How does the human brain work? How do thoughts pop up in our conscience? Just thinking about the question is confusion enough. Maybe our brain works as a semantic network as explained by Carole Yue at Kahn Academy.
Try for yourself: think of a bird? You probably think a sparrow, duck. Think of an extinct animal? Now you might think of the dodo, mammoth or dinosaur. Animal living on the south pole: a penguin? Or polar bear?
Facts, ideas, memories in our brain are interconnected. They’re not structured into tables like in relational databases or hierarchical in directories on a harddrive: if I’d ask you to name all the birds you know, you won’t give me a long list immediately. A better model of human memories would a graph, a network of interconnected nodes. Some nodes are more strongly connected than others, so you can associated one fact with another faster. You know a dodo and a penguin is a bird, but it’s not the first animal you think of. You might also have some doubt wetter the polar bear really lives on the south pole. Might this be the north pole? The graph of this facts we’ve remember could look like this:
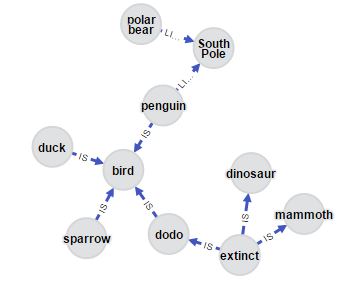
The idea of using a graphs to for information retrieval (IR) is as old as modern computers. Inspired by this model of the human memory is spreading activation, an algorithm: spreading activation
The spreading activation model was first introduced in the early 80’s to allow for intelligent information retrieval (IIR).
What’s exciting now is computers becoming fast, memory is extremely cheap. Also the idea that computers can do much more than just storing information is getting recognized again, with machine-learning, algorithms and smart software in general becoming popular.
Using a database server that’s specifically designed to handle graphs: neo4j I’ll try to model the the previous mentioned facts and how we recollect them in our mind.
This document is a graphgist so you can see the results on the fly
First we’ll set up the 'facts' as mentioned above in neo4j using its query language cypher. Each fact is linked to another with a certain weight with a range from 0 to 1, the higher the weight, the stronger the facts are interconnected.
-
Similarity, by calculating distance, like text-distance between words.
-
Co-occurrence frequency, how much a certain facts occur frequently togetter.
-
Other data such as sales-numbers or feedback that can be converted into a number between 0 and 1
In this case the weight is rather subjective, how fast we could thing of the fact as described in the first paragraph.
create (bird {name:"bird"})<-[_0:IS {weight: 1}]-(duck {name:"duck"}),
(bird)<-[_1:IS {weight: 0.9}]-(sparrow {name:"sparrow"}),
(extinct {name:"extinct"})-[_3:IS {weight: 0.8}]->(mamoth {name:"mammoth"}),
(extinct)-[_4:IS {weight: 0.7}]->(dodo {name:"dodo"}),
(extinct)-[_5:IS {weight: 0.8}]->(dinosaur {name:"dinosaur"}),
(dodo)-[_6:IS {weight: 0.7}]->(bird),
(southpole {name:"South Pole"})<-[_7:LIVES {weight: 1}]-(penguin {name:"penguin"}),
(southpole)<-[_8:LIVES {weight: 0.5}]-(polarbear {name:"polar bear"}),
(penguin)-[_9:IS {weight: 0.6}]->(bird)
RETURN *The spread activation algorithm is described by wikipedia. We’ve already set up a graph above, with weights for each edge.
Now we want to ask our 'brain' to name an extinct bird. What will come up?
-
Firing threshold I’ll set to an arbitrary value of 0.8
-
Decay factor I’ll set to an arbitrary value of 0.6
And we’ll run the actual algorithm. First the activation value of all nodes should be cleared, and one node has to be activated. That’s the bird and extinct in this case.
MATCH (n) SET n.activation = null, n.fired=falseMATCH (n) WHERE n.name="bird" OR n.name="extinct" SET n.activation = 1After activation, the nodes are fired and new nodes are activated.
MATCH (i)-[r]-(j) WHERE not i.fired AND i.activation IS NOT NULL AND i.activation>=0.8 AND NOT j.fired SET i.fired=true SET j.activation = COALESCE(j.activation, 0) + i.activation * COALESCE(r.weight,0) * 0.6 RETURN count(i) as firedA few nodes are fired.
The activation should be between 0 and 1 as described by the alghorithm, so we’ll truncate the activation values.
MATCH (j) WHERE j.activation<=0 SET j.activation=nullMATCH (j) WHERE j.activation>1 SET j.activation = 1and we fire again
MATCH (i)-[r]-(j) WHERE not i.fired AND i.activation IS NOT NULL AND i.activation>=0.8 AND NOT j.fired SET i.fired=true SET j.activation = COALESCE(j.activation, 0) + i.activation * COALESCE(r.weight,0) * 0.6 RETURN count(i) as firedNow, no new nodes are fired again. Let’s query the network to see the resuls. The activation value is used as an ordering, e.g. ranking.
MATCH (n) WHERE n.activation IS NOT NULL RETURN n.name as name, n.activation as activation ORDER by n.activation DESC LIMIT 5This looks quite ok: when querying, e.g. asking, our network for an extinct bird, we got back the original answers, followed by dodo has highest ranking answer
This result is of course not very suprisingly, but imagine a network of hundreds of thousands or billions of nodes. This may seem like a lot, but a modern laptop can easily run a neo4j database containing hundres of thoundes of interconnected nodes. Connect a few computers togetter together and you can do quite amazing things:
-
Using the data of all product reviews and sales, so you can give customers good recommendations.
-
In hundred of thousand of resumes and feedback-forms find out a good candidate for a job
-
Tens of thousands of legal documents in your archive you want to structure so you can find the documents for a new legal case.
You don’t have to be Google or Facebook to apply machine learning Want to know more? Contact Gerbrand or Onne.