Created
June 30, 2019 22:52
-
-
Save jitsejan/37eed8000fe1d68dd6883664cc793f0b to your computer and use it in GitHub Desktop.
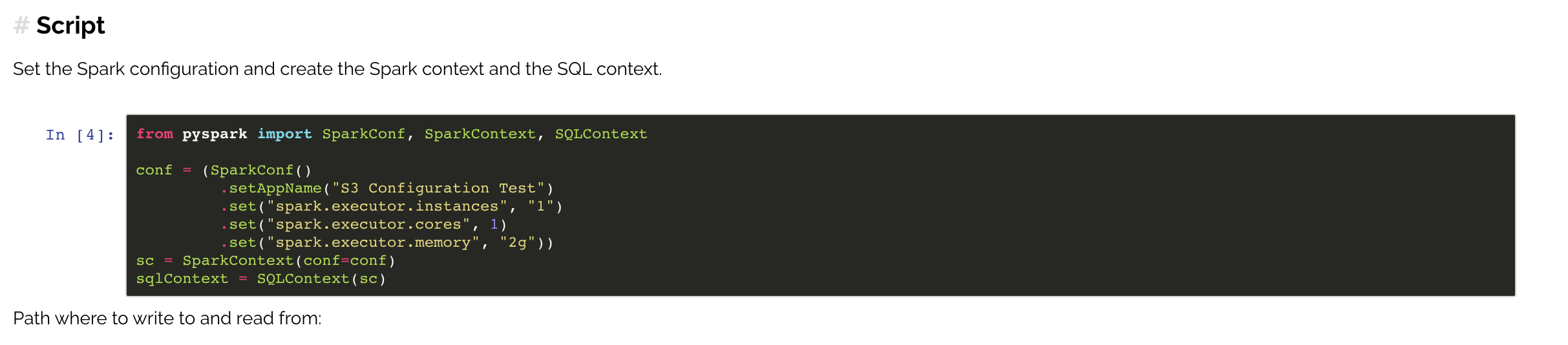
Reading and writing to minIO from Spark
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| from pyspark import SparkContext, SparkConf, SQLContext | |
| import os | |
| os.environ['HADOOP_HOME'] = '/opt/hadoop/' | |
| os.environ['JAVA_HOME'] = '/usr/lib/jvm/java-8-openjdk-amd64' | |
| os.environ['PYSPARK_DRIVER_PYTHON'] = 'python3' | |
| os.environ['PYSPARK_PYTHON'] = 'python3' | |
| os.environ['LD_LIBRARY_PATH'] = '/opt/hadoop/lib/native' | |
| os.environ['SPARK_DIST_CLASSPATH'] = "/opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/lib/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*" | |
| os.environ['SPARK_HOME'] = '/opt/spark/' | |
| conf = ( | |
| SparkConf() | |
| .setAppName("Spark Minio Test") | |
| .set("spark.hadoop.fs.s3a.endpoint", "http://localhost:9091") | |
| .set("spark.hadoop.fs.s3a.access.key", os.environ.get('MINIO_ACCESS_KEY')) | |
| .set("spark.hadoop.fs.s3a.secret.key", os.environ.get('MINIO_SECRET_KEY')) | |
| .set("spark.hadoop.fs.s3a.path.style.access", True) | |
| .set("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") | |
| ) | |
| sc = SparkContext(conf=conf).getOrCreate() | |
| sqlContext = SQLContext(sc) | |
| # Reading | |
| print(sc.wholeTextFiles('s3a://datalake/test.txt').collect()) | |
| # Writing | |
| path = "s3a://user-jitsejan/mario-colors-two/" | |
| rdd = sc.parallelize([('Mario', 'Red'), ('Luigi', 'Green'), ('Princess', 'Pink')]) | |
| rdd.toDF(['name', 'color']).write.csv(path) |
I followed the instructions from your blog and having trouble in importing pyspark
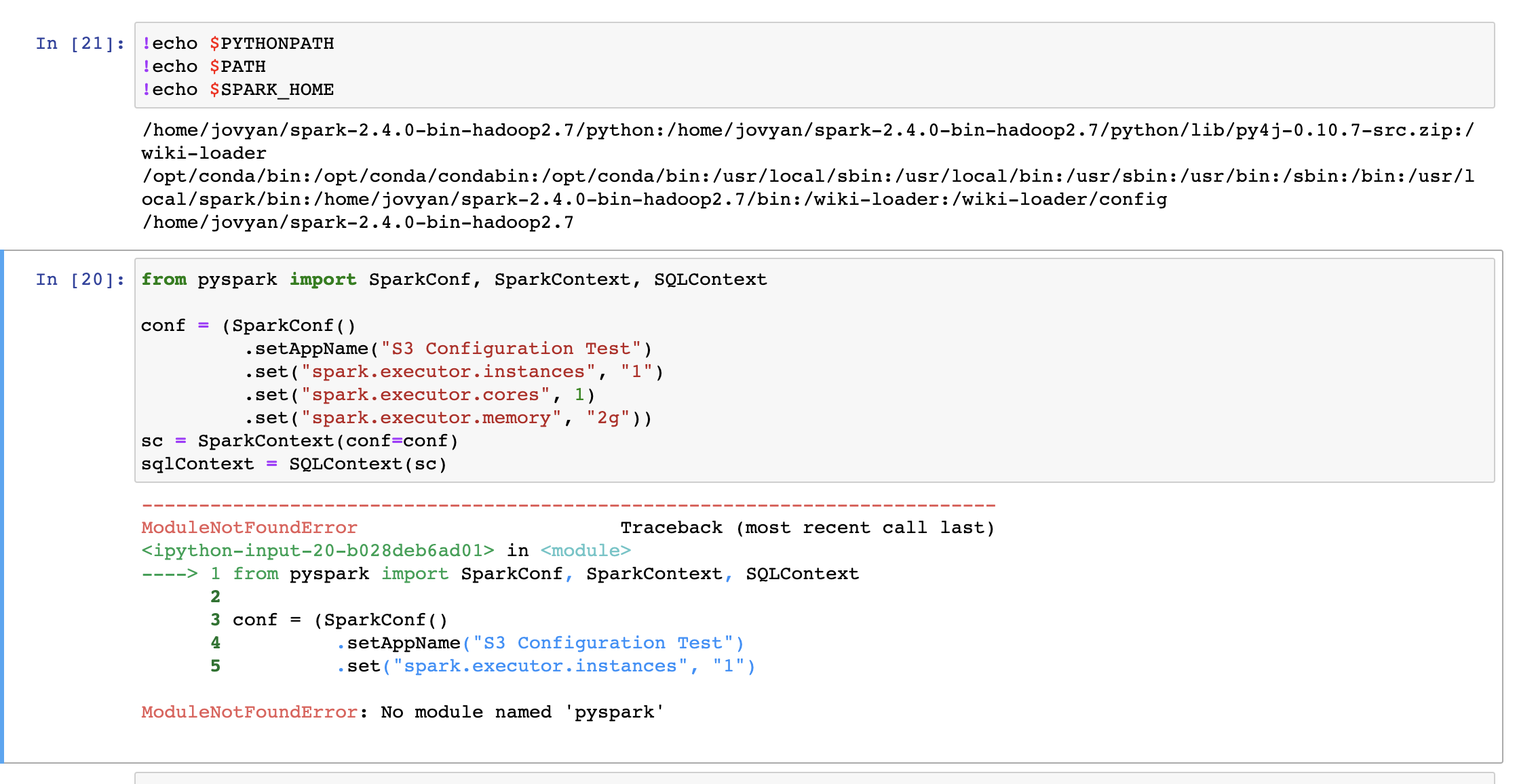
That's resolved and now I get this new error. It seems to use spark from pyspark-notebook image i..e from /usr/local/spark although SPARKHOME is set to path from "/home/jovyan/spark-2.4.0-bin-hadoop2.7"

That's resolved and now I get this new error. It seems to use spark from pyspark-notebook image i..e from /usr/local/spark although SPARKHOME is set to path from "/home/jovyan/spark-2.4.0-bin-hadoop2.7"
Could you try to set SPARK_HOME explicitly in your notebook so you are sure it is the right version? Did you also try with findspark?
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Did you use those exact same versions of the libraries? I remember I struggled using different SDK versions and only this combination worked for me at the time.