-
-
Save hamletbatista/1f9a86d4364f641f776808bff03f557b to your computer and use it in GitHub Desktop.
| yaml_config=""" | |
| input_features: | |
| - | |
| name: Original_Title | |
| type: text | |
| level: word | |
| encoder: t5 | |
| reduce_output: null | |
| - | |
| name: Keyword | |
| type: text | |
| level: word | |
| tied_weights: Original_Title | |
| encoder: t5 | |
| reduce_output: null | |
| output_features: | |
| - | |
| name: Optimized_Title | |
| type: sequence | |
| level: word | |
| decoder: generator | |
| """ | |
| with open("config.yaml", "w") as f: | |
| f.write(yaml_config) |
Click on the "Raw" button to get a link you can use to download to your notebook with wget
Thanks for such a quick reply!
Thanks for such a quick reply!
Did it work?
Model is training! As soon as I complete the tutorial, I'll put together my data sets to run on my own sites!
Perfect!
Nice to meet you! I'm Mithila.
I have been trying to run code from this article:
https://www.searchenginejournal.com/automated-title-tag-optimization-using-deep-learning/390207/
However, I'm stuck in the training model step.
From your above comment it seems that your model was training well.
Do you mind if you share the copy of your code to me please?
Sorry to trouble you. but I have been trying really hard to run my code (As I'm not from the core dev background, I'm finding ita bit difficult)
Thanks in advance,
Mithila
hi @mithila2806 check this colab notebook. this contains my successfully running code following article. Let me know if this helps.
hi @mithila2806 check this colab notebook. this contains my successfully running code following article. Let me know if this helps.
Thanks a lot @shyamcody 🍻
Hey @shyamcody
That's fab! Thank you very much.
One (stupid) question though -
Could you please provide the file to be uploaded here?

FYI:
-
I updated code to include the new/updated YAML file found here: https://gist.githubusercontent.com/hamletbatista/e0498d79dfef5350cec8171d8e4a1f03/raw/e012a235522773fca9d3543907193172232bb44f/ludwig_t5_config.yaml

-
Skipped execution of this step:
-
and then run this step:

But running into same error:
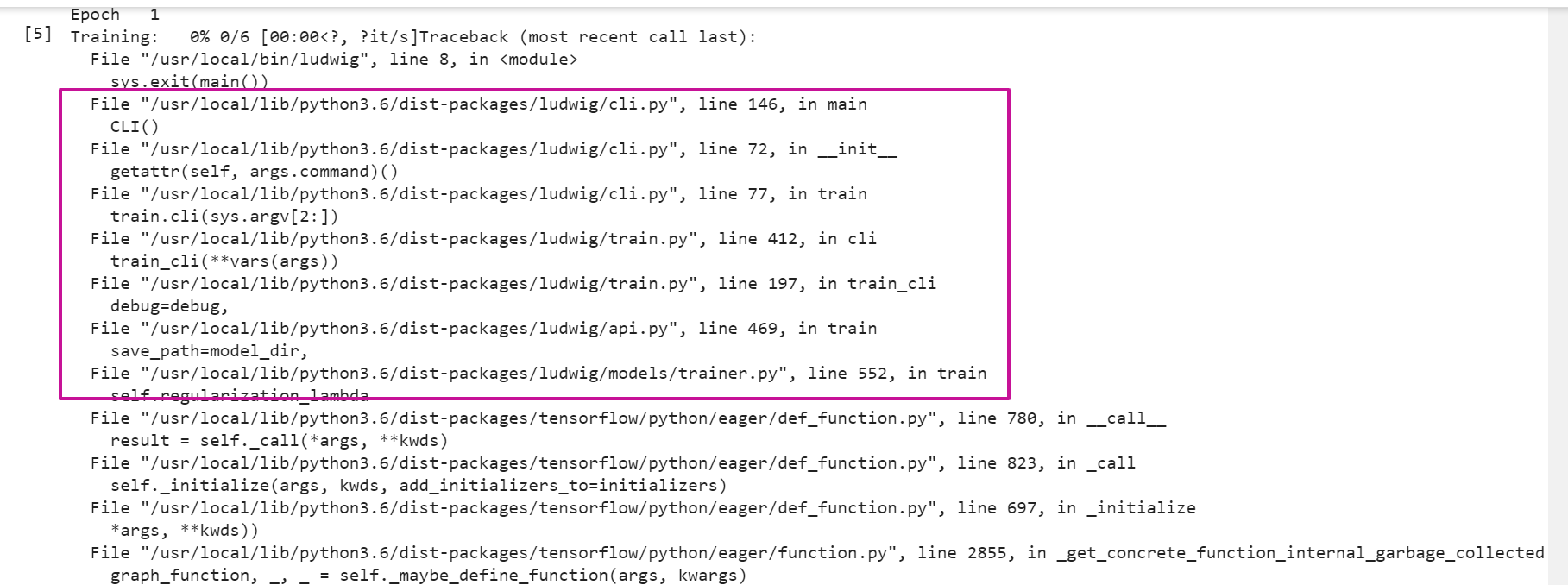

I think I am making some mistake related to YAML.
Any help will be very helpful.
Thanks in advance,
Mithila
Thanks in advance,
Mithila
Thank you @hamletbatista 👍 You're a star
Nice to meet you! I'm Mithila.
I have been trying to run code from this article:
https://www.searchenginejournal.com/automated-title-tag-optimization-using-deep-learning/390207/However, I'm stuck in the training model step.
From your above comment it seems that your model was training well.Do you mind if you share the copy of your code to me please?
Sorry to trouble you. but I have been trying really hard to run my code (As I'm not from the core dev background, I'm finding ita bit difficult)
Thanks in advance,
Mithila
Sorry Mithila, I'm just seen this now. I tried to run the code again but I was unsuccessful.
I don't have the coding background as well, but I'm willing to learn this. It would be very handy in my projects.
Hi Marcus
I have got this from another Git User
https://colab.research.google.com/drive/1l5tTgShVuEVfnVxIjyiOpb5Zbjxnhs9a?usp=sharing
I tried myself but I'm stuck on the same step unfortunately.
See if this works for you.
Let me know if this works for you 🙂
Regards,
Mithila
Hey Marcus
I did exactly that:) Saved a copy, and then ran the cells.
Resolved some errors which I was getting (mostly they were TensorFlow/Ludwig compatibility issues related).
Yes. I did notice that too - the two files are different.
That's the reason why I changed it in my code and used Hamlet's updated YAML file:
https://gist.githubusercontent.com/hamletbatista/e0498d79dfef5350cec8171d8e4a1f03/raw/e012a235522773fca9d3543907193172232bb44f/ludwig_t5_config.yaml
(I have pasted the screenshots above)
My assumption is @shyamcody added these lines of code
from google.colab import files files.upload()
and uploaded the correct YAML file from his local folder/drive.
Regards,
Mithila K
Hi @mithila2806 I am also stuck at the same part as you with the error "ValueError: The following keyword arguments are not supported by this model: ['token_type_ids'].". Do you happen to have any update on the issue?
hey!
I didn't progress after that. Wil update here if at all I get lucky.
Thanks for your update 😊
Regards,
Mithila K
Hi again @mithila2806, the way I managed to avoid this error was by finding the python file were this error occured and comment out some lines. If I remember correctly the lines were 348,349,350,351. After doing that I run the model again end it worked. If you want me to explain anything else just hit me up!
I was able to successfully run the code. I didn't do any changes. I simply ran the code and it worked:)
I believe there were some compatibility issues, which were fixed.
Happy coding 👍
Regards,
Mithila K
Great job @mithila2806 @nearchoskatsanikakis 👏🏽👏🏽👏🏽
I'm glad you got it to work!
Hi Hamlet
It wouldn't have been possible without you.
Can't thank you enough.
Regards,
Mithila
Hi Hamlet,
I'm getting issues when get to:
Import panda as pd
And
df = pd.read.csv("dAta.csv")
df.head ()
In the "data.csv" is that where I'm going to import my data I want to optimize?
And 2) How do I upload my data into it?
And after it has optimize the tag how do I download it into a spreadsheet for analysis?
@tthebimbolawal
When you dowload the file using the !wget instructions provided by Hamlet, the resulting csv will be named hootsuite_titles.csv, and it will be in the content folder, if you are using google-colab. See screenshot.
So, to load it in pandas you can do pd.read_csv('hootsuite_titles.csv')
I hope that answers your question.

Hello all,
Thank you all for the information.
I have followed all steps and tried to make it work.
When I run the following code,
!ludwig predict --dataset hootsuite_titles_to_optimize.csv --model_path results/experiment_run/model/
It returns this error
FileNotFoundError: [Errno 2] No such file or directory: 'results/experiment_run/model/model_hyperparameters.json'
Could you all tell me what model path I should use to make it work?
Thank you a lot
Hii while I am trying to replace hootsuite_titles.csv dataset with my website dataset I am getting a value error like this:
ValueError: A Concatenate layer requires inputs with matching shapes except for the concat axis. Got inputs shapes: [(128, 32, 512), (128, 224, 512)]
please reply.......
Thanks @marcusbianco can you please explain me how to prepare a dataset properly for training and the optimized score column in hootsuit dataset what is that ? Is that necessary for training?
@marcusbianco While I am using this data set https://docs.google.com/spreadsheets/d/e/2PACX-1vQeg6komuBq6U4Rn_SWFNXgGxXIL4fhQcdJp2A8p0B2pmiucvDG5SUpXEGKooJPaTPsN0ivIaCvqIad/pub?gid=0&single=true&output=csv
its running fine but just check this dataset also https://docs.google.com/spreadsheets/d/e/2PACX-1vSbe_3C_JV06TQvL-TR741o7goEycu0oGwO3kfJleawuDQEQiu2ZC2lpgeHhRQayJ4JoZe6PvbdCvbF/pub?gid=0&single=true&output=csv , while I am trying to run this one its throwing that value error... please guide me.. Kindly check and tell me the differences..
Thanks for the feedback. I renamed the file with a .py extension, which is more accurate.
Here is a separate GIST with just the yaml https://gist.github.com/hamletbatista/e0498d79dfef5350cec8171d8e4a1f03