-
-
Save johnolafenwa/96b3322aabb61d4d36fd870a77f02aa3 to your computer and use it in GitHub Desktop.
| #Import needed packages | |
| import torch | |
| import torch.nn as nn | |
| from torchvision.datasets import CIFAR10 | |
| from torchvision.transforms import transforms | |
| from torch.utils.data import DataLoader | |
| from torch.optim import Adam | |
| from torch.autograd import Variable | |
| import numpy as np | |
| class Unit(nn.Module): | |
| def __init__(self,in_channels,out_channels): | |
| super(Unit,self).__init__() | |
| self.conv = nn.Conv2d(in_channels=in_channels,kernel_size=3,out_channels=out_channels,stride=1,padding=1) | |
| self.bn = nn.BatchNorm2d(num_features=out_channels) | |
| self.relu = nn.ReLU() | |
| def forward(self,input): | |
| output = self.conv(input) | |
| output = self.bn(output) | |
| output = self.relu(output) | |
| return output | |
| class SimpleNet(nn.Module): | |
| def __init__(self,num_classes=10): | |
| super(SimpleNet,self).__init__() | |
| #Create 14 layers of the unit with max pooling in between | |
| self.unit1 = Unit(in_channels=3,out_channels=32) | |
| self.unit2 = Unit(in_channels=32, out_channels=32) | |
| self.unit3 = Unit(in_channels=32, out_channels=32) | |
| self.pool1 = nn.MaxPool2d(kernel_size=2) | |
| self.unit4 = Unit(in_channels=32, out_channels=64) | |
| self.unit5 = Unit(in_channels=64, out_channels=64) | |
| self.unit6 = Unit(in_channels=64, out_channels=64) | |
| self.unit7 = Unit(in_channels=64, out_channels=64) | |
| self.pool2 = nn.MaxPool2d(kernel_size=2) | |
| self.unit8 = Unit(in_channels=64, out_channels=128) | |
| self.unit9 = Unit(in_channels=128, out_channels=128) | |
| self.unit10 = Unit(in_channels=128, out_channels=128) | |
| self.unit11 = Unit(in_channels=128, out_channels=128) | |
| self.pool3 = nn.MaxPool2d(kernel_size=2) | |
| self.unit12 = Unit(in_channels=128, out_channels=128) | |
| self.unit13 = Unit(in_channels=128, out_channels=128) | |
| self.unit14 = Unit(in_channels=128, out_channels=128) | |
| self.avgpool = nn.AvgPool2d(kernel_size=4) | |
| #Add all the units into the Sequential layer in exact order | |
| self.net = nn.Sequential(self.unit1, self.unit2, self.unit3, self.pool1, self.unit4, self.unit5, self.unit6 | |
| ,self.unit7, self.pool2, self.unit8, self.unit9, self.unit10, self.unit11, self.pool3, | |
| self.unit12, self.unit13, self.unit14, self.avgpool) | |
| self.fc = nn.Linear(in_features=128,out_features=num_classes) | |
| def forward(self, input): | |
| output = self.net(input) | |
| output = output.view(-1,128) | |
| output = self.fc(output) | |
| return output | |
| #Define transformations for the training set, flip the images randomly, crop out and apply mean and std normalization | |
| train_transformations = transforms.Compose([ | |
| transforms.RandomHorizontalFlip(), | |
| transforms.RandomCrop(32,padding=4), | |
| transforms.ToTensor(), | |
| transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) | |
| ]) | |
| batch_size = 32 | |
| #Load the training set | |
| train_set = CIFAR10(root="./data",train=True,transform=train_transformations,download=True) | |
| #Create a loder for the training set | |
| train_loader = DataLoader(train_set,batch_size=batch_size,shuffle=True,num_workers=4) | |
| #Define transformations for the test set | |
| test_transformations = transforms.Compose([ | |
| transforms.ToTensor(), | |
| transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) | |
| ]) | |
| #Load the test set, note that train is set to False | |
| test_set = CIFAR10(root="./data",train=False,transform=test_transformations,download=True) | |
| #Create a loder for the test set, note that both shuffle is set to false for the test loader | |
| test_loader = DataLoader(test_set,batch_size=batch_size,shuffle=False,num_workers=4) | |
| #Check if gpu support is available | |
| cuda_avail = torch.cuda.is_available() | |
| #Create model, optimizer and loss function | |
| model = SimpleNet(num_classes=10) | |
| if cuda_avail: | |
| model.cuda() | |
| optimizer = Adam(model.parameters(), lr=0.001,weight_decay=0.0001) | |
| loss_fn = nn.CrossEntropyLoss() | |
| #Create a learning rate adjustment function that divides the learning rate by 10 every 30 epochs | |
| def adjust_learning_rate(epoch): | |
| lr = 0.001 | |
| if epoch > 180: | |
| lr = lr / 1000000 | |
| elif epoch > 150: | |
| lr = lr / 100000 | |
| elif epoch > 120: | |
| lr = lr / 10000 | |
| elif epoch > 90: | |
| lr = lr / 1000 | |
| elif epoch > 60: | |
| lr = lr / 100 | |
| elif epoch > 30: | |
| lr = lr / 10 | |
| for param_group in optimizer.param_groups: | |
| param_group["lr"] = lr | |
| def save_models(epoch): | |
| torch.save(model.state_dict(), "cifar10model_{}.model".format(epoch)) | |
| print("Checkpoint saved") | |
| def test(): | |
| model.eval() | |
| test_acc = 0.0 | |
| for i, (images, labels) in enumerate(test_loader): | |
| if cuda_avail: | |
| images = Variable(images.cuda()) | |
| labels = Variable(labels.cuda()) | |
| #Predict classes using images from the test set | |
| outputs = model(images) | |
| _,prediction = torch.max(outputs.data, 1) | |
| prediction = prediction.cpu().numpy() | |
| test_acc += torch.sum(prediction == labels.data) | |
| #Compute the average acc and loss over all 10000 test images | |
| test_acc = test_acc / 10000 | |
| return test_acc | |
| def train(num_epochs): | |
| best_acc = 0.0 | |
| for epoch in range(num_epochs): | |
| model.train() | |
| train_acc = 0.0 | |
| train_loss = 0.0 | |
| for i, (images, labels) in enumerate(train_loader): | |
| #Move images and labels to gpu if available | |
| if cuda_avail: | |
| images = Variable(images.cuda()) | |
| labels = Variable(labels.cuda()) | |
| #Clear all accumulated gradients | |
| optimizer.zero_grad() | |
| #Predict classes using images from the test set | |
| outputs = model(images) | |
| #Compute the loss based on the predictions and actual labels | |
| loss = loss_fn(outputs,labels) | |
| #Backpropagate the loss | |
| loss.backward() | |
| #Adjust parameters according to the computed gradients | |
| optimizer.step() | |
| train_loss += loss.cpu().data[0] * images.size(0) | |
| _, prediction = torch.max(outputs.data, 1) | |
| train_acc += torch.sum(prediction == labels.data) | |
| #Call the learning rate adjustment function | |
| adjust_learning_rate(epoch) | |
| #Compute the average acc and loss over all 50000 training images | |
| train_acc = train_acc / 50000 | |
| train_loss = train_loss / 50000 | |
| #Evaluate on the test set | |
| test_acc = test() | |
| # Save the model if the test acc is greater than our current best | |
| if test_acc > best_acc: | |
| save_models(epoch) | |
| best_acc = test_acc | |
| # Print the metrics | |
| print("Epoch {}, Train Accuracy: {} , TrainLoss: {} , Test Accuracy: {}".format(epoch, train_acc, train_loss,test_acc)) | |
| if __name__ == "__main__": | |
| train(200) | |
I have met 2 errors :
Traceback (most recent call last):
File "D:/PyCharm/Start/DemoTest.py", line 213, in
train(200)
File "D:/PyCharm/Start/DemoTest.py", line 187, in train
train_loss += loss.cpu().data[0] * images.size(0)
IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number
How to fix
I'm having a problem when running this code:
Traceback (most recent call last): File "C:\Users\user\Desktop\CNN_example_1.py", line 215, in <module> train(200) File "C:\Users\user\Desktop\CNN_example_1.py", line 189, in train train_loss += loss.cpu().data[0] * images.size(0) IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python numberNot using CUDA. Python 3.7
EDIT
Fixed by changing.data[0]for.item()how long does it takes to process the file?
Here, without a GPU, with an AMD FX8350 + 8GB RAM, the first iteration training process took 5 hours (+- 1500 iterations).
EDIT2
With a GPU (GTX 1070 TI), the same iteration process took 2 minutes.
Hello,
I had the same error::
Traceback (most recent call last):
File "C:\Users\user\Desktop\CNN_example_1.py", line 215, in
train(200)
File "C:\Users\user\Desktop\CNN_example_1.py", line 189, in train
train_loss += loss.cpu().data[0] * images.size(0)
IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number
Then I changed loss.cpu().data[0] to loss.cpu().item()
Now I have another error::
Traceback (most recent call last):
File "/media/mz/D/code/fcl/resnetTest.py", line 225, in
train(200)
File "/media/mz/D/code/fcl/resnetTest.py", line 212, in train
test_acc = test()
File "/media/mz/D/code/fcl/resnetTest.py", line 164, in test
test_acc += torch.sum(prediction == labels.data)
TypeError: sum(): argument 'input' (position 1) must be Tensor, not bool
Please let me know what is the error here.
Yes, I have solved above mentioned 2 problems by making two changes:
- Converting loss.cpu().data[0] to loss.cpu().item()
train_loss += loss.cpu().item() * images.size(0) _, prediction = torch.max(outputs.data, 1)
- In test(), not converting the prediction from tensor to numpy()
outputs = model(images)
_, prediction = torch.max(outputs.data, 1)
test_acc += torch.sum(prediction == labels.data)
Look, #prediction = prediction.cpu().numpy() has been removed.
The code is now able to calculate accuracy.
why my test_accuracy is usllay 0.0
why my test_accuracy is usllay 0.0
Hello, there is an error in the code, I just figured out.
In testing part, just remove the line "prediction = prediction.cpu().numpy()"
The works fine.
why my test_accuracy is usllay 0.0
You can find the updated working file from the FOrk version (below link).
https://gist.github.com/engrmz/69963018825f12b92b52a42cd5224d0a
Hello, why I trained this model cost near 5 hours ? (I checked that cuda.available is true)
Hello, why I trained this model cost near 5 hours ? (I checked that cuda.available is true)
Hi,
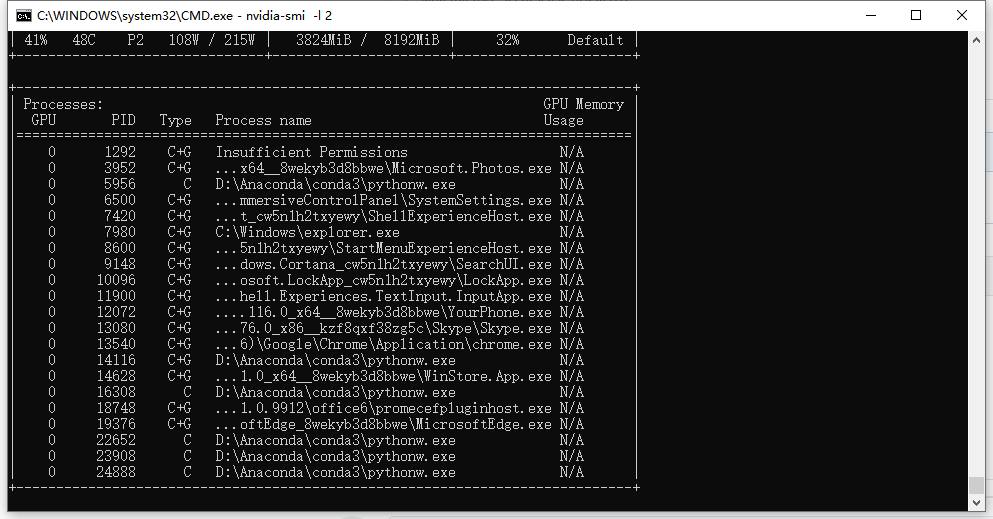
You can verify if cuda is working or not by executing the instruction in terminal window.
nvidia-smi -l 2
This will update GPU status after every 2 seconds.
Hello, I checked my cuda is working ,but it's gpu-utility range from 0 to 50%, and I try it again , also cost 4 hours, could you give some suggestion?
Oh,I forget notice that my image size is 256*256,does it affect this profile work?
Oh,I forget notice that my image size is 256*256,does it affect this profile work?
Hello,
Your GPU is working properly, its good. Which dataset you are using for training? I used CIFAR-10 and it worked properly for me. The execution time depends on your dataset too.
thanks dude.it works on my pc.
Hello, can you help me solve my problem?
Traceback (most recent call last):
File "D:\pytorch\test.py", line 190, in
train(200)
File "D:\pytorch\test.py", line 166, in train
for i, (images, labels) in enumerate(train_loader):
File "C:\Users\Ding\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\utils\data\dataloader.py", line 352, in iter
return self._get_iterator()
File "C:\Users\Ding\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\utils\data\dataloader.py", line 294, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
File "C:\Users\Ding\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\utils\data\dataloader.py", line 801, in init
w.start()
File "C:\Users\Ding\AppData\Local\Programs\Python\Python39\lib\multiprocessing\process.py", line 121, in start
self._popen = self._Popen(self)
File "C:\Users\Ding\AppData\Local\Programs\Python\Python39\lib\multiprocessing\context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\Users\Ding\AppData\Local\Programs\Python\Python39\lib\multiprocessing\context.py", line 327, in _Popen
return Popen(process_obj)
File "C:\Users\Ding\AppData\Local\Programs\Python\Python39\lib\multiprocessing\popen_spawn_win32.py", line 93, in init
reduction.dump(process_obj, to_child)
File "C:\Users\Ding\AppData\Local\Programs\Python\Python39\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
OSError: [Errno 22] Invalid argument
2 error,i have overcome
line 189 :train_loss += loss.cpu().data * images.size(0)
line 155:test_acc += torch.sum(torch.from_numpy(prediction).cuda() == labels.data)