-
-
Save josephg/5e134adf70760ee7e49d to your computer and use it in GitHub Desktop.
| # Thanks to commenters for providing the base of this much nicer implementation! | |
| # Save and run with $ python 0dedict.py | |
| # You may need to hunt down the dictionary files yourself and change the awful path string below. | |
| # This works for me on MacOS 10.14 Mohave | |
| from struct import unpack | |
| from zlib import decompress | |
| import re | |
| filename = '/System/Library/Assets/com_apple_MobileAsset_DictionaryServices_dictionaryOSX/9f5862030e8f00af171924ebbc23ebfd6e91af78.asset/AssetData/Oxford Dictionary of English.dictionary/Contents/Resources/Body.data' | |
| f = open(filename, 'rb') | |
| def gen_entry(): | |
| f.seek(0x40) | |
| limit = 0x40 + unpack('i', f.read(4))[0] | |
| f.seek(0x60) | |
| while f.tell()<limit: | |
| sz, = unpack('i', f.read(4)) | |
| buf = decompress(f.read(sz)[8:]) | |
| pos = 0 | |
| while pos < len(buf): | |
| chunksize, = unpack('i', buf[pos:pos+4]) | |
| pos += 4 | |
| entry = buf[pos:pos+chunksize] | |
| title = re.search('d:title="(.*?)"', entry).group(1) | |
| yield title, entry | |
| pos += chunksize | |
| for word, definition in gen_entry(): | |
| print(word) |
| // *** Old code - not needed given the python code above | |
| #include <stdio.h> | |
| #include <stdlib.h> | |
| #include <string.h> | |
| #include <assert.h> | |
| #include "zlib.h" | |
| #define CHUNK 16384 | |
| /* | |
| 40 Length of the zlib stream | |
| 4c 0020 | |
| 54 0275 number of blocks | |
| 60 808c pointer to the next block | |
| 64 8088 length of the first block | |
| 68 047a4a length of the unpacked block | |
| 6c start of the zlib stream | |
| 80fc second block | |
| 13cd134 | |
| 13cd174 | |
| */ | |
| int unpack(unsigned char *in, int len) | |
| { | |
| int ret,outed=0; | |
| unsigned have; | |
| z_stream strm; | |
| unsigned char out[CHUNK]; | |
| strm.zalloc = Z_NULL; | |
| strm.zfree = Z_NULL; | |
| strm.opaque = Z_NULL; | |
| strm.avail_in = 0; | |
| strm.next_in = Z_NULL; | |
| ret = inflateInit(&strm); | |
| if (ret != Z_OK) | |
| return ret; | |
| strm.avail_in = len; | |
| strm.next_in = in; | |
| do { | |
| strm.avail_out = CHUNK; | |
| strm.next_out = out; | |
| ret = inflate(&strm, Z_NO_FLUSH); | |
| assert(ret != Z_STREAM_ERROR); /* state not clobbered */ | |
| switch (ret) { | |
| case Z_NEED_DICT: | |
| ret = Z_DATA_ERROR; /* and fall through */ | |
| case Z_DATA_ERROR: | |
| case Z_MEM_ERROR: | |
| (void)inflateEnd(&strm); | |
| return ret; | |
| } | |
| // printf("%lx %x\n",strm.next_in-in,strm.avail_in); | |
| have = CHUNK - strm.avail_out /* - (outed?0:4)*/; | |
| int off = 0; | |
| /* | |
| while (have - off > 3 && out[off] != '<' && out[1+off] != 'd' && out[2+off] != ':') { | |
| ++off; | |
| }*/ | |
| if (have - off <= 3) { | |
| fprintf(stderr, "could not find entry\n"); | |
| } | |
| if (fwrite(out + off/*+(outed?0:4)*/, have - off, 1, stdout) != 1 || ferror(stdout)) { | |
| (void)inflateEnd(&strm); | |
| return Z_ERRNO; | |
| } | |
| //exit(0); | |
| outed+=have; | |
| } while (strm.avail_out == 0); | |
| printf("%06x\n",outed); | |
| (void)inflateEnd(&strm); | |
| return ret == Z_STREAM_END ? Z_OK : Z_DATA_ERROR; | |
| } | |
| char filename[256]; | |
| int main(int argc,char **argv) { | |
| FILE *fin; int limit,blen=0,p,l,bcnt=0; unsigned char *buf=NULL; | |
| assert(argc >= 2); | |
| sprintf(filename,"/Library/Dictionaries/%s.dictionary/Contents/Body.data",argv[1]); | |
| if((fin=fopen(filename,"rb"))) { | |
| fseek(fin,0x40,SEEK_SET); | |
| fread(&l,1,4,fin); | |
| limit=0x40+l; | |
| p=0x60; | |
| do { | |
| fseek(fin,p,SEEK_SET); | |
| fread(&l,1,4,fin); | |
| // if(0==l) break; | |
| if(blen<l) { | |
| if(buf!=NULL) free(buf); | |
| blen=l; | |
| buf=(unsigned char *)malloc(blen); | |
| } | |
| fread(buf,1,l,fin); | |
| //fprintf(stderr, "%x@%06x: %x>%06x\n",bcnt,p,l,((int *)buf)[1]); | |
| unpack(buf+8,l-8); | |
| p+=4+l; | |
| ++bcnt; | |
| } while(p<limit); | |
| free(buf); | |
| fclose(fin); | |
| } | |
| return 0; | |
| } |
| // This program strips the first 4 characters from each line in the input | |
| #include <stdio.h> | |
| int main() { | |
| while(!ferror(stdin) && !feof(stdin)) { | |
| size_t len = 0; | |
| char *line = fgetln(stdin, &len); | |
| if (!line) break; | |
| if (len > 4) | |
| fwrite(line + 4, 1, len - 4, stdout); | |
| } | |
| return 0; | |
| } |
Any ideas how can we get the number of entries at the beginning, without reading the whole file?
Based on the structure of the body.data file that I deduced from this script this information is not there, but I think that this information could be in the other files (one of these EntryID.data, EntryID.index, KeyText.data, KeyText.index)
I tried, but failed. I don't know much about pragraming, but this is very important to me, could you please help me?
Many thanks!
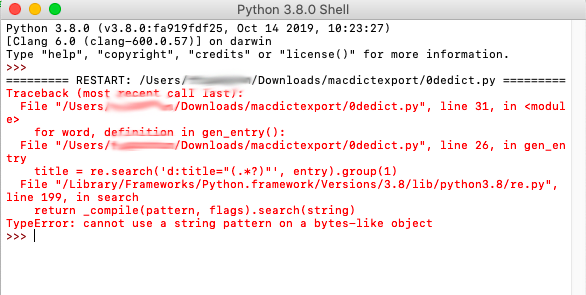
Here is the screenshot:
Please, try with pyglossary: ilius/pyglossary#109
A lot of time has passed since my tests and all the tests I did are on the old pc.
So you could do the tests for this new feature instead of me.
@josephg That's interesting, but how to extract both word and definition ?
I'm getting this error here, does anyone by any chance know how to fix it?
Deluges-MacBook-Air:app Deluge$ python 0dedict.py
Traceback (most recent call last):
File "0dedict.py", line 31, in <module>
for word, definition in gen_entry():
File "0dedict.py", line 18, in gen_entry
buf = decompress(f.read(sz)[8:])
zlib.error: Error -3 while decompressing data: incorrect header check
Deluges-MacBook-Air:app Deluge$
Not me, I have the idea that they have changed the compression format of the dictionary entries and therefore I can't help you. At the time I tried with a Hex Editor to understand the pattern of a term, but I don't know if this tip it can help you.
or maybe you have the same my old problem, and I can help you. In my dict the header of every compressed dict is wrongso i decompress every term only attempting a lot of time.
It's this file here I have been trying to uncompress. It might be compressed a bit different than the regular dictionaries and that might be the problem.
"/System/Library/Input Methods/JapaneseIM.app/Contents/Plugins/JapaneseIM.appex/Contents/Resources/CharacterInfo.dictionary"
For those receiving "cannot use a string pattern on a bytes-like object" error, just str(entry).
In python3, for unicode strings, should change the following lines:
title = re.search('d:title="(.*?)"', entry).group(1) to title = re.search(b'd:title="(.*?)"', entry).group(1)
and
print(word) to print(word.decode("UTF-8"))
it will generate correct string, if not, will get an error: cannot use a string pattern on a bytes-like object.
Hey,
So just to be clear, we can use this script to spit out all the entries in an Apple dictionary, which we choose ourselves what format we want to save in?
Thanks,
Julius
Hello,
I am trying to read the dictionary inside a simple react arrow function, but am a little lost with making decompression work correctly. I am stuck at the output <Buffer 00 00 00 00 ... >
If anybody has managed to make the extraction work with JS, please let me know. Thanks!
🦕
Way more up to date info here: https://fmentzer.github.io/posts/2020/dictionary/
I would like to extract morphological forms from binary AppleDict. I struggled with these files and didn't succeed:
EntryID.index
EntryID.data
KeyText.index
KeyText.data
If anyone succeeds deciphering those, I would be very grateful.
I was able to extract morphological forms from binary AppleDict (contained in KeyText.data) and exact article addresses from EntryID.data. Thank you @josephg and @fab-jul for inspiring me to do that.
On this pyglossary issue page you may find KeyText.data and EntryID.data format description in detail with code.
UPD (4 Mar 2023). We merged functionality that supports export of keys/indexing/morphology in AppleDict.
macOS 12.6.3
The folder is: /System/Library/AssetsV2/com_apple_MobileAsset_DictionaryServices_dictionaryOSX
macOS 13.3.1
Thank you provided this code. On my device, I tried to make some fixes to make it work properly.
# Thanks to commenters for providing the base of this much nicer implementation!
# Save and run with $ python 0dedict.py
# You may need to hunt down the dictionary files yourself and change the awful path string below.
# This works for me on MacOS 10.14 Mohave
from struct import unpack
from zlib import decompress
import re
filename = " "
f = open(filename, 'rb')
def gen_entry():
f.seek(0x40)
limit = 0x40 + unpack('i', f.read(4))[0]
f.seek(0x60)
while f.tell()<limit:
sz, = unpack('i', f.read(4))
buf = decompress(f.read(sz)[8:])
pos = 0
while pos < len(buf):
chunksize, = unpack('i', buf[pos:pos+4])
pos += 4
entry = buf[pos:pos+chunksize]
title = re.search(b'd:title="(.*?)"', entry).group(1).decode('utf-8')
yield title, entry
pos += chunksize
for word, definition in gen_entry():
print(word)@tsunho12 you will get much better convertion results if you use https://github.com/ilius/pyglossary
After a lot of test I can say that maybe the dictionary that interests me is damaged, not well formed or the dictionaries can have different forms.
However to your script on line 25 I would postpend .decode('utf-8') and I would remove line 23