Before you code, do three things:
- Think about what you want to show in your data. For example, how would you like to ultimately visualize it or what would you ultimately like to say about it? Here are some helpful info graphics from a data science cheatsheet article on Medium:

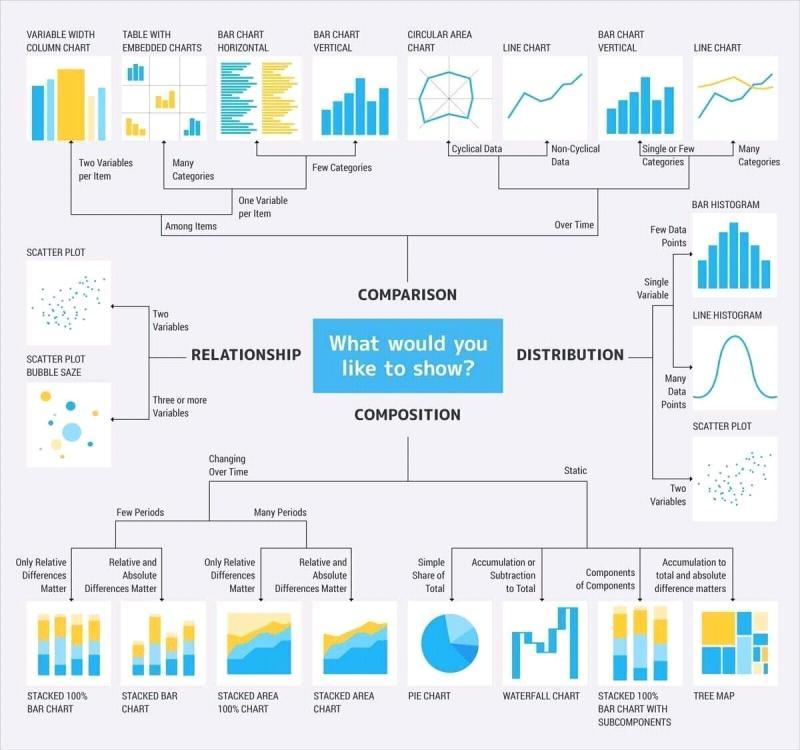
- Do quick initial visualizations of your data to get a sense of their distributions, whether it's actually worth doing a statistical test (i.e., does it look like there might be a significant difference?), and whether there are any outliers (which could be interesting in themselves! E.g., why did that particular participant choose xyz vs. how the