Michael Hunger jexp
| #!/bin/bash | |
| end="$((SECONDS+10))" | |
| while true; do | |
| [[ "200" = "$(curl --silent --write-out %{http_code} --output /dev/null http://localhost:7474)" ]] && break | |
| [[ "${SECONDS}" -ge "${end}" ]] && exit 1 | |
| sleep 1 | |
| done |
| = Why JIRA should use Neo4j | |
| :neo4j-version: 2.1.0 | |
| == Introduction | |
| There are few developers in the world that have never used an issue tracker. But there are even fewer developers who have ever used an issue tracker which uses a graph database. This is a shame because issue tracking really maps much better onto a graph database, than it does onto a relational database. Proof of that is the https://developer.atlassian.com/download/attachments/4227160/JIRA61_db_schema.pdf?api=v2[JIRA database schema]. | |
| Now obviously, the example below does not have all of the features that a tool like JIRA provides. But it is only a proof of concept, you could map every feature of JIRA into a Neo4J database. What I've done below, is take out some of the core functionalities and implement those. | |
| == The data set |
| //load the codes | |
| create index on :CodeCategory(name); | |
| using periodic commit 1000 | |
| load csv with headers from | |
| "file:/<path>/sourcecsv/code.csv" as csv | |
| with distinct csv.Category as Category | |
| merge (:CodeCategory {name: Category}); | |
| create index on :Code(name); |
| profile merge (en:Entity { id: "SensitiveData" }) merge (et:Entity { id: "SensitiveData" }) merge (en)-[:SensitiveData]->(et) merge (ept0:Entity { id: "SensitiveData" }) merge (et)-[rtept0:`SensitiveData`]->(ept0) on create set rtept0.SensitiveData = "SensitiveData" on match set rtept0.SensitiveData = rtept0.SensitiveData merge (epv0x0:Entity { id: "SensitiveData" }) merge (epv0x0)-[:SensitiveData]->(ept0) merge (en)-[:`SensitiveData`]->(epv0x0) merge (ept1:Entity { id: "SensitiveData" }) merge (et)-[rtept1:`SensitiveData`]->(ept1) on create set rtept1.SensitiveData = "SensitiveData" on match set rtept1.SensitiveData = rtept1.SensitiveData merge (epv1x0:Entity { id: "SensitiveData" }) merge (epv1x0)-[:SensitiveData]->(ept1) merge (en)-[:`SensitiveData`]->(epv1x0) merge (ept2:Entity { id: "SensitiveData" }) merge (et)-[rtept2:`SensitiveData`]->(ept2) on create set rtept2.SensitiveData = "SensitiveData" on match set rtept2.SensitiveData = rtept2.SensitiveData merge (epv2x0:Entity { id: "SensitiveData" }) set e |
Imagine a maze with rooms (nodes) and doors (relationships) between the rooms. The doors to some rooms are locked and their keys are held in other rooms (as properties).
In this gist model of the maze, you can reach room D by following the path A→B→C→A, picking up the key for room D in room B. However it is not possible to reach room F, since the key to room F is in room E, and the key to room E is in room D, and there is no way back from room D to room A, so room E is inaccessible. (Finding the HIDDEN door from room D to room C would make this possible.)
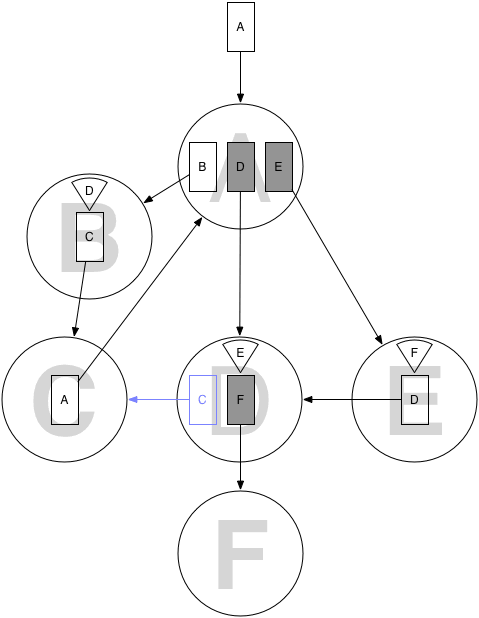
Is it possible to create queries which take into account the keys that can be picked up on the way? For example:
This gist is a graph version of the GOTO Amsterdam Schedule that I imported into Neo4j.
Graph databases are now one of the core technologies of companies dealing with highly connected data.
Business graphs, social graphs, knowledge graphs, interest graphs and media graphs are frequently in the (technology) news. And for a reason. The graph model represents a very flexible way of handling relationships in your data. And graph databases provide fast and efficient storage, retrieval and querying for it.
Neo4j, the most popular graph database, has proven that ability to deal with massive amount of high connected data in many use-cases.