English version is here
鈴木 弘一 (Hirokazu SUZUKI, @heronshoes) 2023年3月20日
列指向オンメモリーのデータ処理フレームワークApache ArrowのRuby実装であるRed ArrowをベースとしたデータフレームライブラリRedAmberの開発に2022年4月から取り組んでいる。 本稿ではRubyアソシエーション開発助成に対する、 2022年10月から2023年3月までの開発の成果について報告する。
この期間では下記のリリースを行なった。変更履歴とリリースノートは下記の通り。
活動内容を下記の項目に分けて報告する。
- 新機能の実装
- Red Arrowプロジェクトへのフィードバック
- パフォーマンスの向上
- コード品質の向上
- ドキュメント整備
- 普及活動
DataFrameCombinableモジュールにて、 データフレームと他のデータフレームとの結合操作を実装した。
- v0.2.3 で大部分を実装
- v0.3.0 でハッシュによるキーの指定を追加
- v0.4.0, v0.4.1 でオプション
:force_orderによる結合後のソートを可能にした

Red ArrowのTable#joinを用い、:typeオプションをプリセットした#left_join等のメソッドを実装する形で、Rに似たスタイルの結合機能を構築した。
Red Arrowでは左右のカラムを残す仕様であるので、:left_outputs と :right_outputs オプションを活用して、
他のデータフレームと同様に必要なカラムだけを残し、必要ならばマージして一つのカラムを残すようにした。
Red Arrowでは重複したカラム名が許容されるが、データフレームやRDBのテーブルでは一般的にカラム名(キー)の重複は不可である。
RedAmberでも重複したキーはサフィックスをつけてリネームする機能を実装した。
サフィックスのデフォルトは suffix: '.1' とし、otherのデータフレームのカラム名だけをリネームし、それでも重複する場合は succする仕様とした。
これはselfとother両方のリネームは過剰であることと、Rubyではselfに対するメソッド呼び出しであるため
selfの内容は優先的に保持されるべきと言う考えに基づく。
join_keyを省略した場合、自動的に共通するカラム名を使ってjoinする機能(Natural join)を実装した。
これは Red ArrowのTableにも提案しマージされた(GH-15088)。
データフレームの集合的な結合と縦・横の結合も同様にRed Arrowの Table#joinを使って構築した。
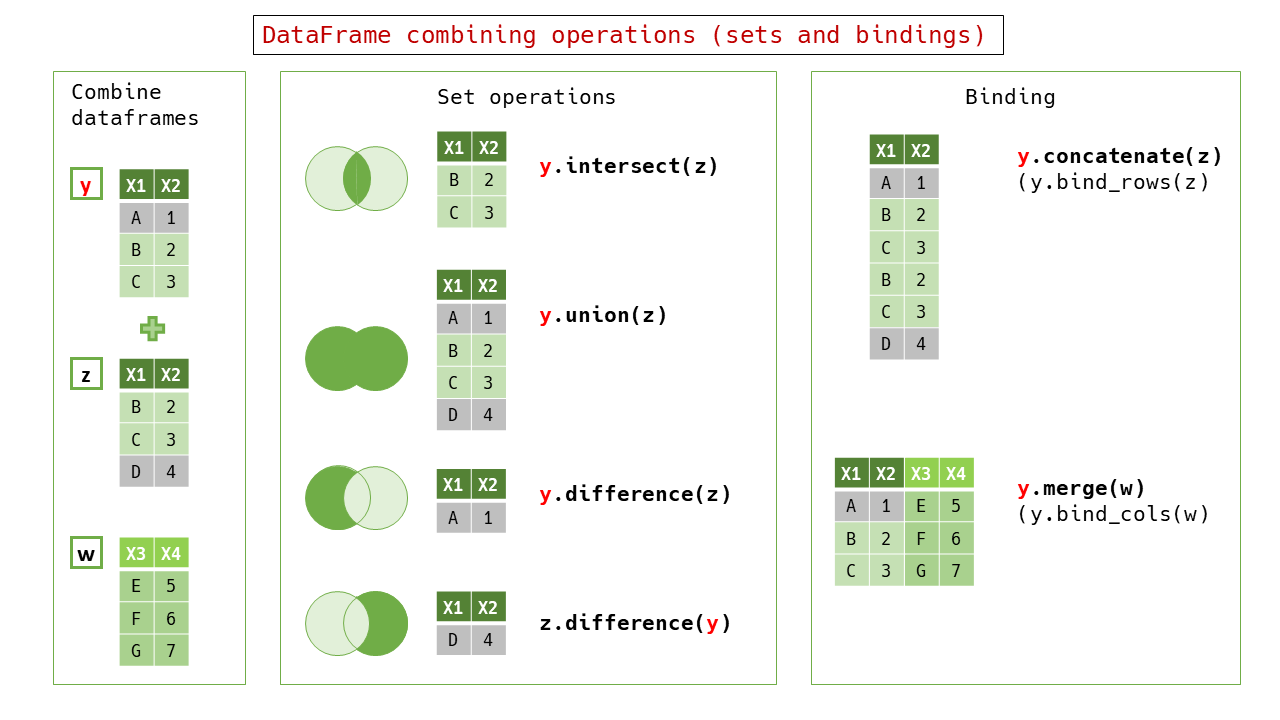
概ねRの語彙に近いが、差演算は#setdiffの代わりにRubyのArrayの差と同じ#differenceを主たるメソッド名として採用した。
列方向に長くする連結に#concatenate、行方向に長くする連結に#mergeを割り当てた。
Arrowの実装では結合後のレコード(行)の順番は不定である。これはレコード数が大きくなると顕著に現れる(実行毎に結果が異なる)。 この仕様は実行速度の点で有利であるが、一方で従来のデータフレームライブラリやデータベースシステムでは左のテーブルを優先して 行の順番を保持する仕様となっているようであり、順番が不定であることは直感と異なる場合がある。また、テストを書く場合には順番が不定であると 不便である。
Arrowフォーマットを扱える別の実装(Arrow2)をベースとしたRustのデータフレームライブラリPolarsでは結合前の順番を保持するオプションがある。 RedAmberでもv0.4.0でこの機能を採用した。事前に左右のデータフレームにインデックス列を付与しておき、結合後にソートし、インデックス列を 取り除くため速度上不利であるが、分かりやすい結果をもたらすのでRedAmberではソートする動作をデフォルトとした。v0.4.1で#joinをベースとする 全てのMutating joinとFiltering joinのJoin系メソッドについてソートを可能にした。
ベクトルの要素を空白文字または任意の文字で分割し、複数のベクトルに分ける、または長さ方向に並べたベクトルを生成する機能(split_*)を実装した。 またベクトルの要素またはスカラーを連結した文字列を要素とするベクトルを生成するメソッド(merge)を実装した(v0.3.0で実装)。
- ベクトルの要素を空白文字または任意の文字で分割し、複数のベクトルに分ける。
vector = RedAmber::Vector.new(['a b', 'c d', 'e f'])
vector
#=>
#<RedAmber::Vector(:string, size=3):0x0000000000050014>
["a b", "c d", "e f"]
vector.split_to_columns
#=>
[#<RedAmber::Vector(:string, size=3):0x0000000000058cc8>
["a", "c", "e"]
,
#<RedAmber::Vector(:string, size=3):0x0000000000058cdc>
["b", "d", "f"]
]このメソッドはデータフレームの列を特定の文字で分割する用途で使える。
RedAmber::DataFrame.new(year_month: %w[2023-01 2023-02 2023-03])
.assign(:year, :month) { year_month.split_to_columns('-') }
#=>
#<RedAmber::DataFrame : 3 x 3 Vectors, 0x0000000000078ed8>
year_month year month
<string> <string> <string>
0 2023-01 2023 01
1 2023-02 2023 02
2 2023-03 2023 03このメソッドはsepを省略した場合、Arrowの ascii_split_whitespace()を使いArrow::StringArrayの要素を空白文字で高速に分割する。
一方sepを指定した場合は RubyのString#sepを使うので、正規表現を指定して柔軟な分割を行うことができる。
RedAmber::DataFrame.new(yearmonth: %w[202301 202302 202303])
.assign(:year, :month) { yearmonth.split_to_columns(/(?=..$)/) }
#=>
#<RedAmber::DataFrame : 3 x 3 Vectors, 0x0000000000078eec>
yearmonth year month
<string> <string> <string>
0 202301 2023 01
1 202302 2023 02
2 202303 2023 03- ベクトルの要素を空白文字または任意の文字で分割し、長さ方向に並べたベクトルを生成する。
vector
#=>
#<RedAmber::Vector(:string, size=3):0x0000000000050014>
["a b", "c d", "e f"]
vector.split_to_rows
#=>
#<RedAmber::Vector(:string, size=6):0x00000000000809d0>
["a", "b", "c", "d", "e", "f"]- 文字列またはベクトルを要素毎にselfに連結した文字列を要素とするベクトルを生成する。
vector = RedAmber::Vector.new(%w[a c e])
other = RedAmber::Vector.new(%w[b d f])
vector.merge(other)
#=>
#<RedAmber::Vector(:string, size=3):0x00000000000a530c>
["a b", "c d", "e f"]
vector.merge('x', sep: '')
#=>
#<RedAmber::Vector(:string, size=3):0x00000000000b1008>
["ax", "cx", "ex"]従来のデータフレームには無い新しい概念として、SubFramesクラスを設計し、実験的機能として実装した。

SubFramesは、データフレームの部分集合を保持し、要素をデータフレームとして返すイテレータを持つオブジェクトである。 SubFramesは、既存のデータフレーム/データベースのグループ(Group_byなど)の機能と、ローリングウィンドウ機能(移動平均など)と、 要素毎に処理するウィンドウの機能を統一的に扱うと共に、Rubyらしいイテレータの活用によって通常のDataFrameに対する操作が そのまま適用できる記法が特徴である。
上の図は、データフレームのいわゆるグループ化による処理をSubFramesで書いた例である。 左半分は、ベースとなるデータフレームから列yの値によってグループ化する操作で本質的に既存のGroup_byと変わらないが、生成されるのは 分割されたデータフレームを順に返すSubFramesオブジェクトである。右半分は一つのデータフレームを一つの行に集約する操作で、 一つのデータフレーム要素に対する操作がそのまま全体の集約操作として書けることが特徴である。
従来のグループ化の操作は元になるデータフレームの状態から「グループ化された状態」を経て集約されるという考え方であり、 RedAmberのGroupクラスや元になったRed ArrowのテーブルのGroupでも同様である。

上の図は、RedAmberのGroupクラスによる集約の例である。Groupクラスはカラムの値によって分割されたデータフレームのような状態を保持しているが、 グループ特有の振る舞いをする。
従来型のGroupクラスとSubFramesを比較すると下記のようになる。
- Group
- グループ分割の元になったキー列の情報を利用できる
- グループ化と集約は一体化されて効率的に実行するエンジンがある(Acero)
- SubFrames
- より一般化された概念であり、分割の方法は値によるグループに限らず、応用範囲が広い。
- SubFramesからSubFramesを生成する処理が可能である反面、グループにおける分割元のキー列の情報を保持できない。
- 出力時には分割元のキーも明示的に書く必要があるが、欲しい結果をそのまま書く記法はDataFrameのRenameやAssignと共通している。
Rのtidyrでは下記のように「nest」という概念を導入している。

Nested dataframeは集約後のデータフレームの形の中にネストした行として元のデータフレームを取り込むという考え方である。
ArrowのCompute Functionでは通常のテーブル用の集約関数(例えばsum)とグループ用の集約関数は別である(例えばhash_sum)。 しかしRedAmberでは DataFrame内のVectorに対する 集約メソッドはそのままSubFramesでも使える。 また、新規にVectorの集約関数を書けばそれがそのままSubFramesに対しても適用可能となるため、 容易に独自の集約処理を作成することができるようになる。
元のデータフレームの行を順に取得して操作を行うローリングウィンドウに対しても、同じ考え方で操作ができる。

上の例ではサイズ3のウィンドウを元のDataFrameに適用して4つのDataFrameからなるSubFramesを得て、
次に#aggregateで一つのDataFrameを一つの行に集約している。
x.meanは結果として移動平均を求める操作になる。移動平均を求める過程で、ウィンドウでデータを分ける操作と平均の計算が別になっていることが特徴で、
そのため平均を求める関数は特別なものである必要がない。前述のGroupingと異なりSubFramesの中身は互いに重複があるものとなる。
SubFramesから新しいSubFramesを生成する操作の例が下記である。

この例では、既に紹介した値によるGroupingで生成したSubFramesに対し、グループ毎の1から始まる連番およびグループ毎の累積和を生成している。 適用しているのはVectorの集約関数メソッドではなく、要素毎の値を返す関数メソッド(#indecesまたは#cumsum)なので、得られた結果はSubFramesとなる。
上の図の左下は DataFrame#assign によってデータフレームの全体に対して同じ操作をしている例であるが、
右のSubFrames#assignと比べると メソッドだけでなくブロックの中身も全く同じ形 で操作ができている。この一貫性がSubFramesの最大の特長である。
SubFramesはRubyのEnumeratorから生成することもできる(左)。また、マスク付きのウィンドウ(カーネルと呼ぶ)から生成することもできる(右)。 カーネルは、例えば毎日のデータから「前の週の同じ曜日」同士のデータのペアを得るようなケースで使うことができる。

SubFramesは0から始まるインデックスの配列を元に生成することもできる。

上の例は偶数行と奇数行を分ける例、下の例は隣り合った2行をランダムに取り出す例である。このようにSubFramesでは非常に多くのユースケースに対して適用が 可能である。
参考)上の例は、Array#partition を使って以下のようにも書ける。
df.build_subframes do
(0...size).partition(&:odd?)
end&:odd?を&:even?に変えるとSubFrames内の順番が逆になる。
現在のSubFramesの実装はPure Rubyで実現しており、一部lazyな処理にしているものの内部で実際にサブデータフレームを生成させている。 このため同じ処理に対してC++のAceroを呼んでいるGroupクラスと比べると70倍以上遅い。 今後、上流側と連携してSubFramesの高速化を図っていきたい。その際には、ユーザーには内部にデータフレームがあるように見せながら実際は Record Batchで表現する、またはインデックス配列の集合で表現するなどの工夫が必要と考えている。
剰余は比較的よく使う機能であるが、Arrow C++ の Compute function divmod()は長らくdraftの状態で実装が進んでおらず、
RedAmberに導入できていなかった(Pure Rubyでmapするしかなかった)。
そこで既存の#divide, #floor, #trunc, #multiply, #subtractを組み合わせて #moduloと#remainderを作った。
integer = RedAmber::Vector.new(1, 2, 3)
divisor = RedAmber::Vector.new(2, 2, 2)
integer.modulo(divisor)
=>
#<RedAmber::Vector(:uint8, size=3):0x00000000002c46d8>
[1, 0, 1]剰余には負の数の取り扱いで言語処理系ごとに違いがあるが、RedAmberの挙動はRubyのそれと同じ、 すなわち#moduloと#%は符号が除数と同じ、#remainderは符号が被除数と同じとした。これはNumo/NArrayの #%(被除数と同じ)とは異なる動作となった。
集約関数を要素毎の関数として使うためのメソッド#propagateを導入した。
これはSubFramesと組み合わせて使うと便利である。
import_cars
=>
#<RedAmber::DataFrame : 5 x 6 Vectors, 0x0000000000390af8>
Year Audi BMW BMW_MINI Mercedes-Benz VW
<int64> <int64> <int64> <int64> <int64> <int64>
0 2017 28336 52527 25427 68221 49040
1 2018 26473 50982 25984 67554 51961
2 2019 24222 46814 23813 66553 46794
3 2020 22304 35712 20196 57041 36576
4 2021 22535 35905 18211 51722 35215
import_cars
.to_long(:Year, name: :Manufacturer, value: :n_of_imported)
.sub_by_value(keys: :Year)
.assign do
{ sum_by_year: n_of_imported.propagate(:sum) }
end
=>
#<RedAmber::SubFrames : 0x000000000067ddd8>
@baseframe=#<Enumerator::Lazy:size=5>
5 SubFrames: [5, 5, 5, 5, 5] in sizes.
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067ddec>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2017 Audi 28336 223551
1 2017 BMW 52527 223551
2 2017 BMW_MINI 25427 223551
3 2017 Mercedes-Benz 68221 223551
4 2017 VW 49040 223551
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067de00>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2018 Audi 26473 222954
1 2018 BMW 50982 222954
2 2018 BMW_MINI 25984 222954
3 2018 Mercedes-Benz 67554 222954
4 2018 VW 51961 222954
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067de14>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2019 Audi 24222 208196
1 2019 BMW 46814 208196
2 2019 BMW_MINI 23813 208196
3 2019 Mercedes-Benz 66553 208196
4 2019 VW 46794 208196
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067de28>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2020 Audi 22304 171829
1 2020 BMW 35712 171829
2 2020 BMW_MINI 20196 171829
3 2020 Mercedes-Benz 57041 171829
4 2020 VW 36576 171829
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067de3c>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2021 Audi 22535 163588
1 2021 BMW 35905 163588
2 2021 BMW_MINI 18211 163588
3 2021 Mercedes-Benz 51722 163588
4 2021 VW 35215 163588Vectorの要素をランダムにサンプリングして新しいVectorを返すメソッドとして
Vector#sampleを導入した。
#sampleはサンプリングサイズとしてInteger または Floatの引数を取る。
- Integer (n)の場合、サンプリング数を指定する。
- Float (prop)の場合、Vectorのサイズに対する比率でサンプリング数を指定する。
n <= self.sizeまたはprop <= 1.0の場合、繰り返しがないサンプリングを行う。
v = RedAmber::Vector.new('A'..'H')
v
=>
#<RedAmber::Vector(:string, size=8):0x0000000000011b20>
["A", "B", "C", "D", "E", "F", "G", "H"]n == sizeの時は、繰り返しなしで要素を8個ランダムに並べる。
v.sample(8)
=>
#<RedAmber::Vector(:string, size=8):0x000000000001bda0>
["H", "D", "B", "F", "E", "A", "G", "C"]n > sizeまたはprop > 1.0の場合、繰り返しがあるサンプリングを行う。
v.sample(2.0)
# =>
#<RedAmber::Vector(:string, size=16):0x00000000000233e8>
["H", "B", "C", "B", "C", "A", "F", "A", "E", "C", "H", "F", "F", "A", ... ]- 引数を省略した場合は、スカラーを返す。
v.sample # => "C"RedAmberを開発する中で遭遇したバグや機能改善の提案を随時Red Arrowにフィードバックしている。基本的な機能は積極的にRed Arrowに移していきたい。
- バグ報告
- CIのhomebrewのバグ報告と修正 (GH-15093):マージ済
- RedAmberで使用している機能の改善提案
- 機能/改善提案
- Table#saveでcsvをセーブする際にselfを返すことでREPL環境での待ち時間を減らす(GH-15289):マージ済
- [GLib] 'MatchSubstringOptions' のサポートを提案([GH-15285](https://github.com/apache/arrow/issues/15285):改善の提案
- [GLib] 'IndexOptions' のサポートを提案([GH-15286](https://github.com/apache/arrow/issues/15286):改善の提案
- [GLib] 'RankOptions' のサポートを提案([GH-34425](https://github.com/apache/arrow/pull/34458):@kouさんが実装され、12.0.0にマージされた.
- [C++] 'rank()' がChunkedArrayをサポートしていない(GH-34426):issue報告
- レビュー
RecordBatch{File,Stream}Reader#eachでブロックがない場合をサポート(GH-34440) イテレーションの回数がわかっている場合はEnumerator#sizeがnilでない値を返せるような追加機能を提案:マージされた.
※ この活動にあたっては、特に須藤(@kou)さんの手厚いサポートを頂いています。感謝申し上げます。
第一段階として、主要メソッドのバージョン間のパフォーマンス比較を行えるように、ベンチマークを作成した(v0.2.3)。 ベンチマークは benchmark_driver を使い、データは主としてRDatasetのうち比較的データサイズが大きい nycflights13 データセットを使用した。
第二段階として、コードの全面的な見直しを行い、速い処理への置き換え、処理の順番の変更、不要な処理の削除等のリファクタリングを行い 処理速度を向上させた。下記にバージョン毎の比較結果を示す。v0.3.0がリファクタリング後のバージョン、 v0.2.3はほぼ機能が同じである直前のバージョン、v0.2.0は開発助成期間前の基準となるバージョンである。
計測は下記の環境で行なった。
- distro: Ubuntu 20.04.5 LTS on Windows 11 x86_64
- kernel: 5.15.79.1-microsoft-standard-WSL2
- cpu: Intel i7-8700K (12) @ 3.695GHz
- memory: 30085MiB
- Ruby: ruby 3.2.0 (2022-12-25 revision a528908271) +YJIT [x86_64-linux]
- Arrow: 10.0.0
3.1 Basicベンチマーク: データフレームの基本的な操作に対するテスト
Iteration per second (i/s): (大きいほど速い)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.0 | 0.1.5 |
|---|---|---|---|---|---|
| B01 | Pick([]) by a key name | 434,783 | 8,759 | 9,357 | 202,703 |
| B02a | Pick([]) by key names | 2,530 | 897 | 1,898 | 2,276 |
| B03 | Pick by key names | 2,783 | 653 | 4,374 | 2,311 |
| B04 | Drop by key names | 694 | 352 | 761 | 675 |
| B05 | Pick by booleans | 792 | 383 | 1,094 | 1,005 |
| B06 | Pick by a block | 920 | 386 | 1,346 | 1,091 |
| B07 | Slice([]) by an index | 597 | 445 | 798 | 1,934 |
| B08 | Slice by indeces | 51.4 | 47.1 | 51.7 | 56.2 |
| B09 | Slice([]) by booleans | 54.7 | 2.3 | 2.3 | 0.3 |
| B10 | Slice by booleans | 103.3 | 2.3 | 2.2 | 3.0 |
| B11 | Remove by booleans | 78.6 | 2.2 | 2.4 | 2.7 |
| B12 | Slice by a block | 100.9 | 2.4 | 2.3 | 3.0 |
| B13 | Rename by Hash | 804 | 508 | 853 | 737 |
| B14 | Assign an existing variable | 3.2 | 3.2 | 3.3 | 3.4 |
| B15 | Assign a new variable | 3.3 | 3.4 | 3.3 | 3.5 |
| B16 | Sort by a key | 18.5 | 19.3 | 20.0 | 18.4 |
| B17 | Sort by keys | 11.8 | 11.6 | 12.0 | 12.1 |
| B18 | Convert to a Hash | 2.8 | 2.3 | 2.4 | 2.3 |
| B19 | Output in TDR style | 1.3 | 1.3 | 1.3 | 1.3 |
| B20 | Inspect | 17.0 | 14.7 | 16.6 | 1.7 |



最新版の方が遅いケースがいくつかあるが、これは下記が原因であると考えている。
- 初期バージョンでは処理速度のバランスが取れていなかったから (インデックスは速いがブーリアンは極端に遅い、など)
- 機能が付け加わり分岐処理に時間がかかるようになったから
例:Pickはインデックス、列名、ブーリアンフィルタのどれでも受け付けるようにした
(インデックスと列名は混在も可で、
penguins.pick(0..2, -5, :year)などもできる)
3.2 Combineベンチマーク: データフレームの結合操作に対するテスト
Iteration per second (i/s): (大きいほど速い)
| # | Benchmark name | 0.3.0 | 0.2.3 |
|---|---|---|---|
| C01 | Inner join on flights_Q1 by carrier | 106.3 | 0.9 |
| C02 | Full join on flights_Q1 by planes | 0.9 | 0.6 |
| C03 | Left join on flights_Q1 by planes | 70.6 | 0.6 |
| C04 | Semi join on flights_Q1 by planes | 103.9 | 100.5 |
| C05 | Anti join on flights_Q1 by planes | 244.2 | 230.4 |
| C06 | Intersection of flights_1_2 and flights_1_3 | 46.8 | 0.2 |
| C07 | Union of flights_1_2 and flights_1_3 | 0.07 | 0.07 |
| C08 | Difference between flights_1_2 and flights_1_3 | 51.5 | 53.1 |
| C09 | Concatenate flight_Q1 on flight_Q2 | 7,393 | 2,903 |
| C10 | Merge flights_Q1_right on flights_Q1_left | 0.6 | 0.6 |

3.3 Groupベンチマーク: Group関連の操作に関するテスト
Iteration per second (i/s): (大きいほど速い)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.2 |
|---|---|---|---|---|
| G01 | sum distance by destination | 119.9 | 122.5 | 120.3 |
| G02 | sum arr_delay by month and day | 168.4 | 155.8 | 140.8 |
| G03 | sum arr_delay, mean distance by flight | 29.6 | 25.6 | 27.8 |
| G04 | mean air_time, distance by flight | 110.5 | 102.0 | 102.9 |
| G05 | sum dep_delay, arr_delay by carrer | 123.6 | 121.3 | 111.0 |

3.4 Reshapeベンチマーク: Reshape関連の操作に関するテスト
Iteration per second (i/s): (大きいほど速い)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.2 |
|---|---|---|---|---|
| R01 | Transpose a DataFrame | 3.8 | 3.4 | 3.7 |
| R02 | Reshape to longer DataFrame | 1.5 | 1.6 | 1.6 |
| R03 | Reshape to wider DataFrame | 0.7 | 0.6 | 0.7 |

3.5 Vectorベンチマーク: Vectorの操作に関するテスト
Iteration per second (i/s): (大きいほど速い)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.0 |
|---|---|---|---|---|
| V01 | Vector.new from integer Array | 7.2 | 6.0 | 6.4 |
| V02 | Vector.new from string Array | 1.6 | 1.7 | 1.7 |
| V03 | Vector.new from boolean Vector | 1,220,000 | 6.6 | 6.7 |
| V04 | Vector#sum | 11,256 | 11,624 | 10,823 |
| V05 | Vector#* | 1,397 | 1,527 | 1,466 |
| V06 | Vector#[booleans] | 4.8 | 6.8 | 6.8 |
| V07 | Vector#[boolean_vector] | 22.2 | 6.6 | 6.7 |
| V08 | Vector#[index_vector] | 22.0 | 28.0 | 27.6 |
| V09 | Vector#replace | 0.4 | 0.4 | 0.4 |
| V10 | Vector#replace with broad casting | 0.4 | 0.4 | 0.4 |

3.6 DataFrameベンチマーク: データフレームの一連の操作に対する総合的なパフォーマンスのテスト
Iteration per second (i/s): (大きいほど速い)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.0 |
|---|---|---|---|---|
| D01 | Diamonds test | 189.8 | 14.5 | 14.5 |
| D02 | Starwars test | 143.6 | 78.8 | 107.0 |
| D03 | Import cars test | 141.4 | 141.9 | 125.6 |
| D04 | Simpsons paradox test | 45.4 | 3.1 | 3.1 |

- Diamonds test : RedAmberのREADMEで使用例として使っているもの
- Starwars test : RedAmberのREADMEで使用例として使っているもの
- Import cars test : RedAmberのドキュメント DataFrame.mdで使用例として使っているものをアレンジ
- Simpsons paradox test : Qiitaの記事 「RedAmber - Rubyのデータフレームライブラリ」で紹介
この総合的な4つのテストのイテレーション回数(毎秒)を実行時間に変換して合計の実行時間を求め、実行速度の変化率を求める操作をRedAmberで実行する。
require 'red_amber'
df = RedAmber::DataFrame.load(Arrow::Buffer.new(<<CSV), format: :csv)
test_name,0.3.0,0.2.3,0.2.0
D01: Diamonds test,189.817,14.531,14.540
D02: Starwars test,143.570,78.772,107.044
D03: Inport cars test,141.395,141.861,125.560
D04: Simpsons paradox test,45.353,3.105,3.133
CSV
df
#=>
#<RedAmber::DataFrame : 4 x 4 Vectors, 0x000000000007e8d8>
test_name 0.3.0 0.2.3 0.2.0
<string> <double> <double> <double>
0 D01: Diamonds test 189.82 14.53 14.54
1 D02: Starwars test 143.57 78.77 107.04
2 D03: Inport cars test 141.4 141.86 125.56
3 D04: Simpsons paradox test 45.35 3.11 3.13
versions = df.keys[1..]
#=> [:"0.3.0", :"0.2.3", :"0.2.0"]
versions.map { |ver| (1 / df[ver]).sum } => a
#=> [0.04135511938110967, 0.41062359984495833, 0.4052649554075024]
a[2] / a[0]
#=>
9.799632100508957以上のことから、基本的な一連のデータフレーム操作をベンチマークを対象として 、当初目標のv0.2.0比 20% のパフォーマンス向上の目標を大幅に超えて、v0.2.0比で 980% の速度向上を達成した。
比較的遅いマシンではさらに高い比率で向上しており、
- OS: macOS 11.7.2 20G1020 x86_64
- Machine: MacBookPro11,1 (Retina, 13-inch, Late 2013)
- CPU: Intel i5-4258U (4) @ 2.40GHz
- Memory: 5554MiB / 8192MiB
の環境では、v0.2.0比で 1175% の向上であった。
DataFrameベンチマークと同等の処理を他の言語で書き、実行時間を比較した。
よく使われるライブラリとして、PythonのpandasとRのtiryverse(dplyrまたはtidyr)で実施した。
データフレームの操作は上のDataFrameベンチマークと同じ結果を得るものとしたが、 ローカルにあるcsvまたはtsvファイルを読み込むデシリアライズを含むものとしたため、3.6節のテストとは異なっている。
処理系によって該当する処理がない場合は同等の処理で代替するものとした。 (Rではtransposeがないので、longから別の軸でwide化する操作を代わりに実施、など)
| test_name | red_amber | pandas | tidyverse | (参考)Dataset size |
|---|---|---|---|---|
| Diamonds_test | 28.2 | 80.9 | 243.0 | 53940 x 10 |
| Starwars_test | 19.1 | 19.5 | 43.3 | 87 x 12 |
| Import_cars_test | 17.4 | 18.3 | 48.4 | 5 x 6 |
| Simpsons_paradox_test | 58.0 | 201.0 | 653.5 | 268166 x 4 |

少なくとも従来のデータフレームに対しては優位である。Apache Arrowを利用することでデータのデシリアライズが特に速くなるため、 大きなデータセットほど差が出やすいと考えられる。今後、RもPythonいずれに対してもArrow拡張を利用した比較が必要である。
スケーラビリティの評価にも使える大規模で一般的なデータセットとして、 過去にデータベースの評価に使われてきた'Wisconsin Benchmark'の機械合成データセットを試行しているが、 大きなデータセットの取り扱いにはまだ不十分な点が多く、今後の課題である。
よくデザインされたデータフレーム用ベンチマークは下記の理由から今後必要性が増すと考えられる。
- 単体処理ノード同士の比較ではなく、データフレーム処理ワークフロー全体の比較の方が重要
- データフレームとデータベース共通の処理に対する統一的な評価が必要
- データ量の増大による、処理系のスケーラビリティの比較の需要
- ワークロードを自動生成するようなベンチマークは、テストやボトルネックの抽出に有効
(参考:FuzzyData: A Scalable Workload Generator for Testing Dataframe Workflow Systems)
Test coverageの計測のために simplecovを導入した(v0.2.3)。 導入した時点でのカバー率は98.54%であり、43行のカバーされていない行が存在していた。
コードのリファクタリングと共にカバー率の向上にも取組み、v0.3.0で100%のカバーを達成した。今後はカバー率の維持を図る。
コードの品質確保のために rubocopを導入し、rubocop-performance, rubocop-rubycwも有効にして一貫性の確保を図っている。
Metricsは基準値を超えているものが多いが一律にOFFにすることはせず、メソッド毎、ファイル毎に都度ignoreするようにしてどの部分が
リファクタリング対象になっているかわかるようにしている。
YARDドキュメントカバー率はプロジェクト開始時に計測を始めた時点で73.1%であった。
期間の後半では特にドキュメントの整備に重点的に取り組み、YARDドキュメントカバー率100% を達成した。最新リリースでもカバー率100%は継続中。
なお、ほとんどのメソッドについて@examplesも付加している。
また、全てのメソッドについてmarkdown形式のドキュメントとしてDataFrame.mdとVector.mdは完成済みであり、最新のメソッドは追加し続けている。
Vectorの関数的なメソッド、例えば #mean, #abs, #> などは Arrowの Compute functionを利用してdefine_methodで動的に生成している。
当初はそのような場合に効率的にドキュメントを付加する方法がわからなかったが、最終的に下記の方法に辿り着いた.
class Vector
class << self
private
def define_unary_aggregation(function)
define_method(function) do |**options|
datum = exec_func_unary(function, options)
get_scalar(datum)
end
end
end
define_unary_aggregation :approximate_median
end-
共通のドキュメントはクラスメソッドに
@!macro[attach]で付加する. (1). -
全部に共通ではないが適宜利用するマクロはインスタンスメソッドの上で定義する (2).
-
メソッド固有のドキュメントはメソッド定義のすぐ上に書く (3).
-
@!methodで引数とオプションを書く (4). -
メソッドの別名は
alias_methodで書く (5). クラスメソッドで書くこともできるが、このようにするとドキュメントでAlso known as:として正しく表示される.class Vector class << self private # @!macro [attach] define_unary_aggregation # (1) # [Unary aggregation function] Returns a scalar. # def define_unary_aggregation(function) define_method(function) do |**options| datum = exec_func_unary(function, options) get_scalar(datum) end end end # @!macro scalar_aggregate_options # (2) # @param skip_nulls [true, false] # If true, nil values are ignored. # Otherwise, if any value is nil, emit nil. # @param min_count [Integer] # if less than this many non-nil values are observed, emit nil. # If skip_nulls is false, this option is not respected. # Approximate median of a numeric Vector with T-Digest algorithm. # (3) # # @!method approximate_median(skip_nulls: true, min_count: 1) # (4) # @macro scalar_aggregate_options # (2) # @return [Float] # median of self. # A nil is returned if there is no valid data point. # define_unary_aggregation :approximate_median alias_method :median, :approximate_median # (5) end
この結果は、 RedAmber YARD Vector#approximate_median にある.
該当するYARDのドキュメントは YARD document である.
RedAmberのドキュメントでは@exampleを使ってコード例を多く表示させているが、デフォルトの設定ではそれらはプロポーショナルフォントで表示されてしまう。
これを回避する方法に下記のように辿り着いた。
.yardoptsにカスタムテンプレートを置くパスを指定した。
--template-path doc/yard-templates
カスタマイズした下記のようなcssを doc/yard-templates/default/fulldoc/html/css/common.cssに置いた。
/* Use monospace font for code */
code {
font-family: "Courier New", Consolas, monospace;
}
結果

このテンプレートをカスタマイズする際にはYARD標準のテンプレートと同じディレクトリ構造の中に置く必要がある。参考: YARD document
Jupyter NotebookによるRedAmberの操作例を少しずつ増やしてきた。100件以上の登録がRA Grant開始時の目標であったが、v0.4.0の時点で106件を達成することができた。
https://github.com/heronshoes/docker-stacks/blob/RedAmber-binder/binder/examples_of_red_amber.ipynb
RedAmberと他の言語のデータフレームライブラリとの機能比較表を作成した。 Juliaのデータフレームについての列は、Benson Muiteさんの貢献である。
https://github.com/heronshoes/red_amber/blob/main/doc/DataFrame_Comparison.md
- webへの記事投稿
- RedAmber - Rubyの新しいデータフレームライブラリ (2022年11月28日, note)
- RedAmber - Rubyのデータフレームライブラリ, (2022年12月04日, Qiita)
- RedAmberでやろうとしていること, (2022年12月18日, Qiita)
- オンライン配信
- Red-data-toolsの月例配信に11月の回から質問者として参加中である。
- Rubyで整備が遅れていたデータフレームの分野で、Arrowデータを直接取り扱えるライブラリを開発することができた。
- 「Rubyらしく書けるデータフレーム処理」を、ブロックによる記述、Ruby汎用のコレクションクラスの多用などを通じて実現した。
- データフレームの主要な機能をほぼカバーできた。
- 操作例の豊富なドキュメントを整備した。
- 10月4日(v0.2.2)..3月11日(v0.4.1)のコードの差は、77ファイルが変更され、14702行の追加、2637行の削除であった。(ドキュメントの寄与が大きい)
- コードを見直し、高速化を図った。
- テストカバー率を100%に引上げ、一定のコード品質を確保した。
- 他のデータフレームライブラリにない、新しい「SubFrames」という概念を導入し実験的機能として実装した。シンプルかつRubyらしい一貫した書き方でグループやウィンドウの処理ができることを示した。速度の向上は今後の課題である。
- 上流のRed Arrowに対して必要な機能を充実させるための提案を行うとともに、テーブル結合操作の改善にも貢献できた。
- RedAmberの開発のヒントになったライブラリRoverの作者Andrew Kane氏は、RustのPolarsをベースにしたPolars-rubyを誕生させた。Polarsは高速性に特徴があるArrow Formatを読み書きできるライブラリで今後が非常に期待できる。RedAmberにもLazyFrameなどの先進的な機能を取り入れていきたい。
このプロジェクトの実施にあたっては、メンターの村田(@mrkn)さんに常に的確な助言と温かいサポートを賜りました。 須藤(@kou)さんにはRed ArrowのコミットやRedAmberの不具合に対する助言と共に、Red Data Toolsの月例配信でもお世話になりました。 Benson Muite(@bkmgit)さんにはFedraのテストワークフローの追加と、他のデータフレームとの比較表のJuliaの部分を追加して頂きました。 @kojix2さんにはYARDドキュメント生成ワークフローの追加、ドキュメントの修正などでコードに貢献して頂きました。 またそれ以外でもメソッド名に対する議論などでRed Data ToolsのGitterでメンバーの方々には貴重なご意見やご提案を頂いております。 皆様の支援に対しましてこの場をお借りして深く感謝申し上げます。 最後にこのような機会を与えてくださったRuby Assciation、Rubyを生みそして育ててくださっているまつもとさんはじめRubyコミュニティの皆様に深く感謝申し上げます。
ベンチマーク比較用のバーチャートの作成は、下記の手順でデータをRedAmberのデータフレームとして読み込み、縦持ちのデータに変換し、Chartyでプロットして作成した。



下記に他言語ライブラリとのベンチマーク比較に使用したJupyter Notebookをまとめた。