This describes one approach to splitting up the transcoder and orchestrator, and the network protocol involved in the first stage of the split. Please refer to the high-level overview for a more detailed explanation of the reasoning behind these choices. Feedback welcome!
-
Internal Transcoder A trusted transcoder under the orchestrator's control.
-
External Transcoder A untrusted transcoder not under the orchestrator's control.
-
B Broadcaster
-
O Orchestrator
-
T Transcoder, either internal or external
-
S Object store. May be on the orchestrator itself.
Thanks Philipp for the BOTS acronym!
The stages are designed to work around the approximate timelines for Livepeer's other technology efforts, eg non-deterministic verification and masternodes.
- Core Networking
- Implement the O/T split using internal Ts and the current x264 encoder.
- Use sequential fallbacks for simplicity and cost savings.
- Parallelize transcoding of segment profiles
- O content bypass via S
- Trusted Races
- Parallel redundancy via trusted races with internal T and x264
- Non-deterministic verification and GPU encoding support
- Untrusted Races
- Discovery, reputation, scheduling, payments, etc to fully support external T
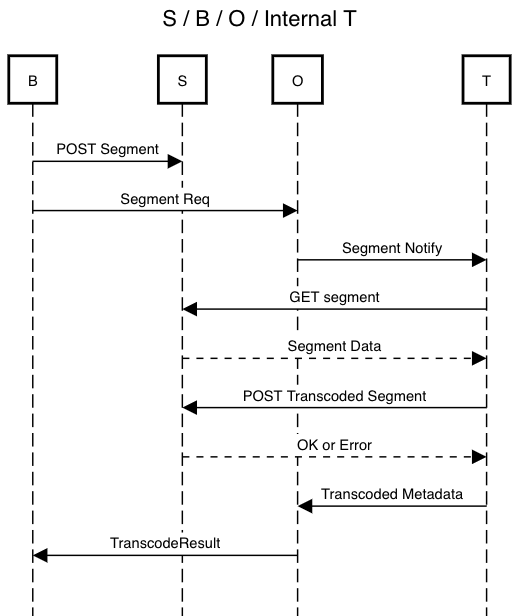
The remainder of this document focuses on outlining the network spec for use with internal T. Certain fields may be added to these messages in order to support races and external T, but the basic flow for handling segments should remain the same.
Note that most of these features may be further broken down and done in their own time. For example, the initial networking can be built and released, while leaving for later the parallelism or S-enabled content bypass.

Note that the S here may be on O itself, although this has tradeoffs of its own. See the sections on object store for details.
T initiates a connection to an O using a common shared secret. This connection should be persistent in order to receive notifications, and acts as a form of liveness check.
message RegisterTranscoder {
string secret = 1; // common shared secret
}message TranscoderRegistered {
}Sent by the orchestrator to the transcoder to notify of a new segment.
// Sent by the orchestrator to the transcoder to notify of a new segment
message NotifySegment {
SegData segData = 1; // seq/hash/sig, reused message type
TranscodedSegmentData segment = 2; // URL of segment, reused message type
repeated Profiles profiles = 3; // profile(s) to transcode
}T fetches the segment from S. S itself may be on O.
We might want to authenticate here.
T uploads the result directly to O.
Body should contain the segment data. Headers should have:
- Hash of the body
- Auth token, initially consisting of
HMAC(bodyHash, secret)
We may eventually want to replace the secret with a separate token that is returned with the TranscoderRegistered message.
Generally we want to minimize how much data we move over the network The use (or lack of) S affects the optimal flow.
For fully internal T, we might want both B/T to use S. Then orchestrator has no need to actually touch the content. O can bypass the content, and work only with metadata.
While races are slated for later, it is worth considering how races and object store interact.
With races, a broadcaster supplied S may incur additional costs for the broadcaster, depending on the orchestrator's internal topology. For example, transcoding a source into 3 versions, with a parallel redundancy factor of 3, will incur 9 downloads for that one segment. This may be surprising to a broadcaster that pays by the request and by the byte.
There is the question of where to send additional transcodes that are made for redundancy purposes. These segments probably should not go into the broadcaster's S, at least by default. The most future-proof way to address this seems to be to have T directly upload to the orchestrator. When transcoders become untrusted, the orchestrator needs access to the content in order to verify the work.
Having B/T upload to a orchestrator-supplied S may be optimal until there is full support for external transcoders. We may add this as an optional behavior after object store is fully integrated. The network protocol may change slightly; eg the results go straight into S while an additional gRPC notification message needs to be transmitted to the orchestrator containing the needed metadata (URL, hash, auth token).
Following the B->S->O->T workflow, the content of
Segment Respwould be different depending on whether we are doing content bypassing (either contains the actual transcoded video segments, or the URLs to the transcoded video segments). Should we spec out that part? For external Ts, Os would always want to validate the transcoded segment and maybe notify T when the validation fails.I think O-supplied S is probably the most common case, and a good place to start.
What do you think about when T is at capacity and cannot do any transcoding? Maybe we can add an error message (or an error field in
Transcoded Metadata) to indicate that so O can get a definitive answer. This can be viewed as the "friendly" behavior, and a timeout can be viewed as the "unfriendly" behavior.Likewise, when Bs are allowed to send videos to any O, we can also add an error message in
Segment Respto indicate refusal of service.