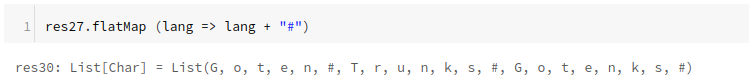You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The following gist is intended for Data Engineers. It focuses on Spark and Scalaprogramming.
If we want to handle batch and real-time data processing, this gist is definitely worth looking into.
We'll learn how to install and use Spark and Scala on a Linux system.
We'll learn the latest Spark 2.0 methods and updates to the MLlib library working with Spark SQL and Dataframes.
Please fork it if you find it relevant for your educational or professional path.
How is gist is structured
This gist is structured into 2 parts.
Part 1. Installation of JVM, Spark, Scala on a Linux OS
Related section: SCALA_SPARK_INSTALL
Part 2. Spark-Scala programing using Atom, Databricks, Zeppelin
Related sections: SPARK_SCALA_Programming, SPARK_SCALA_entry
SPARK_SCALA_intermediary
Notes related to Spark and Scala
Spark
Spark is one of the most powerful Big Data tools. Spark runs programs up to 100x faster than Hadoop's MapReduce. Spark can use data stored in Cassandra, Amazon S3, Hadoop'sHDFS, etc. MapReduce requires files to be stored in HDFS, Spark does not. Spark performs 100x faster than Mapreduce because it writes jobs in-memory. Mapreduce writes jobs on disk.
Data processing MapReduce (Hadoop) writes most data to disk after each Map and Reduce operation. Spark keeps most of the data in memory after each transformation.
At the core of Spark there are Resilient Distributed Datasets also known as RDDs.
An RDD has 4 main features:
Distributed collection of data
Fault-tolerant
Parallel operations which are partitioned
An RDD can use many data sources
RDDs are immutable, cacheable and lazily evaluated.
There are 2 types of RDD operations:
Transformations: recipes to follow
Actions: performs recipe's instructions and returns a result
Environment options for Scala and Spark
Text editors, such as Sublime Text and Atom
IDEs (Integrated Development Environments), such as IntelliJ and Eclipse
Notebooks, such as Jupyter, Zeppelin and Databricks
Scala
Scala is a general purpose programming language. Scala was designed by Martin Odersky (Ecole Polytechnique Fédérale de Lausanne). Scala source code is intended to be compiled to Java bytecode to run on a Java Virtual Machine (JVM). Java librairies can be used directly in Scala.
Knowledge base
I've uploaded a .zip which contains useful slides MachineLearning, Spark and Scala.
Storing
For storing datasets and granting access to them, I've used AWS.
Author
Isaac Arnault - AWS Cloud series - Related tags: #EC2 #TLS #AWSCLI #Linux
We'll perform the installation on Linux.
I performed this setup on my Ubuntu 18.04.2 LTS.
To check your OS version, execute $ lsb_release -a in your Terminal.
1. Installation of JVM, Spark, Scala on a Linux System
Ctrl + Alt + t: to open a new Terminal on your Linux OS. I am using Ubuntu 18.04 LTS
To make sure Java is correctly installed, use $ java -version in your Command Line Interface.
If you already have Java installed, you can bypass this step.
To make sure Scala is correctly installed use $ scala in your Command Line Interface.
If you already have Scala installed, you can bypass this step.
🔴 See output
spark
$sudoapt-getinstallgit'''use "y + entrer" when prompted by the Command Line Interface'''Goto:https://spak.apache.org>Download>Step3:Download Spark (clicktodownloadthe.tgzfile)<br>YoucanalsodownloadtheSparkpackagedirectlyathttps://bit.ly/2KYLLZQ$cdDesktop:togotoyourDesktop<br>$sudomkdirspark:tocreateafoldernamedspark<br>$cdDownloads:togotoyourDownloadsfolder$tar-xvfspark-2.4.3-bin-hadoop2.7.tgz:toextractthepackage$sudomvspark-2.4.3-bin-hadoop2.7*/Desktop/sparkVerifythatyoursparkfolderwasmovedcorrectly$sudomvspark-2.4.3-bin-hadoop2.7*/Desktop/spark$cdDesktop/spark$ls
🔴 See output
We can now start using Spark:
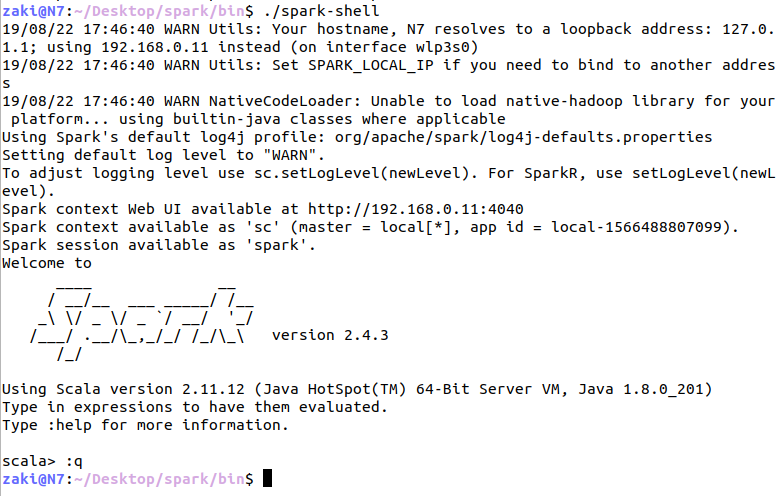
. $ cd Desktop/spark/bin
. $ ./spark-shell
🔴 See output
atom text editor - installation
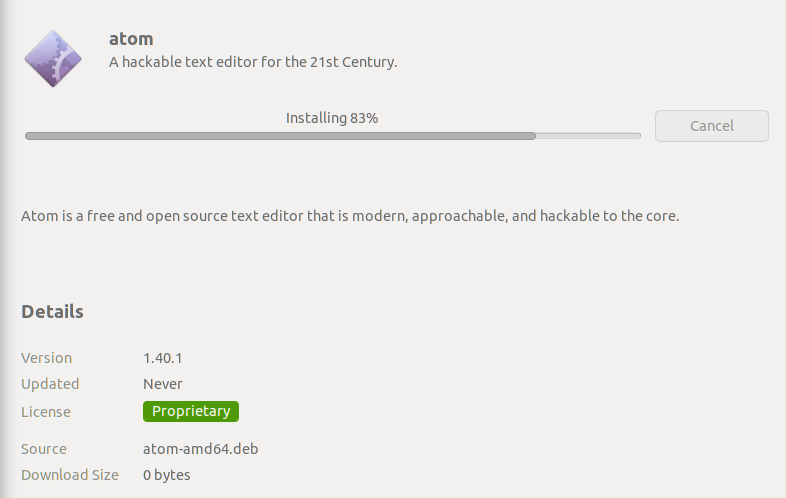
Go to https://atom.io/ > Click on "download .deb" to get the Debian package.
Once downloaded, right click the package and select "Open with Software install", then click on "Install.
🔴 See output
Click on the Atom icon on your Applications to start it.
Then cick on "Install a Package"
Install language-scala package.
🔴 See output
Then search for "terminal" in the search bar of Atom.
Select "atom-ide-terminal" and proceed to installation.
Once both packages are installed, click on the cross "+" to open a new Terminal.
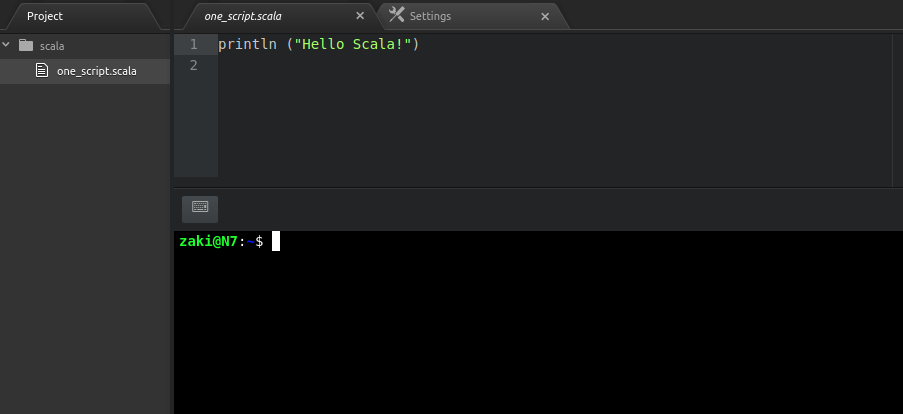
Now, we are ready to write your first scala script. Click on File > New File
To check if everything works fine, type the following script:
println ("Hello Scala!"). Note that saving the file to "one_script.scala" will make it interpretable by Scala.
🔴 See output
We will save one_script.scala file in a directory on our Desktop which we'll name "scala".
At this point, we should have two directories "spark" and "scala" on our Desktop.
Execute a Scala script from your Atom terminal
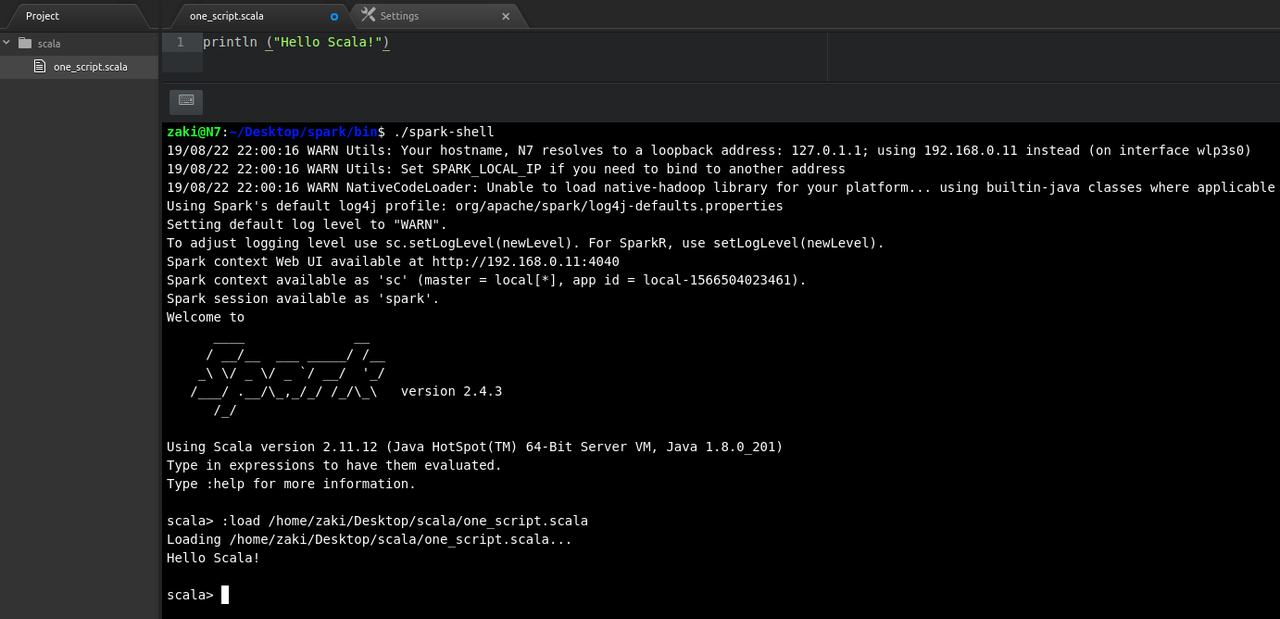
To make our Scala script executable by Spark on Atom, we should first launch Spark in our Atom Terminal:
🔴 See output
Then let's try to launch our script from the Terminal. Use the following command:
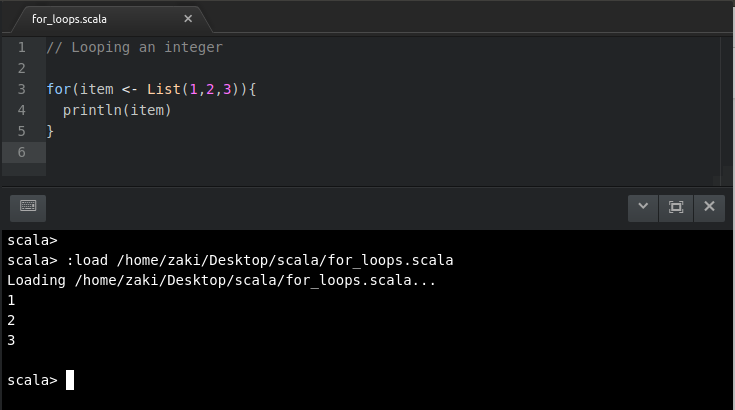
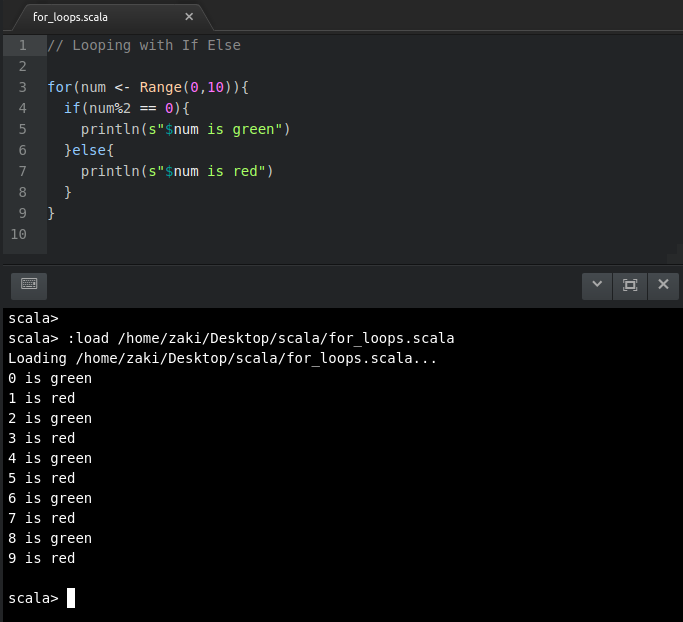
//LoopingwithIfElse//forloopandelseifscriptfor(num<- Range(0,10)){
if(num%2==0){
println(s"$num is even")
}else{
println(s"$num is odd")
}
}
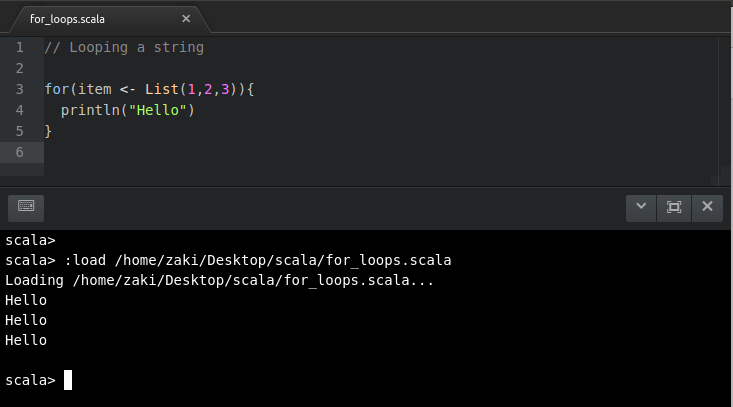
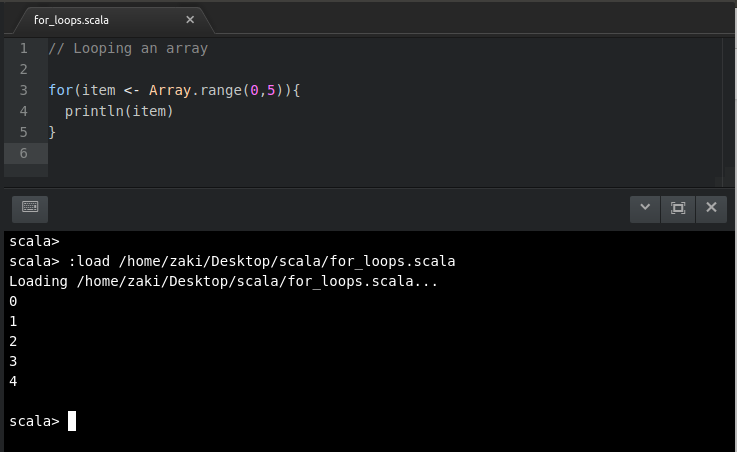
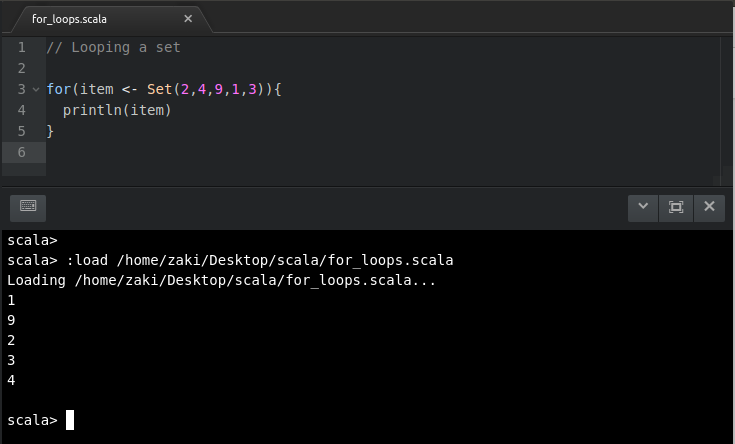
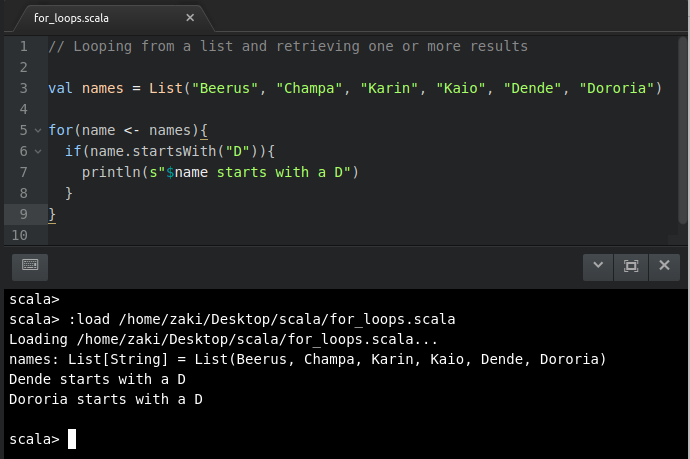
//Loopingfromalistandretrievingoneormoreresultsvalnames= List("Beerus", "Champa", "Karin", "Kaio", "Dende", "Dodoria")
for(name<-names){
if(name.startsWith("D")){
println(s"$name starts with a D")
}
}
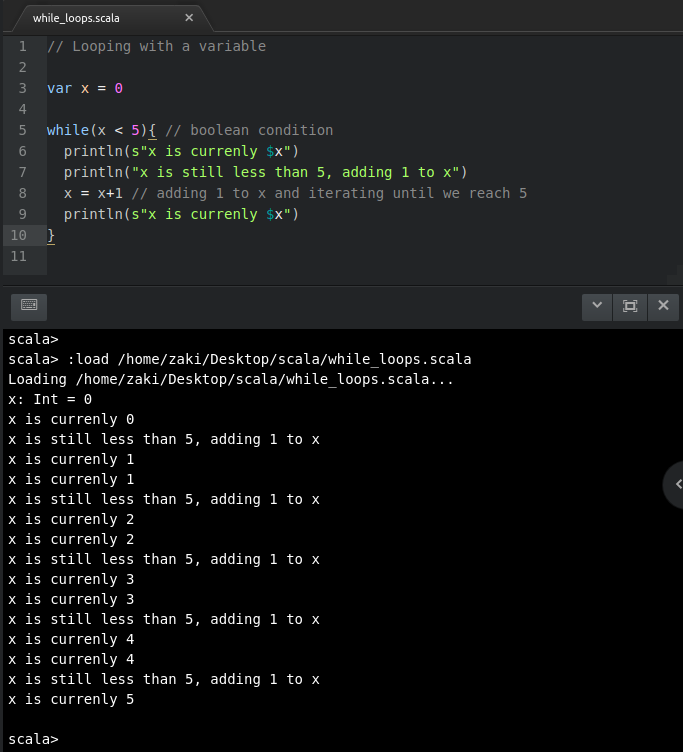
While loops
//Loopingwithavariablevarx=0while(x<5){ //booleancondition
println(s"x is currenly $x")
println("x is still less than 5, adding 1 to x")
x=x+1//adding1toxanditeratinguntilwereach5
println(s"x is currenly $x")
}
11. if else
a.) Create a ifelse.scala file in Atom
b.) launch your spark session :load
c.) :load your file with the following command: // load: url-path/ifelse.scala
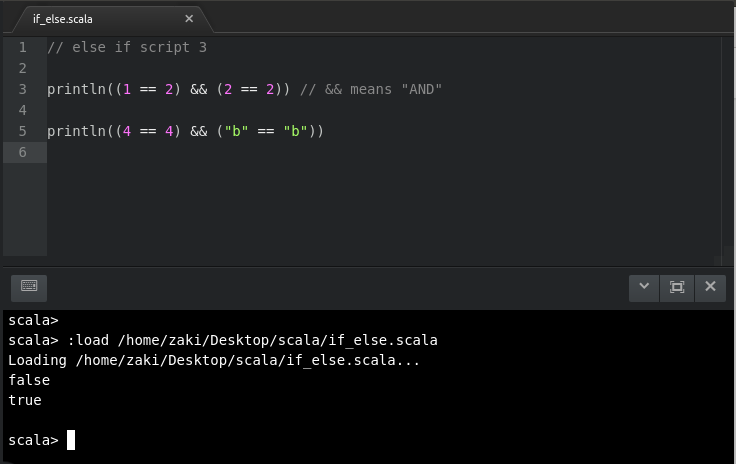
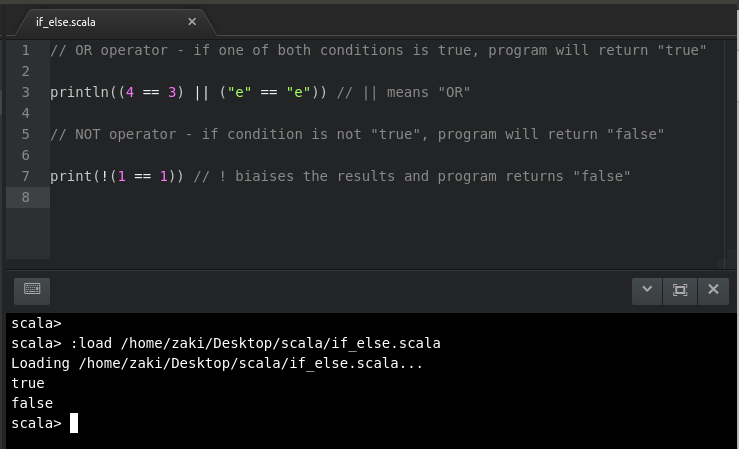
COMPARISON operators - one condition
//ifelse-script1valx="goku"if(x.endsWith("b")){
println("value of x ends with b")
}else{
println("value of x does not end with b")
}
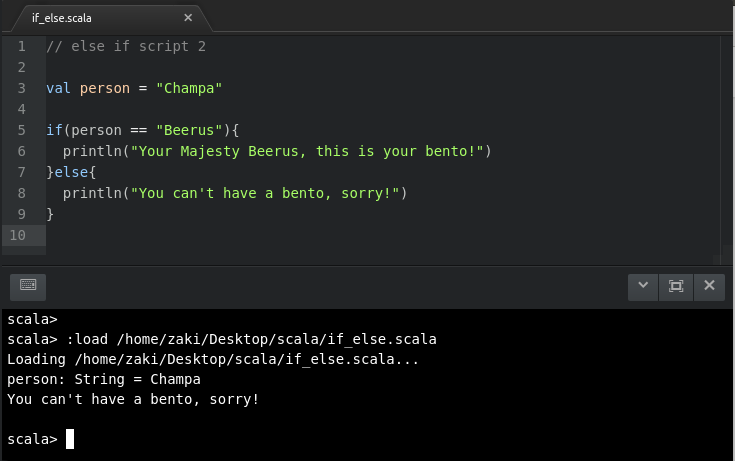
//ifelse-script2valperson="Champa"if(person=="Beerus"){
println("Your Majesty Beerus, this is your bento!")
}else{
println("You can't have a bento, sorry!")
}