
Graphic courtesy of ICIJ
The Pandora Papers have rocked the world. News organisations began publishing their explosive contents on October 3, the giant leak has dominated headlines and posed questions of some of the world’s most powerful people and their financial propriety.
Some highlights:
- a 2.94 terabyte data trove
- from more than 200 countries and territories
- more than 330 politicians
- 130 Forbes billionaires, as well as celebrities, fraudsters, drug dealers, royal family members and leaders of religious groups around the world.
The Pandora Papers investigation is the world’s largest-ever journalistic collaboration, involving more than 600 journalists from 150 media outlets in 117 countries.
Here are some great articles:
- It news Asia: How new tech helped to expose the Pandora Papers leak
- Data Storage Asea: Connecting the Dots: How Graph Technology Made the Pandora Papers Possible
- Wired: How the secrets of the Pandora Papers were freed
- (Pandora Papers: An offshore data tsunami)[https://www.icij.org/investigations/pandora-papers/about-pandora-papers-leak-dataset/]
Not all the data has been made available yet - but some data is already there.
Here's Data model:
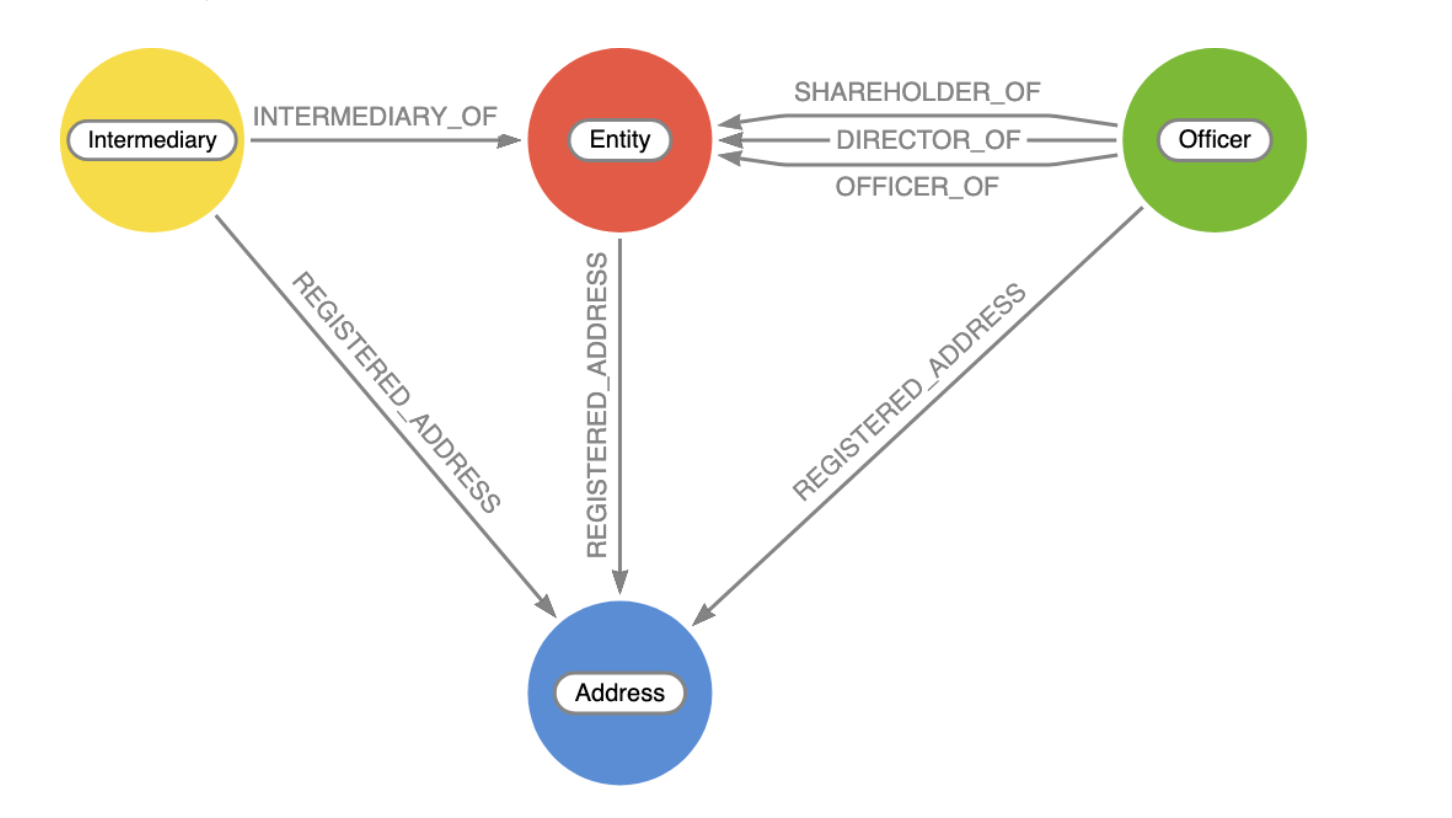
Our friend @Mesirii has also created a couple of nice elements that we can include: take a look at this Github page.
Here's the import statement:
// import nodes from JSON which is an array of nodes/edges for each power-player
CALL apoc.load.jsonArray("https://gist.githubusercontent.com/jexp/8afb65325bf99014c8de68a9511a549b/raw/pandora.json") yield value
WITH collect(value) as values
UNWIND range(0, size(values)-1) as set
WITH apoc.convert.toMap(values[set]) as value, set
UNWIND value.nodes as n
CALL apoc.merge.node(n.data.categories, {node_id: n.data.properties.node_id},n.data.properties) YIELD node
SET node.id=set+"-"+n.id
RETURN count(*);
CALL apoc.load.jsonArray("https://gist.githubusercontent.com/jexp/8afb65325bf99014c8de68a9511a549b/raw/pandora.json") yield value
WITH collect(value) as values
UNWIND range(0, size(values)-1) as set
WITH apoc.convert.toMap(values[set]) as value, set
UNWIND value.edges as e
MATCH (n) where n.id=set+"-"+e.source
MATCH (m) where m.id=set+"-"+e.target
CALL apoc.create.relationship(n, e.data.type,
apoc.map.clean(e.data.properties,["edge_id","power_player_profile_id"],[]) ,m) yield rel
RETURN count(*);
// merge duplicate entities by name
MATCH (e:Entity)
WITH e.name as name, collect(e) as nodes
WHERE size(nodes) > 1
CALL apoc.refactor.mergeNodes(nodes, {properties:"discard", mergeRels:true}) YIELD node return count(*);
CREATE INDEX on :Entity(name);
CREATE INDEX on :Officer(name);
CREATE INDEX on :Entity(provider);Some additional refactoring that I have found useful - basically pulling the properties out of the Officer and Entity nodes, and making them into their own Nodes that are then connected:
- Linking Entity to Country:
MATCH (n:Entity) MERGE (c:Country {name: coalesce(n.jurisdiction,"UNKNOWN")}) MERGE (n)-[:RESIDES_IN]->(c);
- Linking Officer to Country:
MATCH (o:Officer) MERGE (c:Country {name: coalesce(o.country, "UNKNOWN")}) MERGE (o)-[:CITIZEN_OF]->(c);
- Linking Entities to data Providers:
MATCH (n:Entity) MERGE (p:Provider {name: coalesce(n.provider,"UNKNOWN")}) MERGE (n)-[:PROVIDED_BY]->(p);
MATCH (n:Entity)
RETURN distinct n.jurisdiction, count(n);MATCH (o:Officer)-[rel]->(e:Entity)
WHERE e.jurisdiction CONTAINS “British Virgin Islands”
RETURN o, rel, e;MATCH (e:Entity) return e.provider, count(*) as c order by c desc;MATCH (e:Entity) return e.jurisdiction, count(*) as c order by c desc;MATCH (c1:Country)<--(o:Officer)-->(e:Entity)--(c2:Country)
WITH distinct c1.name as OfficerCountry, c2.name as EntityCountry, count(*) as PatternFrequency
WHERE PatternFrequency >= 5
RETURN OfficerCountry, EntityCountry, PatternFrequency
ORDER BY PatternFrequency desc;MATCH (o:Officer)-->(e:Entity)
WHERE toLower(o.name) CONTAINS 'aliyev'
RETURN *;MATCH (o:Officer)-[*..2]->(conn)
WHERE o.name contains "Blair"
RETURN *;Clearly there's a lot more to come here, and I know that I will be eagerly looking out for more details from our heroes at the ICIJ.
Stay tuned!