| Function | Shortcut |
|---|---|
| New Tab | ⌘ + T |
| Close Tab or Window | ⌘ + W (same as many mac apps) |
| Go to Tab | ⌘ + Number Key (ie: ⌘2 is 2nd tab) |
| Go to Split Pane by Direction | ⌘ + Option + Arrow Key |
| Cycle iTerm Windows | ⌘ + backtick (true of all mac apps and works with desktops/mission control) |
Łukasz Latusik latusikl
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| //The global script scope | |
| def ctx = context(scope: scriptScope()) | |
| //What things can be on the script scope | |
| contributor(ctx) { | |
| method(name: 'pipeline', type: 'Object', params: [body: Closure]) | |
| property(name: 'params', type: 'org.jenkinsci.plugins.workflow.cps.ParamsVariable') | |
| property(name: 'env', type: 'org.jenkinsci.plugins.workflow.cps.EnvActionImpl.Binder') | |
| property(name: 'currentBuild', type: 'org.jenkinsci.plugins.workflow.cps.RunWrapperBinder') | |
| property(name: 'scm', type: 'org.jenkinsci.plugins.workflow.multibranch.SCMVar') |
Deepakdubey90
/ O'Reilly Free Books in PDF format
Last active
April 28, 2024 10:00
— forked from stripedpurple/O'Reilly Free Books
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| http://www.oreilly.com/data/free/files/2014-data-science-salary-survey.pdf | |
| http://www.oreilly.com/data/free/files/2015-data-science-salary-survey.pdf | |
| http://www.oreilly.com/data/free/files/Data_Analytics_in_Sports.pdf | |
| http://www.oreilly.com/data/free/files/advancing-procurement-analytics.pdf | |
| http://www.oreilly.com/data/free/files/ai-and-medicine.pdf | |
| http://www.oreilly.com/data/free/files/analyzing-data-in-the-internet-of-things.pdf | |
| http://www.oreilly.com/data/free/files/analyzing-the-analyzers.pdf | |
| http://www.oreilly.com/data/free/files/architecting-data-lakes.pdf | |
| http://www.oreilly.com/data/free/files/being-a-data-skeptic.pdf | |
| http://www.oreilly.com/data/free/files/big-data-analytics-emerging-architecture.pdf |
npearce
/ install-docker.md
Last active
June 5, 2024 20:07
Amazon Linux 2 - install docker & docker-compose using 'sudo amazon-linux-extras' command
UPDATE (March 2020, thanks @ic): I don't know the exact AMI version but yum install docker now works on the latest Amazon Linux 2. The instructions below may still be relevant depending on the vintage AMI you are using.
Amazon changed the install in Linux 2. One no-longer using 'yum' See: https://aws.amazon.com/amazon-linux-2/release-notes/
sudo amazon-linux-extras install docker
sudo service docker startPlantUML is a descriptive language to generate a number of types of software diagrams, such as sequence, class, deployment and state diagrams, and many others. PlantUML does not generate very good-looking schema diagrams out of the box, but it supports themes and preprocessed macros. If you use themes and macros, you can not only use a simplified syntax, but also generate beautiful diagrams.
Here is an example of a PlantUML schema diagram, and we will build up the code to generate it.
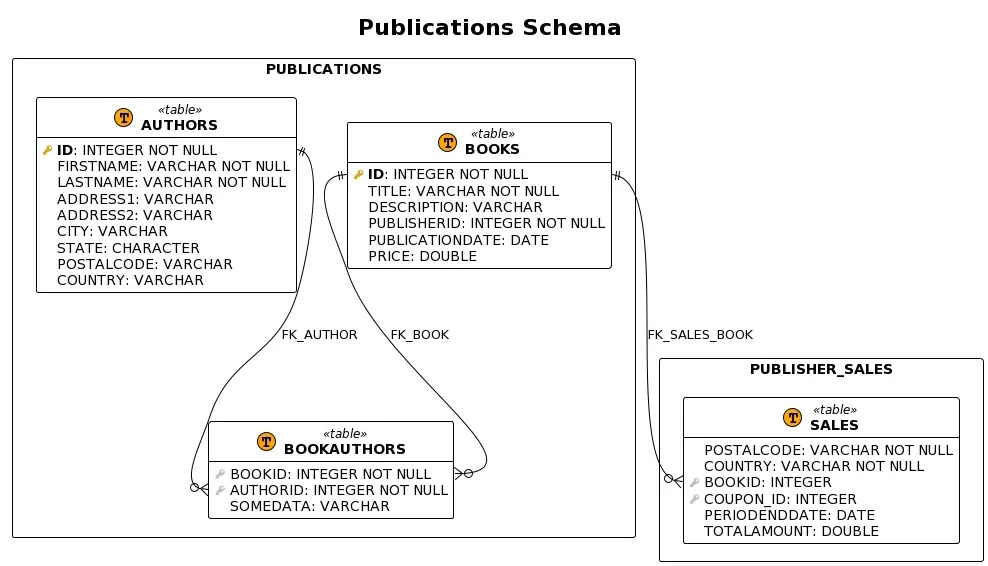
To start, describe your schemas, tables and columns using this syntax as an example.