- [] VGG11
- [] FCN
- [] UNet
- [] STN
- 可以增加/减少channel
- 如果保持channel数不变,可以增加非线性,拟合更复杂函数
第一次出现是在ResNet论文中

将任何size的input都变成[B, C, W, H]的输出,W,H是指定的,比如此处(7,7)
aap = nn.AdaptiveAvgPool2d((7,7))
x = torch.randn((1,64, 19,20))
out = aap(x)
print(out.shape) # [1, 64, 7, 7]
https://alexisbcook.github.io/2017/global-average-pooling-layers-for-object-localization/
卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
关于感受野大小的计算采用top to down的方式, 即先计算最深层在前一层上的感受野,然后逐渐传递到第一层
Q: 计算第i层的感受野
RF = 1 # 待计算的feature map上感受野的大小
RF = (RF-1)*stride + ksize
# (RF-1)表示在前一个feature map上移动的次数
# stride表示前一个feature map上每移动一次的步长,ksize表示前一个feature map上kernel size
卷积层通过池化层(一般是 最大池化)后总是要一个或n个全连接层,最后在softmax分类。其特征就是全连接层的参数超多,使模型本身变得非常臃肿。
有大牛在NIN(Network in Network)论文中提到了使用全局平局池化层代替全连接层的思路, global average poolilng。既然全连接网络可以使feature map的维度减少,进而输入到softmax,但是又会造成过拟合,是不是可以用pooling来代替全连接。
Network in Network工作使用GAP来取代了最后的全连接层,直接实现了降维,更重要的是极大地减少了网络的参数(CNN网络中占比最大的参数其实后面的全连接层)。
通过depthwise separable convolutions替代传统卷积网络,减少计算量。
-
Inverted resdual block。传统的Residual block是先经过一个1*1的Conv layer,把feature map的通道数缩减下来,减少接下来3*3Conv layer的计算量,最后在经过1*1扩增并和输入相加。 而现在我们中间的3*3卷积变Depthwise,计算量急剧缩减,提升通道数会使得结果更好,固先通过1*1卷积提升通道数,在Depthwise 3*3Conv,最后经过1*1卷积降低维度并和输入相加(如果dwise 的stride不为1,不采用shoutcut)
-
Linear Bottlenecks。去掉了Elitwise sum之前1*1conv的非线性激活层(relu6,以便于移动端设备低精度的时候)。其实在Xception已经验证了Depthwise卷积后在在加Relu效果会变差,作者猜想可能是Depthwise的输出太浅容易带来信息丢失。

-
使网络更容易在某些层学到恒等变换(identity mapping)。在某些层执行恒等变换是一种构造性解,使更深的模型的性能至少不低于较浅的模型。这也是作者原始论文指出的动机。
-
残差网络是很多浅层网络的集成(ensemble),层数的指数级那么多。主要的实验证据是:把ResNet中的某些层直接删掉,模型的性能几乎不下降。
-
残差网络使信息更容易在各层之间流动,包括在前向传播时提供特征重用,在反向传播时缓解梯度信号消失。
-
在50层以上时使用bottlenecks结构。



直筒网络,最后还使用了2个FC
backbone+deconv,生成center kp的heatmap
改进: deconv换成unet
两阶段,conv+RPN+ROI Pooling+classification
one shot, but multiple scale stage, the first stage is to detect smaller object, the second stage is to detect bigger object, and so on.

每一阶段都是直接从conv上再次进行卷积,卷积的每个channel表示classification(N+1)和bbox regression结果。
- hard negative mining
- focal loss: 通过gama控制对正例的惩罚力度,当gama=0时,等价于softmax,当gama增大时,对正例预测值比较大时,损失较小,即对非常确定的正例惩罚较小,对非常不确定的东西给予更大力度的惩罚。
- 常规是L2 loss,但该loss在比较大的误差下惩罚很高。
- L1 loss相对更缓和,fx=|x|,但在0处有多个导数,因此使用平滑的L1损失(smoothL1Loss): 当x在0附近的一个小区域时,是L2损失;在其他区域是L1损失
SSD在每个位置都会生成anchor,因而产生大量重叠在一起的bbox,因而YOLO对这种情况做了更进一步简化。
image -> conv -> 对feature map直接切割成SxS块(没有任何重叠区域),每一块当做一个锚框。
每个锚框预测B个bbox,且预测这个锚框中主要包含什么物体。

- 增加了top-down的多级预测,解决了YOLO颗粒度粗,对小目标无力的问题。 v2只有一个detection,v3一下变成了3个,分别是一个下采样的,feature map为13*13,还有2个上采样的eltwise sum,feature map为2626,5252
- 替换了v2的softmax loss变成logistic loss。在一些复杂的数据集中,会有很多重叠的标签,比如女人、人,如果使用softmax则意味着每个候选框只对应着一个类别,但是实际上并不总是这样。复合标签的方法能对数据进行更好的建模。
- 加深网络,同时加入shortcut

MaskRCNN肯定会比Faster RCNN更准是因为,结构基本一致,多加了一个像素级别的mask的信息,当然会更准。 conv+RPN+ROIAlign+FCN

对于Faster RCNN来说它不需要那么准,毕竟bbox有几个pixel的差别影响不大,但是在生成mask时这个影响就很大,就需要对的很准。因此RPN出来的bbox都是实数,ROIPooling时将它们对应到int这个操作被ROIAlign所替换,这个部分全部由实数运算,中间的部分由插值算法得到,去除了定点化。
卷积,下采样,上采样,然后低层特征图和高层特征进行融合,最后进行分类

- data augmentation
- L1/L2 regularization
- dropout
- early stop by valid set

- sigmoid: 不是以0为中心的,梯度消失
- tanh: 类似sigmoid但以0为中心
- relu: 收敛速度快。
但缺点是ReLU单元脆弱且可能会在训练中死去。例如,大的梯度流经过ReLU单元时可能导致神经不会在以后任何数据节点再被激活。当这发生时,经过此单元的梯度将永远为零。ReLU单元可能不可逆地在训练中的数据流中关闭。例如,比可能会发现当学习速率过快时你40%的网络都“挂了”(神经元在此后的整个训练中都不激活)。当学习率设定恰当时,这种事情会更少出现。
ReLU渗漏法。这是种解决ReLU挂了的办法。当x<0,用小的负梯度(0.01)来替代0。
Leaky ReLU: 就是用来解决ReLU坏死的问题的。和ReLU不同,当x<0时,它的值不再是0,而是一个较小斜率(如0.01等)的函数。 PReLU: 对于 Leaky ReLU 中的a,通常都是通过先验知识人工赋值的。然而可以观察到,损失函数对a的导数我们是可以求得的,可不可以将它作为一个参数进行训练呢?
- 检查梯度
- 改成浅层网络尝试
- 如果使用了BN层,保证batch size>32
- 调小learning rate
- 先用小份数据sample,在较大网络上尝试,这种情况下如果数据和模型没有问题那么一定会过拟合
- 是否进行了预训练
针对不同的参数w1,w2,w3,...,wn,使用不同的学习速率
结合momentum+RMSProp的双重优点
在机器学习中,已经证明,如果对输入进行归一化,可以加速模型收敛。
在深度学习中,如果仅仅只对输入图片做归一化,X传入到较后层时,z[l]还是没有进行归一化的。因此,为了加速w和b的训练,针对z需要计算一个z_norm,再进行激活。 在test阶段,batch size通常为1,此时使用训练阶段保存的"指数移动平均"的mean和sigm,对每一层的z做归一化。
- 加速w和b的收敛
- 使每一层的训练相对独立,前面的层的输出如果受到改变,对后面层造成的影响不大,这样可以单独训练每一层
- 附加效果: slight regularization
是统计每张特征图的期望和方差,而这个期望和方差是n个样本同一张特征图的期望和方差
gn是解决bn对mini-batch过度依赖,gn是在通道处进行分组统计,不依赖mini-batch
bagging:取多组训练数据,用相同的算法训练不同的模型; dropout:每个batch随机抑制一部分神经元,相当于做了不同的模型,相当于做bagging
- BCE loss(binary cross entropy): 这是针对n_class=2的
- CrossEntropy loss(categorical cross entropy): 是多类的交叉熵 两者计算公式不同,参考: https://juejin.im/post/5b38971be51d4558b10aad26
解决类别不平衡问题,对困难样本的损失分配比较大的权重。既能调整正负样本的权重,又能控制难易分类样本的权重。

为每个类别学习一个中心,并将每个类别的所有特征向量拉向对应类别中心,联合Softmax一起使用
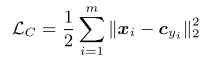
很简单,每个将输出点与这类中心点的距离累加作为损失。
回想方差公式:
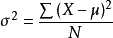
是不是很类似?降低center loss其实也可以看作是降低同类的方差。
anchor, positive, negative
没有使用softmax,以三元组(a, p, n)形式进行优化,不同类特征的L2距离要比同类特征的L2距离大margin m,同时获得类内紧凑和类间分离。
x表示类别,p(x)表示类别x的概率

- data augmentation
- center loss ?
- mobilenet v2
- attention mechanism is not very helpful
- cosine similarity instead of softmax in order to adapt new added class
- cluster multiple template images' feature in one class
def cross_entropy(predictions, targets, epsilon=1e-12):
"""
Computes cross entropy between targets (encoded as one-hot vectors)
and predictions.
Input: predictions (N, k) ndarray
targets (N, k) ndarray
Returns: scalar
"""
predictions = np.clip(predictions, epsilon, 1. - epsilon)
N = predictions.shape[0]
ce = -np.sum(targets*np.log(predictions+1e-9))/N
return ce
predictions = np.array([[0.25,0.25,0.25,0.25],
[0.01,0.01,0.01,0.96]])
targets = np.array([[0,0,0,1],
[0,0,0,1]])
ans = 0.71355817782 #Correct answer
x = cross_entropy(predictions, targets)
print(np.isclose(x,ans))
def IOU(A, B):
# A =[x,y,w,h]
x1,y1,x2,y2 = A[0],A[1],A[0]+A[2],A[1]+A[3]
x3,y3,x4,y4 = B[0],B[1],B[0]+B[2],B[1]+B[3]
W = min(x2,x4) - max(x1,x3)
H = min(y2,y4) - max(y1,y3)
if W <= 0 or H <= 0:
return 0
SA = A[2] * A[3]
SB = B[2] * B[3]
cross = W * H
return cross/(SA + SB - cross)
堆排序: 采用元素下沉法,维护一个k大小的最小堆,对于数组中的每一个元素判断与堆顶的大小,若堆顶较大,则不管,否则,弹出堆顶,将当前值插入到堆中,继续调整最小堆。时间复杂度O(n * logk)
https://blog.csdn.net/hongxingabc/article/details/78996407
def nms(dets, thresh):
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
order = scores.argsort()[::-1]
keep = []
while len(order) > 0:
i = order[0]
keep.append(i)
ious = get_iou([x1, y1,
x2, y2],
[x1[order[1:]], y1[order[1:]],
x2[order[1:]], y2[order[1:]]])
inds = np.where(ious <= thresh)[0]
order = order[inds+1] # ATTENTION: +1
return keep