In this article, I will share some of my experience on installing NVIDIA driver and CUDA on Linux OS. Here I mainly use Ubuntu as example. Comments for CentOS/Fedora are also provided as much as I can.
Pankesh Bamotra pbamotra
🎯
wangruohui
/ Install NVIDIA Driver and CUDA.md
Last active
May 17, 2024 09:02
Install NVIDIA Driver and CUDA on Ubuntu / CentOS / Fedora Linux OS
leonardofed
/ README.md
Last active
May 15, 2024 11:28
A curated list of AWS resources to prepare for the AWS Certifications
A curated list of AWS resources to prepare for the AWS Certifications
A curated list of awesome AWS resources you need to prepare for the all 5 AWS Certifications. This gist will include: open source repos, blogs & blogposts, ebooks, PDF, whitepapers, video courses, free lecture, slides, sample test and many other resources.
Table of Contents
entaroadun
/ gist:1653794
Created
January 21, 2012 20:10
Recommendation and Ratings Public Data Sets For Machine Learning
Movies Recommendation:
- MovieLens - Movie Recommendation Data Sets http://www.grouplens.org/node/73
- Yahoo! - Movie, Music, and Images Ratings Data Sets http://webscope.sandbox.yahoo.com/catalog.php?datatype=r
- Jester - Movie Ratings Data Sets (Collaborative Filtering Dataset) http://www.ieor.berkeley.edu/~goldberg/jester-data/
- Cornell University - Movie-review data for use in sentiment-analysis experiments http://www.cs.cornell.edu/people/pabo/movie-review-data/
Music Recommendation:
- Last.fm - Music Recommendation Data Sets http://www.dtic.upf.edu/~ocelma/MusicRecommendationDataset/index.html
IanColdwater
/ twittermute.txt
Last active
April 22, 2024 17:26
Here are some terms to mute on Twitter to clean your timeline up a bit.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Mute these words in your settings here: https://twitter.com/settings/muted_keywords | |
| ActivityTweet | |
| generic_activity_highlights | |
| generic_activity_momentsbreaking | |
| RankedOrganicTweet | |
| suggest_activity | |
| suggest_activity_feed | |
| suggest_activity_highlights | |
| suggest_activity_tweet |
tamuhey
/ tokenizations_post.md
Last active
March 30, 2024 19:00
How to calculate the alignment between BERT and spaCy tokens effectively and robustly
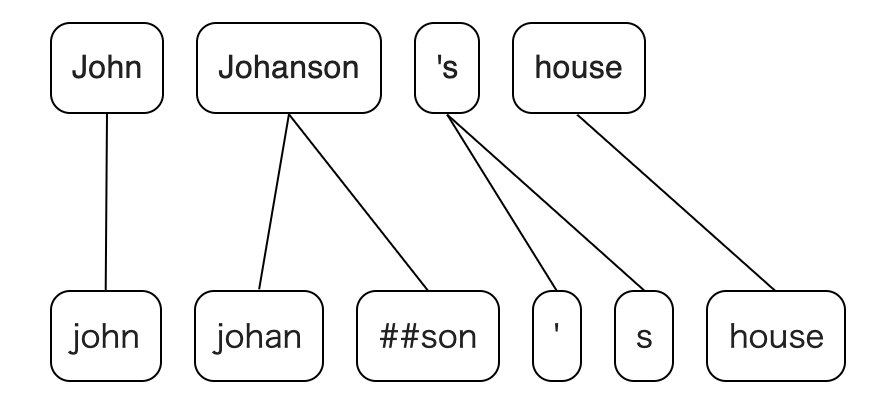
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links:
mattdesl
/ cli.js
Created
September 13, 2022 10:37
colour palette from text prompt using Stable Diffusion https://twitter.com/mattdesl/status/1569457645182152705
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| /** | |
| * General-purpose NodeJS CLI/API wrapping the Stable-Diffusion python scripts. | |
| * | |
| * Note that this uses an older fork of stable-diffusion | |
| * with the 'txt2img.py' script, and that script was modified to | |
| * support the --outfile command. | |
| */ | |
| var { spawn, exec } = require("child_process"); | |
| var path = require("path"); |
alxcnwy
/ rotate_bounding_box.py
Created
June 23, 2021 14:44
Rotate bounding box and get new bounding coords
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # answer to this reddit post: | |
| # https://www.reddit.com/r/learnmachinelearning/comments/o6br1e/calculate_bounding_box_coordinates_from_contour/ | |
| import numpy as np | |
| from numpy import sin, cos, sqrt, pi | |
| import math | |
| import matplotlib.pyplot as plt | |
| center = (332, 209) | |
| width = 56 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Lesson 1 SUMMARY | |
| 1. The cursor is moved using either the arrow keys or the hjkl keys. | |
| h (left) j (down) k (up) l (right) | |
| 2. To start Vim from the shell prompt type: vim FILENAME <ENTER> | |
| 3. To exit Vim type: <ESC> :q! <ENTER> to trash all changes. | |
| OR type: <ESC> :wq <ENTER> to save the changes. |
nasimrahaman
/ weighted_cross_entropy.py
Last active
November 16, 2023 04:54
Pytorch instance-wise weighted cross-entropy loss
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import torch | |
| import torch.nn as nn | |
| def log_sum_exp(x): | |
| # See implementation detail in | |
| # http://timvieira.github.io/blog/post/2014/02/11/exp-normalize-trick/ | |
| # b is a shift factor. see link. | |
| # x.size() = [N, C]: | |
| b, _ = torch.max(x, 1) |
NewerOlder