けるトラフィックのレートリミットを無効化する管理機能を実装した
- Nianticが通常のオペレーションを再確立し、スケールを開始するのに十分なクライアントの要求が含まれていた
- 最終的なNW構成は図11-7の通り

- GoogleとNianticはシステムに大きな変更を加えた
- Nianticはジッターと切り捨て型指数バックオフを導入した
- 同時リクエストスパイクを抑制
- GoogleはGFEバックエンドが負荷の原因となりうることがある学んだ
- 遅かったり不正な動作をするバックエンドのせいによるGFEのパフォーマンス低下を検出するための資格と負荷テストプラクティスを制定した
- Nianticはジッターと切り捨て型指数バックオフを導入した
- クライアントにできるだけ近いところで負荷を測定する必要性に気づいた
- もしNianticとGoogleCREがクライアントのRPS要求を正確に見積もることができていたら...
- GCLBへの切り替えを行う前に、Nianticの割当リソースを前もってスケールアップさせていたはず
- オートスケール
- スケールアップ(垂直スケール)でもスケールアウト(水平スケール)でも正しく使えば可用性を高める事ができる
- 設定ミスや使い方を間違えると悪影響になる場合もある
- 以降ではベストプラクティス、ありがちな失敗モード、現在のオートスケーリングの制限について説明
-
オートスケールは全インスタンスの使用率を平均し、全インスタンスを同じ処理能力があるものとして扱う
- 正常でないマシンの使用率も平均に含まれる
- その場合にはオートスケールが行われない可能性あり
- 以下の問題が障害モードを引き起こす可能性あり
- 起動後の準備に長時間かかるインスタンス(ウォームアップやバイナリロード等)
- 処理可能ではない状態(ゾンビ状態)でずっと起動してしまっている
- 以下の手法をそのまま使ったり組み合わせたりして改善可能
- 正常でないマシンの使用率も平均に含まれる
-
ロードバランシング
- ロードバランサによって計測されたキャパシティのメトリクスを使用したオートスケール
- これによって正常ではないインスタンスの分のキャパシティは平均値から除外される
-
新しいインスタンスが安定化するのを待ってから、メトリクスを取得する
- オートスケールシステムを、新インスタンスが正常状態になってからメトリクスを取得するように設定する
- GCE(Google Compute Engine)ではこの正常ではない状態をクールダウン期間と呼んでいる
- オートスケールシステムを、新インスタンスが正常状態になってからメトリクスを取得するように設定する
-
オートスケールとオートヒール
- オートヒールはインスタンスを監視し、正常ではない場合に再起動を試みる
- 通常、オートヒールシステムによってインスタンスが公開しているヘルスメトリクスを監視するように設定する
- オートヒールシステムは、インスタンスが停止していたり異常だと検出すると再起動を試みる
- 再起動後にインスタンスが正常な状態になるのに十分な時間を与えるのが重要
-
上記の手法を組み合わせると、水平オートスケールを最適化して正常なマシンのみトラッキングできる
- オートスケールシステムは、サービスのインスタンス数を継続的に調整し続ける
- 新しいインスタンスを作成することはそんなに早くはできない
- ステートフルシステム
- 単一のユーザーセッションの全てのリクエストを同一のバックエンドサーバーへ送信する
- これが過負荷となっている場合はインスタンスの追加(水平スケール)は意味がない
- コンシステントハッシュ法を使用したりして、タスクレベルのルーティングで負荷を分散させるのが良い
- 自動スケールアップ(垂直スケール)はステートフルシステムで効果的
- タスクレベルルーティング+垂直スケールで短期のホットスポットを吸収できる
- 全インスタンスに適用されるため、トラフィックの少ないインスタンスは不必要にスケールアップしてしまう可能性あり
- 単一のユーザーセッションの全てのリクエストを同一のバックエンドサーバーへ送信する
- 自動スケールアップの設定の方が自動スケールダウンの設定よりも重要
- スケールアップを行うことのリスクは少ない
- 多くのオートスケールシステムは、トラフィックの低下よりも増加イベントに対してあえて敏感にしている
- スケールアップの際はすぐに追加キャパシティを追加
- スケールダウンする際はより慎重で、徐々にリソースを削減する
- ボトルネックになりやすいものに関してオートスケールシステムを構成する
- CPUとか
- 新しいインスタンスが立ち上がり準備完了するまでには少し時間が必要になる
- ユーザー向けサービスでは十分な予備キャパシティを確保しておくと良い
- オートスケールシステムの設定
- 間違っていると制御不可になる
- 例えば以下のような例
- CPU使用率によるオートスケールを設定
- アイドル状態でもCPUが無駄に消費されるバグのあるバージョンをリリース
- クォータの限界までスケールし続ける...
- 依存している他のシステムが失敗している場合
- 全リクエストが正常に完了せず、リソースが消費されてしまう
- オートスケールするとさらにトラフィックがスタックしてしまう
- 依存先システムへの負荷が増大し、復旧を妨げる恐れも有り
- スケールの上限と下限を設定し、十分なクォータがあることを確認する
- クォータの限界まで使ってしまうことを防ぐ
- オートスケールのkillスイッチ
- オートスケールで何か問題があったときに便利
- オンコール担当エンジニアがオートスケールを無効にする方法と、必要な場合に手動でスケールさせる方法を理解しているようにしておく
- killスイッチは簡単、わかりやすく、早く、きちんと文書化されているべき
- オートスケールシステムはトラフィックの増加に応じてスケールアップする
- バックエンドサービスは追加の負荷を吸収する必要がある
- DBとか
- バックエンドシステムの依存関係を事前に分析した方が良い
- サービスごとにスケール傾向が違う
- 追加したトラフィックを処理するのに十分なキャパシティがバックエンドにあるか
- 過負荷の場合には適切にデグレードすることができるか
- バックエンドサービスは追加の負荷を吸収する必要がある
- マイクロサービスがクォータを共有する場合
- トラフィックスパイクのために単一のマイクロサービスがスケールアップすると、クォータの大半を使い切る可能性あり
- サービスがその他のマイクロサービスに関連している場合、他のマイクロサービス向けのクォータがなくなる
- 依存関係を分析することで、予め限定的なスケール方法を実装することができる
- あるいはマイクロサービスごとにクォータを分けることも可能
- この場合はサービスを別々のプロジェクトに分ける必要があるかもしれない
- (訳注: プロジェクトはAWSでいうアカウント、GCPでいうプロジェクト)
- トラフィックスパイクのために単一のマイクロサービスがスケールアップすると、クォータの大半を使い切る可能性あり
- 一部のオートスケールシステムではリージョン間でインスタンスのバランスを取ることが可能
- 例: AWS EC2, GCP
- 通常のオートスケールに加え、リージョン間の各ゾーンのサイズを均等にしようとするジョブが実行される
- リバランスによって、大きなゾーンが出来てしまうことが防げる
- ゾーンごとにクォータがある場合は、クォータの利用率も均等にできる
- さらに障害ドメインの多様性も高まる
- 複雑なシステムでは、1つ以上の負荷管理戦略を使う必要があるかもしれない
- 例: 負荷に応じてスケールする複数のインスタンスグループを運用している
- キャパシティ確保のため、複数のリージョンにコピーする時
- リージョン間のトラフィックをバランスさせる必要がある
- このケースでは、ロードバランシングと負荷ベースでのオートスケーリングの両方を使う必要がある
- 例: 世界の3つの施設でWebサイトをホスティングしている場合
- 多くのマシンをデプロイするには数週間かかる
- レイテンシのために近くの地域で捌きたいが、↑があるため、溢れたトラフィックは他の地域に流れる必要がある
- もしソーシャルメディアで人気がでて、急にトラフィックが5倍に増えた場合、できる限りのリクエストを捌きたい...
- 過剰なトラフィックをドロップする負荷制限が必要
- このケースではロードバランシングと負荷制限の両方が必要
- 例: データ処理パイプラインが1つのクラウドリージョンのKubernetesクラスタに存在している場合
- データ処理が遅くなった場合、Kubernetesが処理のためのポッドを増やす
- しかしデータ入力がとても早くなると、メモリ不足やGCが遅くなったりする
- ポッドは負荷を一時的、または恒久的に制限する必要があるかもしれない
- このケースでは負荷ベースでのオートスケーリングと負荷制限の両方が必要
- 例: 負荷に応じてスケールする複数のインスタンスグループを運用している
- ロードバランシング、負荷制限、オートスケーリング
- 全てシステム負荷の平準化と安定化を目的として設計されている
- 別々に実装、インストール、設定されることが多く独立しているように見えるが、完全に独立しているわけではない
- (図11-8参照)
- 次のケーススタディではこれらのシステムの相互作用の例を示す

- 架空の会社: ドレッシー
- アプリを使ってオンラインでドレスを販売する会社
- トラフィックドリブンなので、開発チームは3つのリージョンにアプリをデプロイしている
- ユーザーのリクエストをすぐに応答することができ、単一ゾーンの障害にも対応できる
- カスタマーサービスチームは、アプリにアクセスできないという苦情を受け始めた
- 開発チームは問題を調査した
- ロードバランシングは不可解なことに、全トラフィックをリージョンAへ送っていた
- リージョンAはオーバーフロー
- リージョンBとCは余裕がある状態(同一の大きさ)
- イベントのタイムラインは以下の通り
- (図11-9を参照)
- 開発チームは問題を調査した
- 始まりの日、トラフィックのグラフは3つのクラスタが90 RPSで安定していた
- 午前10:46, 熱心な買い物客がバーゲンを狙ってきたためトラフィックが増加しはじめた
- 午前11:00, リージョンAは、BやCよりも先に120 RPSに達した
- 午前11:10, リージョンAは400 RPSに達したが、BとCは40 RPSまで低下した
- ロードバランサはこの状態で落ち着いた
- リージョンAに向かったリクエストの多くは503エラーを返却した
- このクラスタにリクエストが届いたユーザーは苦情を言い始めた

- ロードバランサは使用率に対応していた
- コンテナからCPU使用率を取得し、限界を推定していた
- リージョンAは、BやCと比べて、リクエストごとのCPU使用率が10倍低かった
- ロードバランサは、全リージョンが均一にロードバランシングされていると判断していた
- 週の初めに負荷制限を有効にした
- 連鎖的な負荷から守るため
- CPU利用率がしきい値に達すると、サーバーはリクエストに対してエラーを返却するもの
- リージョンAは少しだけ先にこのしきい値に達した
- 各サーバーはリクエストの10%、 次に20%、 そして50%を拒否し始めた
- CPU利用率は一定に保たれた
- ロードバランサーから見ると、リージョンAの効率がよく見えた
- リージョンAは先にしきい値に達し、リクエストをドロップしていたため他のリージョンよりCPU効率が良くなっていたため
- CPU使用率80%で240RPSを捌いているように見えていたが、BとCは120RPSしか捌いていないように見えた
- 論理的に考えて、リージョンAに多くのリクエストを送信していた
- 負荷制限システムと負荷分散システムが互いに連携していなかった
- そのため、ロードバランサはエラーが「効率的」なリクエストと知らなかった
- (異なるエンジニアによって)別々に追加された
- 1つの統合負荷管理システムとして検討した人はいなかった
-
効果的なシステム負荷の管理方法
- 個々の負荷管理ツールとその連携設定の両方をよく検討する必要がある
- ドレッシーの例では、ロードバランサの設定にエラー処理を含めていれば良かったはず
- 「エラー」リクエストをCPU使用率120%として計算する
- (100以上の数値であればOK)
- リージョンAは過負荷に見えるため、リクエストはBとCに振り分けられ、均等になる
- 新しい負荷管理ツールを採用する場合は、既存ツールとどのように連携しているか・交わる部分があるかを慎重に調べる
- フィードバックループを検出する監視を追加する
- 緊急停止トリガーが負荷管理システムで調整できることを確認する
- 自動停止トリガーの追加も検討する
- 予め適切な策を講じていないと、ポストモーテム直後にそうしないといけなくなる
- 「予防措置を講じる」と言うのは簡単
- 具体的には、負荷管理の種類に応じて以下のような予防措置を検討する
-
ロードバランシング(負荷分散)
- ロードバランシングはユーザーを地理的に近い場所へルーティングすることでレイテンシを最小限に抑える
- オートスケールはロードバランシングと連携して、ユーザーに近い場所のサイズを増やし、そこへのトラフィックをルーティングする
- 良いフィードバックループ
- もし多くのトラフィックがある1つのロケーションにあると、そのロケーションの規模は拡大する
- もしそのロケーションが停止すると、他のロケーションは過負荷になりトラフィックがさばけなくなる可能性がある
- スケールはすぐには行うことできない
- 最小インスタンス数を設定することで、フェイルオーバー時の予備のキャパシティを確保しておくことができ、この状況を回避できる
-
負荷制限
- 負荷制限が始まる前にオートスケールするようにしきい値を設定しておくのが良い
- そうしないと、スケールすれば処理できる場合でもトラフィックを制限し始める可能性がある
-
RPCによる負荷管理
- 効率のために正しいリクエストを処理する
- ユーザーのためにならないリクエストを処理するためにオートスケールしたくない
- 重要ではないリクエストを処理しているために負荷制限したくない
- オートスケールと負荷制限の両方を使用する際は、RPCリクエストにタイムアウトを設定するのが重要
- (訳注: RPCの説明でdeadlineとなっているものは、分かりやすさを考慮しタイムアウトと記載)
- プロセスは実行中の全てのリクエストのためにリソースを保持し、リクエスト完了時にリソースを開放する
- タイムアウトが無いと、実行中の全てのリクエストのためのリソースを限界まで保持してしまう
- デフォルトではこのタイムアウトがとても長い時間になっている(言語依存)
- この動作によってクライアントや最終的にはユーザーのレイテンシが長くなってしまう
- このサービスはリソース(メモリ等)を使い果たしてクラッシュする危険性もある
- このシナリオをきちんと処理するには↓を推奨
- サーバーは長時間経過したリクエストを終了させる
- クライアントは既に不要になったリクエストをキャンセルする
- 例: もしクライアントが既にユーザーへエラーを返却しているなら、サーバーは負荷の高い検索処理を始めるべきではない
- サービスが期待する動作を設定するためには、API側の .proto ファイルにデフォルトの推奨タイムアウト値をコメントに入れる
- クライアントには慎重にタイムアウトを設定する
- 効率のために正しいリクエストを処理する
- Googleの経験では完璧なトラフィック管理設定はない
- オートスケールは強力だが間違えやすい
- きちんと設定しないと悲惨な結果になることもある
- 例: 負荷分散、負荷制限、オートスケールのツールが独立して管理設定されている場合の壊滅的なフィードバックサイクル
- ポケモンGoの事例のように、トラフィック管理はシステム間連携の全体的視点に基づいたものが最も良い
- これまで何度も見てきたように連携に失敗している場合は、負荷制限、オートスケール、スロットリングがサービスを救うことはない
- 例: ポケモンGoの同期していないクライアントの再試行、応答しないバックエンドを待つロードバランサー
- うまくサービスを停止させるには、潜在的な問題を緩和するため計画が必要
- フラグ設定、デフォルト動作の変更、冗長なログ記録、トラフィック管理システムが利用するための設定パラメータの現在の値の公開 etc.
- この章での戦略とインサイトが、トラフィック管理を助け、ユーザーを幸せにし続けるのに役立つことを願っています