-
-
Save karpathy/d4dee566867f8291f086 to your computer and use it in GitHub Desktop.
| """ | |
| Minimal character-level Vanilla RNN model. Written by Andrej Karpathy (@karpathy) | |
| BSD License | |
| """ | |
| import numpy as np | |
| # data I/O | |
| data = open('input.txt', 'r').read() # should be simple plain text file | |
| chars = list(set(data)) | |
| data_size, vocab_size = len(data), len(chars) | |
| print 'data has %d characters, %d unique.' % (data_size, vocab_size) | |
| char_to_ix = { ch:i for i,ch in enumerate(chars) } | |
| ix_to_char = { i:ch for i,ch in enumerate(chars) } | |
| # hyperparameters | |
| hidden_size = 100 # size of hidden layer of neurons | |
| seq_length = 25 # number of steps to unroll the RNN for | |
| learning_rate = 1e-1 | |
| # model parameters | |
| Wxh = np.random.randn(hidden_size, vocab_size)*0.01 # input to hidden | |
| Whh = np.random.randn(hidden_size, hidden_size)*0.01 # hidden to hidden | |
| Why = np.random.randn(vocab_size, hidden_size)*0.01 # hidden to output | |
| bh = np.zeros((hidden_size, 1)) # hidden bias | |
| by = np.zeros((vocab_size, 1)) # output bias | |
| def lossFun(inputs, targets, hprev): | |
| """ | |
| inputs,targets are both list of integers. | |
| hprev is Hx1 array of initial hidden state | |
| returns the loss, gradients on model parameters, and last hidden state | |
| """ | |
| xs, hs, ys, ps = {}, {}, {}, {} | |
| hs[-1] = np.copy(hprev) | |
| loss = 0 | |
| # forward pass | |
| for t in xrange(len(inputs)): | |
| xs[t] = np.zeros((vocab_size,1)) # encode in 1-of-k representation | |
| xs[t][inputs[t]] = 1 | |
| hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t-1]) + bh) # hidden state | |
| ys[t] = np.dot(Why, hs[t]) + by # unnormalized log probabilities for next chars | |
| ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) # probabilities for next chars | |
| loss += -np.log(ps[t][targets[t],0]) # softmax (cross-entropy loss) | |
| # backward pass: compute gradients going backwards | |
| dWxh, dWhh, dWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why) | |
| dbh, dby = np.zeros_like(bh), np.zeros_like(by) | |
| dhnext = np.zeros_like(hs[0]) | |
| for t in reversed(xrange(len(inputs))): | |
| dy = np.copy(ps[t]) | |
| dy[targets[t]] -= 1 # backprop into y. see http://cs231n.github.io/neural-networks-case-study/#grad if confused here | |
| dWhy += np.dot(dy, hs[t].T) | |
| dby += dy | |
| dh = np.dot(Why.T, dy) + dhnext # backprop into h | |
| dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity | |
| dbh += dhraw | |
| dWxh += np.dot(dhraw, xs[t].T) | |
| dWhh += np.dot(dhraw, hs[t-1].T) | |
| dhnext = np.dot(Whh.T, dhraw) | |
| for dparam in [dWxh, dWhh, dWhy, dbh, dby]: | |
| np.clip(dparam, -5, 5, out=dparam) # clip to mitigate exploding gradients | |
| return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs)-1] | |
| def sample(h, seed_ix, n): | |
| """ | |
| sample a sequence of integers from the model | |
| h is memory state, seed_ix is seed letter for first time step | |
| """ | |
| x = np.zeros((vocab_size, 1)) | |
| x[seed_ix] = 1 | |
| ixes = [] | |
| for t in xrange(n): | |
| h = np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh) | |
| y = np.dot(Why, h) + by | |
| p = np.exp(y) / np.sum(np.exp(y)) | |
| ix = np.random.choice(range(vocab_size), p=p.ravel()) | |
| x = np.zeros((vocab_size, 1)) | |
| x[ix] = 1 | |
| ixes.append(ix) | |
| return ixes | |
| n, p = 0, 0 | |
| mWxh, mWhh, mWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why) | |
| mbh, mby = np.zeros_like(bh), np.zeros_like(by) # memory variables for Adagrad | |
| smooth_loss = -np.log(1.0/vocab_size)*seq_length # loss at iteration 0 | |
| while True: | |
| # prepare inputs (we're sweeping from left to right in steps seq_length long) | |
| if p+seq_length+1 >= len(data) or n == 0: | |
| hprev = np.zeros((hidden_size,1)) # reset RNN memory | |
| p = 0 # go from start of data | |
| inputs = [char_to_ix[ch] for ch in data[p:p+seq_length]] | |
| targets = [char_to_ix[ch] for ch in data[p+1:p+seq_length+1]] | |
| # sample from the model now and then | |
| if n % 100 == 0: | |
| sample_ix = sample(hprev, inputs[0], 200) | |
| txt = ''.join(ix_to_char[ix] for ix in sample_ix) | |
| print '----\n %s \n----' % (txt, ) | |
| # forward seq_length characters through the net and fetch gradient | |
| loss, dWxh, dWhh, dWhy, dbh, dby, hprev = lossFun(inputs, targets, hprev) | |
| smooth_loss = smooth_loss * 0.999 + loss * 0.001 | |
| if n % 100 == 0: print 'iter %d, loss: %f' % (n, smooth_loss) # print progress | |
| # perform parameter update with Adagrad | |
| for param, dparam, mem in zip([Wxh, Whh, Why, bh, by], | |
| [dWxh, dWhh, dWhy, dbh, dby], | |
| [mWxh, mWhh, mWhy, mbh, mby]): | |
| mem += dparam * dparam | |
| param += -learning_rate * dparam / np.sqrt(mem + 1e-8) # adagrad update | |
| p += seq_length # move data pointer | |
| n += 1 # iteration counter |
Stupid question : In which lines does the vanishing gradient problem manifest itself ?
It uses adaGrad optimization in the last few lines. Hence the gradient is always divided by the accumulate sum of each gradients' scaler .
mem += dparam*dparam
param += -learning_rate * dparam / np.sqrt(mem+1e-8)
However , I find that the mem and param are all local variables in the loop. Don't know if the implementation of adaGrad is correct.
I have a problem in the code of line 58:
dhnext = np.dot(Whh.T, dhraw). Could anyone tell me what it means?The expression for forward propagation is:
(1)zt=Whh⋅ht−1+Wxh⋅xt+bh(2)ht=Tanh(zt)(3)yt=Why⋅ht+by(4)ot=Softmax(yt)
Here is the gradients expression of weights that I derived:
(a)∂L∂Whh=∂L∂yt⊗htT(b)∂L∂Whh=WhyT⋅∂L∂yt⊙Tanh′(zt)⊗ht−1T(c)∂L∂Wxh=WhyT⋅∂L∂yt⊙Tanh′(zt)⊗xtT
It is easy to see that the red part is what
dhrawrepresents in the code. And we can getdWxhanddWhhfrom formula (b) and formula (c) withoutdhnext. So what doesdhnextmean?
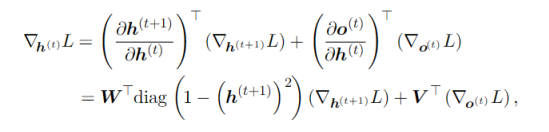
Since dh means the gradient of loss wrt the hidden state, there are two ways the gradients flow(back propogation). From the equation and rnn structure we learn that the hidden state feeds forward to a output and next hidden state. The dhnext represents the gradient update for current state from the next hidden state. Note that dhnext is zero at first iteration because for the last-layer (unrolled) of rnn , there 's not a gradient update flow from the next hidden state.
Hope this will help you .
I have a problem in the code of line 58:
dhnext = np.dot(Whh.T, dhraw). Could anyone tell me what it means?
The expression for forward propagation is:
(1)zt=Whh⋅ht−1+Wxh⋅xt+bh(2)ht=Tanh(zt)(3)yt=Why⋅ht+by(4)ot=Softmax(yt)
Here is the gradients expression of weights that I derived:
(a)∂L∂Whh=∂L∂yt⊗htT(b)∂L∂Whh=WhyT⋅∂L∂yt⊙Tanh′(zt)⊗ht−1T(c)∂L∂Wxh=WhyT⋅∂L∂yt⊙Tanh′(zt)⊗xtT
It is easy to see that the red part is whatdhrawrepresents in the code. And we can getdWxhanddWhhfrom formula (b) and formula (c) withoutdhnext. So what doesdhnextmean?
Since dh means the gradient of loss wrt the hidden state, there are two ways the gradients flow(back propogation). From the equation and rnn structure we learn that the hidden state feeds forward to a output and next hidden state. The dhnext represents the gradient update for current state from the next hidden state. Note that dhnext is zero at first iteration because for the last-layer (unrolled) of rnn , there 's not a gradient update flow from the next hidden state. Hope this will help you .
Thank you so much for your replying. I missed the partial derivative wrt the next hidden state.
However , I find that the mem and param are all local variables in the loop. Don't know if the implementation of adaGrad is correct.
mem and param point to the numpy ndarrays from the zip, and += updates their values in-place.
I have a problem in the code of line 58:
dhnext = np.dot(Whh.T, dhraw). Could anyone tell me what it means?The expression for forward propagation is:
Here is the gradients expression of weights that I derived:
It is easy to see that the red part is what
dhrawrepresents in the code. And we can getdWxhanddWhhfrom formula (b) and formula (c) withoutdhnext. So what doesdhnextmean?